目录
前言
一、赛题介绍
二、数据清洗、特征构建、特征可视化
1.数据缺失值及重复值处理
2.日期分离,PV及UV构建
3.PV及UV可视化
4.用户行为可视化
4.1 各个行为的面积图(以UV为例)
4.2 各个行为的热力图
5.转化率可视化
三、RFM模型
1.构建R、F、M
2.RFM的数据统计分布
3.计算RFM得分及组合
4.RFM组合柱图及得分饼图可视化
5.RFM 3D柱图展示
四、商品类型关联分析
4.1.提取关联规则
4.2.商品关联规则关系图
4.3.商品词云图
前言
赛事数据集有1千多万,4个特征,本人主要是从RFM客户群分及商品关联分析对数据集进行分析及可视化,除了用到基本的Matplotlib进行可视化,还用到pyecharts进行可视化,对于喜欢用Python处理大数据的朋友来说,试一次不错的锻炼。本次赛事的参考Baseline:淘宝用户购物行为数据可视化分析baseline_天池notebook-阿里云天池
一、赛题介绍
2014年是阿里巴巴集团移动电商业务快速发展的一年,例如2014双11大促中移动端成交占比达到42.6%,超过240亿元。相比PC时代,移动端网络的访问是随时随地的,具有更丰富的场景数据,比如用户的位置信息、用户访问的时间规律等。
本次可视化分析的目的是针对脱敏过的用户行为数据(包括浏览、收藏、加购和购买4类数据)进行分析,使用Python、Numpy、Pandas和Matplotlib工具完成可视化分析,帮助选手更好的理解数据,并作出商业洞察。
本次分析数据提供了1万用户量级的完整行为数据:user_action.csv,为了简化问题相比原数据集,我们去掉了user_geohash这个大部分情况为空的字段。
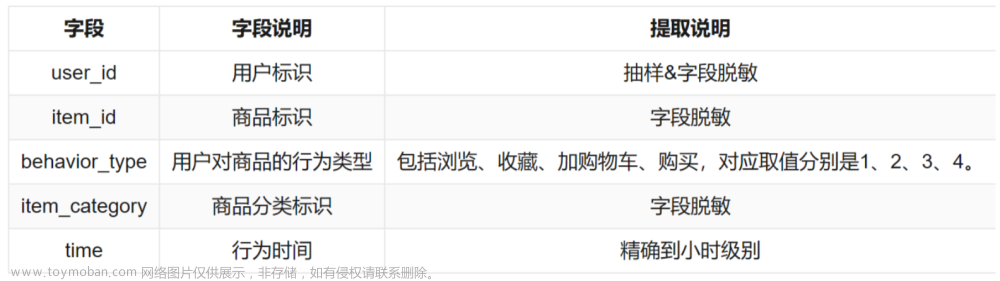
| 字段 | 字段说明 | 提取说明 |
|---|---|---|
| user_id | 用户标识 | 抽样&字段脱敏 |
| item_id | 商品标识 | 字段脱敏 |
| behavior_type | 用户对商品的行为类型 | 包括浏览、收藏、加购物车、购买,对应取值分别是1、2、3、4。 |
| item_category | 商品分类标识 | 字段脱敏 |
| time | 行为时间 | 精确到小时级别 |
注:数据包含了抽样出来的1W用户在一个月时间(11.18~12.18)之内的移动端行为数据。相比算法挑战赛,本次可视化分析任务移除了user_geohash字段,同时为了计算方便,在数据量级上也从算法挑战赛原始的100W用户行为数据缩减为1W规模。
二、数据清洗、特征构建、特征可视化
1.数据缺失值及重复值处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
from pyecharts import options as opts
from pyecharts.charts import Bar3D,Bar,Pie,Funnel,Line
df = pd.read_csv('/user_action.csv')
df.shape
# (12256906, 5)
# 一千多万的数据df.isnull().sum() # 缺失值查看
# 本次数据无缺失值
print(df.duplicated().sum()) # 判断重复值
df.drop_duplicates(keep='first',inplace = True) # 去重
print(df.shape)
# 6043527 重复值有600多万
# (6213379, 5) 去重后剩下600多万的数据2.日期分离,PV及UV构建
df['date'] = df['time'].map(lambda x: x.split(' ')[0])
df['hour'] =df['time'].map(lambda x: x.split(' ')[1])
df.loc[:,'data_now']='2014-12-20' # 为了RFN模型的R构建的特征
df.head()
访问量(PV):全名为Page View, 基于用户每次对淘宝页面的刷新次数,用户每刷新一次页面或者打开新的页面就记录就算一次访问。
独立访问量(UV):全名为Unique Visitor,一个用户若多次访问淘宝只记录一次,熟悉SQL的小伙伴会知道,本质上是unique操作。
pv_daily = df.groupby('date')['user_id'].count()
pv_daily = pv_daily.reset_index()
pv_daily = pv_daily.rename(columns={'user_id':'pv_daily'})
pv_hour = df.groupby('hour')['user_id'].count()
pv_hour = pv_hour.reset_index()
pv_hour = pv_hour.rename(columns={'user_id':'pv_hour'})
uv_daily = df.groupby('date')['user_id'].apply(lambda x: len(x.unique()))
uv_daily = uv_daily.reset_index()
uv_daily = uv_daily.rename(columns = {'user_id':'uv_daily'})
uv_hour = df.groupby('hour')['user_id'].apply(lambda x: len(x.unique()))
uv_hour = uv_hour.reset_index()
uv_hour = uv_hour.rename(columns={'user_id':'uv_hour'})3.PV及UV可视化
import matplotlib.dates as mdates
plt.figure(figsize=(14,10))
sns.set_style('dark')
plt.subplot(2, 2, 1)
