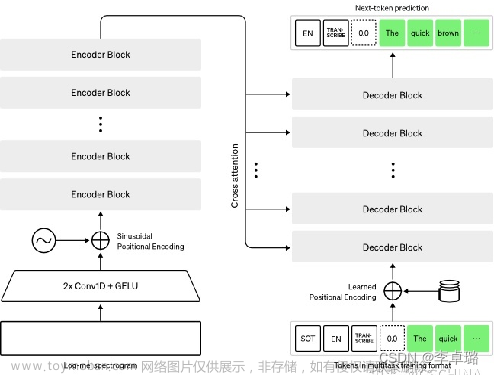
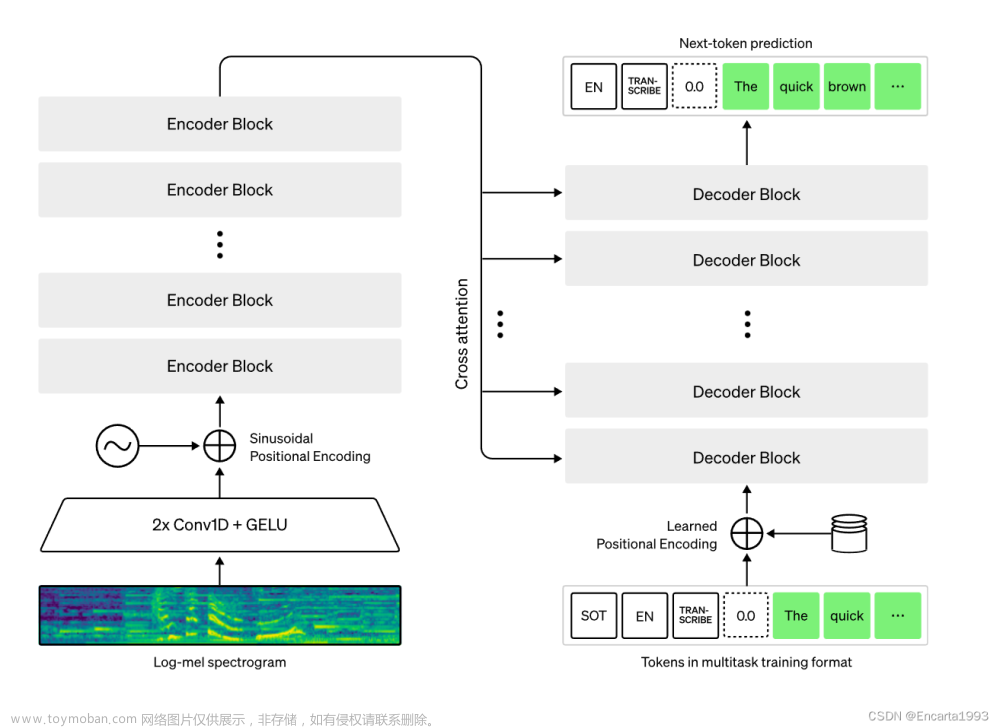
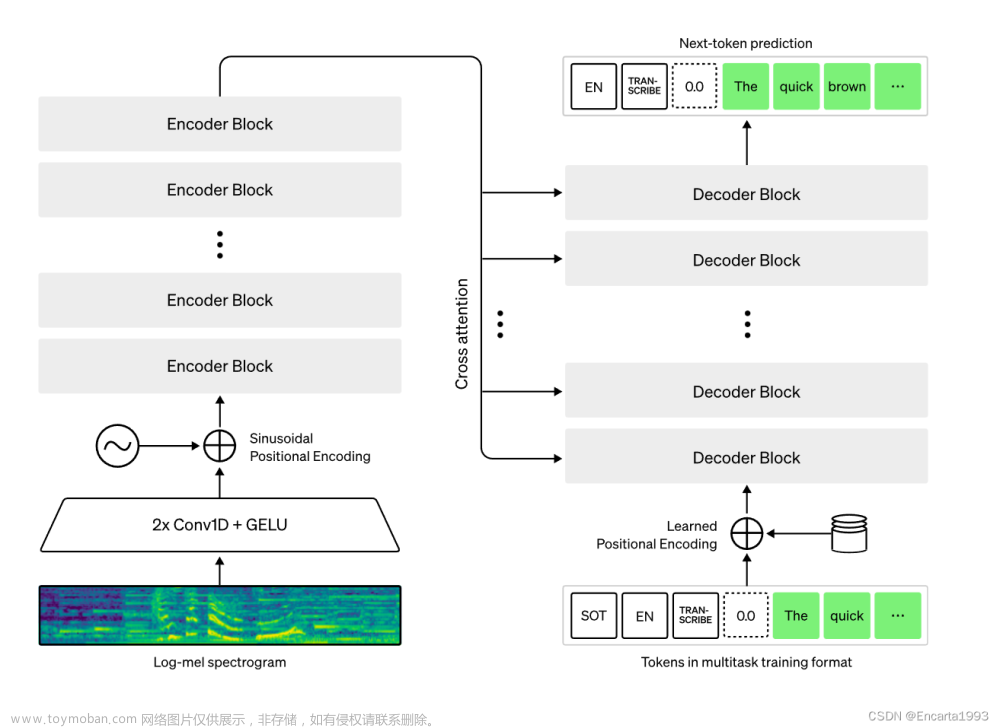
- whisper:https://github.com/openai/whisper/tree/main
参考文章:Whisper OpenAI开源语音识别模型
环境配置
pip install faster-whisper transformers
准备tiny模型
需要其他版本的可以自己下载:https://huggingface.co/openai文章来源地址https://www.toymoban.com/news/detail-815036.html
- 原始中文语音模型:
https://huggingface.co/openai/whisper-tiny
- 微调后的中文语音模型:
git clone https://huggingface.co/xmzhu/whisper-tiny-zh
- 补下一个:
tokenizer.json
https://huggingface.co/openai/whisper-tiny/resolve/main/tokenizer.json?download=true
模型转换
-
float16:
ct2-transformers-converter --model whisper-tiny-zh/ --output_dir whisper-tiny-zh-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16
-
int8:
ct2-transformers-converter --model whisper-tiny-zh/ --output_dir whisper-tiny-zh-ct2-int8 --copy_files tokenizer.json preprocessor_config.json --quantization int8
代码
from faster_whisper import WhisperModel
# model_size = "whisper-tiny-zh-ct2"
# model_size = "whisper-tiny-zh-ct2-int8"
# Run on GPU with FP16
# model = WhisperModel(model_size, device="cuda", compute_type="float16")
model = WhisperModel(model_size, device="cpu", compute_type="int8")
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# or run on CPU with INT8
# model = WhisperModel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe("output_file.wav", beam_size=5, language='zh')
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
文章来源:https://www.toymoban.com/news/detail-815036.html
到了这里,关于Whisper——部署fast-whisper中文语音识别模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!