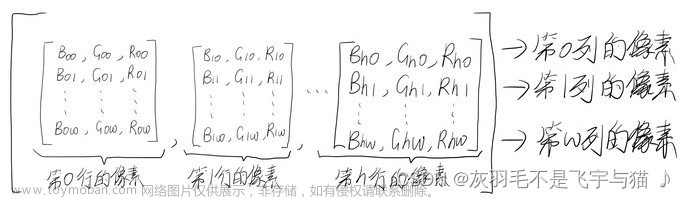
图像分类是计算机视觉领域中的一个重要任务。它的目的是将输入的图像归类到预定义的类别中。这个任务在过去被认为是非常具有挑战性的,因为图像的特征非常复杂,而且存在很多种不同的变化方式,例如光照、角度、遮挡等等。
然而,随着深度学习的发展,图像分类问题已经得到了显著的改善。深度学习模型可以自动地从大量的数据中学习到特征表示,并且能够处理高维度数据的非线性关系,这使得对于复杂的图像分类问题更加容易解决。
在深度学习中,卷积神经网络(Convolutional Neural Networks,CNN)是最流行的图像分类方法之一。CNN通过将输入图像的像素视为一个二维矩阵,并通过卷积层和池化层来提取图像的特征。然后,这些特征被输入到全连接层中进行分类。
除了CNN之外,还有其他的深度学习方法可以用于图像分类,比如循环神经网络(Recurrent Neural Networks,RNN)、残差网络(Residual Networks,ResNet)等等。这些方法都可以根据实际的需求来选择使用。
总之,深度学习技术已经在图像分类领域取得了很大的成功。通过深度学习方法,我们可以训练出高效准确的模型来解决复杂的图像分类问题。
数据处理
图像二分类涉及到数据的处理,需要将图像转换为计算机可以识别的数字格式。通常使用的方法是将每个图像转换为一个多维数组,每个像素点的值代表该像素点的颜色强度。对于彩色图像,通常有三个通道(红色、绿色、蓝色),因此对于每个像素点,需要有三个值来表示它的颜色。

from torchvision import transforms
# 定义数据预处理的操作
data_transforms = {
'train': transforms.Compose([
# 针对训练集的数据预处理操作
transforms.RandomResizedCrop(224), # 随机裁剪并调整大小为 224x224 像素
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转换为张量格式
# 对图像进行标准化,使用均值 [0.485, 0.456, 0.406] 和标准差 [0.229, 0.224, 0.225]
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
# 针对验证集的数据预处理操作
transforms.Resize(256), # 调整图像大小为 256x256 像素
transforms.CenterCrop(224), # 中心裁剪为 224x224 像素
transforms.ToTensor(), # 转换为张量格式
# 对图像进行标准化,使用均值 [0.485, 0.456, 0.406] 和标准差 [0.229, 0.224, 0.225]
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
# 针对测试集的数据预处理操作(通常与验证集相似)
transforms.Resize(256), # 调整图像大小为 256x256 像素
transforms.CenterCrop(224), # 中心裁剪为 224x224 像素
transforms.ToTensor(), # 转换为张量格式
# 对图像进行标准化,使用均值 [0.485, 0.456, 0.406] 和标准差 [0.229, 0.224, 0.225]
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
数据布置
在图像二分类中,通常会将数据集分为训练集和测试集。训练集用于训练模型,测试集用于评估模型性能。数据集应该按照一定比例划分成两个部分。常见的比例是将数据集的80%用于训练,20%用于测试。此外,还需要将数据标记为正样本或负样本,以便进行监督学习。
- img (主文件夹)
- train (训练数据子文件夹)
- 猫 (猫类别的训练样本)
- cat1.jpg
- cat2.jpg
- ...
- 狗 (狗类别的训练样本)
- dog1.jpg
- dog2.jpg
- ...
- 兔子 (兔子类别的训练样本)
- rabbit1.jpg
- rabbit2.jpg
- ...
- val (验证数据子文件夹)
- 猫 (猫类别的验证样本)
- cat101.jpg
- cat102.jpg
- ...
- 狗 (狗类别的验证样本)
- dog101.jpg
- dog102.jpg
- ...
- 兔子 (兔子类别的验证样本)
- rabbit101.jpg
- rabbit102.jpg
- ...
训练
使用深度学习框架,如Keras或PyTorch,可以方便地调用现有的图像分类模型进行训练。
-
在训练模型之前,需要设置模型架构、超参数、损失函数和优化器等。可以使用GPU进行加速,以缩短训练时间。
-
训练过程通常需要反复调整模型和超参数,以获得更好的性能。
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
保存权重
训练完成后,应该保存模型的权重。这些权重包含了模型所学习到的知识,可以在之后用于推理预测或者继续进行训练。可以使用深度学习框架提供的API将模型权重保存到硬盘上。
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
torch.save(model_ft,'model1.pth')