ax=sns.lineplot(x='date',y='pv_daily',data=pv_daily)
plt.xticks(rotation=45,horizontalalignment='right',fontweight='light')
locator = mdates.DayLocator(interval=3) # 每隔3天显示日期
ax.xaxis.set_major_locator(locator)
plt.title('pv_daily')
plt.subplot(2, 2, 2)
ax1=sns.lineplot(x='date',y='uv_daily',data=uv_daily)
plt.title('uv_daily')
plt.xticks(rotation=45,horizontalalignment='right',fontweight='light')
ax1.xaxis.set_major_locator(locator)
plt.subplot(2, 2, 3)
ax2=sns.lineplot(x='hour',y='pv_hour',data=pv_hour)
plt.title('pv_hour')
locator1 = mdates.DayLocator(interval=3)
ax2.xaxis.set_major_locator(locator1)
plt.subplot(2, 2, 4)
ax3=sns.lineplot(x='hour',y='uv_hour',data=uv_hour)
plt.title('uv_hour')
ax3.xaxis.set_major_locator(locator1)
plt.subplots_adjust(wspace=0.4,hspace=0.8) # 调整图间距
plt.show()
PV及UV在双十二达到一个峰值,同时在凌晨3-6点达到低谷,同时也可以把双十二当天的数据单独提出来可视化看一下流量在每个时间点的分布是否有不同。
4.用户行为可视化
4.1 各个行为的面积图(以UV为例)
behavior = df.groupby(['behavior_type','date'])['user_id'].apply(lambda x: len(x.unique()))
behavior = behavior.reset_index()
behavior = behavior.rename(columns = {'user_id':'uv'})
behavior1=behavior[behavior['behavior_type']==1].rename(columns = {'uv':'浏览'})
behavior2=behavior[behavior['behavior_type']==2].reset_index().rename(columns = {'uv':'收藏'})
behavior3=behavior[behavior['behavior_type']==3].reset_index().rename(columns = {'uv':'加购'})
behavior4=behavior[behavior['behavior_type']==4].reset_index().rename(columns = {'uv':'购买'})
result = pd.concat([behavior1, behavior2,behavior3,behavior4], axis=1)
result =result.loc[:,~result.columns.duplicated()] #删除同名列,保留前面一项
result = result.drop(labels=['behavior_type','index'], axis=1)
result.head()
# 面积图
x = behavior1['date'].values.tolist()
y1 = behavior1['浏览'].values.tolist()
y2 = behavior2['收藏'].values.tolist()
y3 = behavior3['加购'].values.tolist()
y4 = behavior4['购买'].values.tolist()
c = (
Line()
.add_xaxis(x)
.add_yaxis("浏览", y1, is_smooth=True)
.add_yaxis("收藏", y2, is_smooth=True)
.add_yaxis("加购", y3, is_smooth=True)
.add_yaxis("购买", y4, is_smooth=True)
.set_series_opts(
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="各个行为UV面积图"),
xaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_align_with_label=True),
is_scale=False,
boundary_gap=True,
),
)
)
c.render_notebook()
可以看到双十二有一个明显的峰值,pyecharts的好处就是可以绘制交互式的图形,你可以点击你想看的数据来进行单独显示。
4.2 各个行为的热力图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
correlation_matrix=result.corr()
plt.figure(figsize=(8,6))
sns.heatmap(correlation_matrix,vmax=0.9,linewidths=0.05,cmap="GnBu_r",annot=True,annot_kws={'size': 15})
plt.title("uv", fontsize = 20)
基本上都是强相关,但是搜藏和购买的相关性相对其余的来说偏低,毕竟搜藏后还会货比三家嘛
5.转化率可视化
behavior_type = df.groupby(['behavior_type'])['user_id'].count()
click_num, fav_num, add_num, pay_num = behavior_type[1], behavior_type[2], behavior_type[3], behavior_type[4]
fav_add_num = fav_num + add_num
behavior_type1=pd.DataFrame([click_num, fav_add_num, pay_num],index=["浏览", "收藏+加购", "购买"],columns=["A"])
behavior_type1['B']=(100*behavior_type1['A']/5535879).round(2)
# 漏斗图
x = ["浏览", "收藏+加购", "购买"]
y = behavior_type1['B'].values.tolist()
c = (
Funnel()
.add("",[list(z) for z in zip(x,y)])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}占比{c}%"))
.set_global_opts(title_opts=opts.TitleOpts(title="转化率"))
)
c.render_notebook()
整体的转化率从浏览到购买是不到2%,双十二当天是4.65%
三、RFM模型
由于本次数据集没有商品价格,所以换了个思路构建。
R:数据集最后日期延迟两天的日期作为基准,构建该指标。
F:通过筛选客户ID在数据集的日期中发生购买行为的天数作为频次。
M:客户购买的商品数。
1.构建R、F、M
df1=df[df['behavior_type']==4] # 取出已成交的数据
df1['day']=(pd.to_datetime(df1['data_now'])- pd.to_datetime(df1['date'])).apply(lambda x : x.days)
data_r = df1.groupby(['user_id'])['day'].agg('min').reset_index().rename(columns = {'day':'R'})
data_f = df1.groupby(['user_id'])['date'].apply(lambda x: len(x.unique())).reset_index().rename(columns = {'date':'F'})
data_m = df1.groupby(['user_id'])['item_id'].count().reset_index().rename(columns = {'item_id':'M'})
RFM= pd.concat([data_r,data_f,data_m], axis=1)
RFM =RFM.loc[:,~RFM.columns.duplicated()]2.RFM的数据统计分布
RFM.describe().T
3.计算RFM得分及组合
# 定义区间边界
r_bins = [0,3,9,32] # 注意起始边界小于最小值
f_bins = [0,2,8,30]
m_bins = [0,4,15,745]
# RFM分箱得分
RFM['r_score'] = pd.cut(RFM['R'], r_bins, labels=[i for i in range(len(r_bins)-1,0,-1)]) # 计算R得分 倒序排列
RFM['f_score'] = pd.cut(RFM['F'], f_bins, labels=[i+1 for i in range(len(f_bins)-1)]) # 计算F得分
RFM['m_score'] = pd.cut(RFM['M'], m_bins, labels=[i+1 for i in range(len(m_bins)-1)]) # 计算M得分
# 方法1:计算RFM总得分
RFM[['r_score','f_score','m_score']] = RFM[['r_score','f_score','m_score']].apply(np.int32)
RFM['rfm_score'] = RFM['r_score'] + RFM['f_score'] + RFM['m_score']
# 方法2:RFM组合
RFM=RFM.applymap(str)
RFM['rfm_group']=RFM['r_score']+RFM['f_score']+RFM['m_score']
RFM.head()
这里的R是按照倒序区分,即购买日期越近,分值越大。
4.RFM组合柱图及得分饼图可视化
#柱图
RFM_new = RFM.groupby(['rfm_group','rfm_score'])['user_id'].count().reset_index().rename(columns = {'user_id':'number'})
RFM_new = RFM_new.rename_axis('index').reset_index()
l1=RFM_new['rfm_group'].values.tolist()
l2=RFM_new['number'].values.tolist()
c = Bar({"theme": ThemeType.DARK}) # 背景主题
c.add_xaxis(l1)
c.add_yaxis("类别数量", l2)
c.set_global_opts(title_opts=opts.TitleOpts(title="RFM类别数量"),
yaxis_opts=opts.AxisOpts(name="数量"),
xaxis_opts=opts.AxisOpts(name="组别"))
c.render_notebook()
#饼图
RFM_score=RFM_new.groupby(['rfm_score'])['number'].sum().reset_index() # 组别占比