推理预测
通过加载之前保存的权重,可以使用模型进行推理预测。对于新的图像,需要将其转换为多维数组的形式,并传递给模型进行预测。

预测结果通常是一个概率值,表示该图像属于正样本的概率。可以设置阈值来确定判断标准,如当概率值大于0.5时,将其视为正样本。
import torchvision
#from model import Tudui
import torch
from PIL import Image
img_pth="qua_2.jpg"
true_label=img_pth
# 读取图像
img = Image.open(img_pth)
# 数据预处理
# 缩放
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(img)
print(image.shape)
# 根据保存方式加载
model = torch.load("model.pth", map_location=torch.device('cpu'))
# 注意维度转换,单张图片
image1 = torch.reshape(image, (1, 3, 32, 32))
# 测试开关
model.eval()
# 节约性能
with torch.no_grad():
output = model(image1)
_, preds = torch.max(output, 1)
print(output)
# print(output.argmax(1))
# 定义类别对应字典
dist = {0: "不合格", 1: "合格"}
# 转numpy格式,列表内取第一个
#a = dist[output.argmax(1).numpy()[0]]
a = dist[preds.numpy()[0]]
# img.show()
print(a)
print("input_label:",true_label)
全部代码
训练部分:
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
import pandas as pd
cudnn.benchmark = True
plt.ion() # interactive mode
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data'#####################修改输入路径
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val', 'test']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val', 'test']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val', 'test']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:4f}')
torch.save(best_model_wts,'class.pth')
# load best model weights
model.load_state_dict(best_model_wts)
return model
def getFileList(path):
for dirpath, dirnames, filenames in os.walk('.'):
for filename in filenames:
print(os.path.join(dirpath, filename))
return filepath
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
# fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title(f'predicted: {class_names[preds[j]]}')
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
model_ft = models.resnet18(pretrained=True)
#torch.save(model_ft,'zsl_class')
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
torch.save(model_ft,'model1.pth')
test_model(model_ft)
visualize_model(model_ft)
记得修改这个路径
data_dir = 'data'
修改输入路径
记得保存权重
torch.save(model_ft,'model1.pth')
任意起名字 model.pth为对象
预测
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
import torchvision
#from model import Tudui
import torch
from PIL import Image
img_pth="qua_2.jpg"
true_label=img_pth
# 读取图像
img = Image.open(img_pth)
# 数据预处理
# 缩放
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(img)
print(image.shape)
# 根据保存方式加载
model = torch.load("model.pth", map_location=torch.device('cpu'))
# 注意维度转换,单张图片
image1 = torch.reshape(image, (1, 3, 32, 32))
# 测试开关
model.eval()
# 节约性能
with torch.no_grad():
output = model(image1)
_, preds = torch.max(output, 1)
print(output)
# print(output.argmax(1))
# 定义类别对应字典
dist = {0: "不合格", 1: "合格"}
# 转numpy格式,列表内取第一个
#a = dist[output.argmax(1).numpy()[0]]
a = dist[preds.numpy()[0]]
# img.show()
print(a)
print("input_label:",true_label)
总结
当进行图像二分类任务时,以下是一些需要注意的要点:
数据集准备:
确保你有一个标注好的数据集,其中每个图像都被正确地标记为两个类别中的一个。
确保数据集中的类别平衡,即每个类别中的样本数量大致相等。
数据预处理:
进行适当的数据预处理操作,例如调整图像大小、裁剪、归一化等。
使用相同的数据预处理操作来处理训练
grad():
output = model(image1)
_, preds = torch.max(output, 1)
print(output)
print(output.argmax(1))
定义类别对应字典
dist = {0: “不合格”, 1: “合格”}
转numpy格式,列表内取第一个
#a = dist[output.argmax(1).numpy()[0]]
a = dist[preds.numpy()[0]]
img.show()
print(a)
print(“input_label:”,true_label)文章来源:https://www.toymoban.com/news/detail-815004.html
## 总结
当进行图像二分类任务时,以下是一些需要注意的要点:
1. 数据集准备:
- 确保你有一个标注好的数据集,其中每个图像都被正确地标记为两个类别中的一个。
- 确保数据集中的类别平衡,即每个类别中的样本数量大致相等。
2. 数据预处理:
- 进行适当的数据预处理操作,例如调整图像大小、裁剪、归一化等。
- 使用相同的数据预处理操作来处理训练
 文章来源地址https://www.toymoban.com/news/detail-815004.html
文章来源地址https://www.toymoban.com/news/detail-815004.html
到了这里,关于图像分类保姆级教程-深度学习入门教程(附代码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!