RFM_score['score_pt']=(RFM_score['number']/RFM_score['number'].sum()).round(2)
x_data = RFM_score['rfm_score'].values.tolist()
y_data = RFM_score['score_pt'].values.tolist()
c = (
Pie()
.add(
"",
[list(z) for z in zip(x_data, y_data)],
radius=["30%", "75%"],
center=["50%", "50%"],
rosetype="radius",
is_clockwise=True,
label_opts=opts.LabelOpts(is_show=True),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}占比{d}%"))
.set_global_opts(title_opts=opts.TitleOpts(title="类别占比"))
)
c.render_notebook()

组别上222及111的组别占比较高,但333高价值组别也不少。分值上6分的类别占比达到24%,是最高。各个指标分值为1的为低,2表示一般,3表示高,比如111就代表低价值客户群体,当然具体分群的指标还得根据具体的场景定义。下面提供一个关于组别客户分群的参考

5.RFM 3D柱图展示
data=RFM_new.values.tolist()
group = list(set(RFM_new.iloc[:, 1]))
score = list(set(RFM_new.iloc[:, 2]))
data2 = [[d[1], d[2], d[3]] for d in data]
(
Bar3D(init_opts=opts.InitOpts(width="1000px", height="600px"))
.add(
series_name="",
data=data2,
xaxis3d_opts=opts.Axis3DOpts(type_="category", data=group,name='group'),
yaxis3d_opts=opts.Axis3DOpts(type_="category", data=score,name='score'),
zaxis3d_opts=opts.Axis3DOpts(type_="value",name='number'),
)
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(
max_=1500,
range_color=[
"#313695",
"#4575b4",
"#74add1",
"#abd9e9",
"#e0f3f8",
"#ffffbf",
"#fee090",
"#fdae61",
"#f46d43",
"#d73027",
"#a50026",
],
),
title_opts=opts.TitleOpts(title="RFM客户分群3D可视化") # 设置总标题
)
.render_notebook()
) 

这个图的好处就是可以360度旋转查看各个数据信息,pyecharts的交互性在这就体现得很好
四、商品类型关联分析
4.1.提取关联规则
Support(支持度):表示同时包含A和B的事务占所有事务的比例。如果用P(A)表示使用A事务的比例,那么Support=P(A&B),就是两者同时出现的次数与总次数的比例
Confidence(可信度):表示使用包含A的事务中同时包含B事务的比例,即同时包含A和B的事务占包含A事务的比例。公式表达:Confidence=P(A&B)/P(A)
Lift(提升度):表示“包含A的事务中同时包含B事务的比例”与“包含B事务的比例”的比值。公式表达:Lift=( P(A&B)/P(A))/P(B)=P(A&B)/P(A)/P(B)。
提升度反映了关联规则中的A与B的相关性,提升度>1且越高表明正相关性越高,提升度<1且越低表明负相关性越高,提升度=1表明没有相关性。
这三个概念的详细计算可以参考:关联分析中的支持度、置信度和提升度_sanqima的博客-CSDN博客
import apriori # 导入关联算法
order_ids = pd.unique(df1['user_id'])
order_records = [df1[df1['user_id']==each_id]['item_category'].tolist() for each_id in order_ids]
minS = 0.01 # 定义最小支持度阀值
minC = 0.1 # 定义最小置信度阀值
L, suppData = apriori.apriori(order_records, minSupport=minS) # 计算得到满足最小支持度的规则
rules = apriori.generateRules(order_records, L, suppData, minConf=minC)
model_summary = 'data record: {1} \nassociation rules count: {0}' # 展示数据集记录数和满足阀值定义的规则数量
print(model_summary.format(len(rules), len(order_records)),'\n','-'*60) # 使用str.format做格式化输出
rules_all = pd.DataFrame(rules, columns=['item1', 'item2', 'instance', 'support', 'confidence',
'lift']) # 创建频繁规则数据框
rules_sort = rules_all.sort_values(['lift'],ascending=False)
print(rules_sort[:20])
可以看到有177条满足设定的规则,这里按照提升度进行倒序排列,并展示前20条。其中商品类别10661与9516的置信度0.5082,提升度10.2168,是一条有效的强关联规则。
4.2.商品关联规则关系图
这里只提取数量排名前十的商品进行可视化,用到的是networkx库
rules_sort_filt=rules_sort[rules_sort['lift']>2] #筛选提升度大于2的规则
# 汇总每个item出现的次数
display_data=rules_sort_filt.iloc[:,:3]
item1=display_data[['item1','instance']].rename(index=str,columns={"item1":"item"})
item2=display_data[['item2','instance']].rename(index=str,columns={"item2":"item"})
item_concat=pd.concat((item1,item2),axis=0)
item_count=item_concat.groupby(['item'])['instance'].sum()
# 取出规则最多的TOP N items
control_num = 10
top_n_rules = item_count.sort_values(ascending=False).iloc[:control_num]
top_n_items = top_n_rules.index # 对应的就是每个类别项
top_rule_list = [all((item1 in top_n_items, item2 in top_n_items)) for item1,item2 in zip(display_data['item1'],display_data['item2'])] #all函数进行布尔筛选
top_display_data = display_data[top_rule_list]
# 取出前十商品ID
top10=top_n_rules.index
top101=[list(x) for x in top10] #二维
n = np.array(top101).flatten() # 转一维
# 由于item1及item2都是集合形式,这里进行转化
lst=[]
lst1=[]
for y,z in zip(top_display_data['item1'],top_display_data['item2']):
lst.append(list(y))
lst1.append(list(z))
n1 = np.array(lst).flatten()
n2 = np.array(lst1).flatten()
n1=pd.DataFrame(n1, columns=['item3'])
n2=pd.DataFrame(n2, columns=['item4'])
n3=pd.DataFrame(top_display_data['instance'].values.tolist(), columns=['instance'])
n4=pd.concat((n1,n2,n3),axis=1)
n4
绘图之前构建好的DataFrame
import networkx as nx
plt.figure(figsize=(14,10))
res = n4.values.tolist()
for i in range(len(res)):
res[i][2] = dict({'weight': res[i][2]})
res = [tuple(x) for x in res]
g = nx.Graph()
g.add_nodes_from(n)
g.add_edges_from(res)
pos = nx.spring_layout(g)
nx.draw(g,pos,node_color='#7FFF00', node_size=1500, alpha=0.6,with_labels=True)
labels = nx.get_edge_attributes(g,'weight')
nx.draw_networkx_edge_labels(g,pos,edge_labels=labels)
plt.show()
这个关系图是随机排列的,所以你每一次的显示图形会不一样,但数据不会变化,每个数字代表两个商品类别关联出现的次数
4.3.商品词云图
由于分组聚合后的商品ID数量有9万多条,所以只取排序后最多的前30条进行词云展示
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
buy=df1.groupby(['item_id'])['user_id'].count().reset_index().sort_values(by=['user_id'],ascending=False)
buy_freq=buy.head(30).values.tolist()
# 绘图
c = (
WordCloud()
.add("", buy_freq, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="商品词云图"))
)
c.render_notebook()
可以看到购买最多的商品ID:167074648
总结文章来源:https://www.toymoban.com/news/detail-814987.html
本次可视化更多的使用了pyecharts,它可以绘制交互式图形,这是matplotlib不能实现的,这些展示图也只是pyecharts的冰山一角,有兴趣的朋友可以参考官网学习,当然具体的数据可视化还是要根据具体的场景来选用合适的工具。文章来源地址https://www.toymoban.com/news/detail-814987.html
到了这里,关于天池赛:淘宝用户购物行为数据可视化分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!