第七章 备份与恢复
为保证在服务器宕机、磁盘损坏、RAID卡损坏等意外情况下,数据不丢失,或者最小程度的丢失,每个DBA应该时刻关注数据库备份情况。
MySQL数据库提供了大多数工具(如mysqldump,ibbackup,replication)都能很好的完成备份工作,当然也可以通过第三方工具完成,如xtrabacup,LVM快照备份等。需要根据自己业务需求,设计出损失最小,对数据库影响最小的备份策略。
1 备份与恢复概述
可以根据不同的类型来划分备份的方法。根据备份方法不同可以分为:
-
Hot Backup(热备)
热备是指数据库运行中直接备份,对正常运行的数据库没有任何影响,官方也可以称为在线备份
-
Cold Backup(冷备)
冷备是在数据库停止情况下,这种备份最简单,一般只需要复制相关的数据库物理文件即可,官方称为离线备份
-
Warm Backup(温备)
温备是在数据库运行中进行的,但是对数据库操作有影响,比如加一个全局读锁以保证备份的数据一致性。
按照备份后文件的内容,备份又可以分为:
-
逻辑备份
在MySQL数据库中,逻辑备份是指备份出的文件内容是可读的,一般是文本文件。内容是由一条条SQL语句,或者是表内实际数据组成的。如
mysqldump和select * into outfile的方法。这类方法的好处是可以观察导出文件的内容,一般适用于数据库的升级、迁移等工作。但是缺点是恢复所需要的时间往往比较长。 -
裸文件备份
裸文件备份是指父之数据库的物理文件,既可以是在数据库运行中的复制(如ibbbackup, xtrabackup这类工具),也可以是在数据库停止时直接的数据文件复制。这类备份的恢复时间往往比逻辑备份短很多。
若按照备份数据的内容来分,备份可以分为:
-
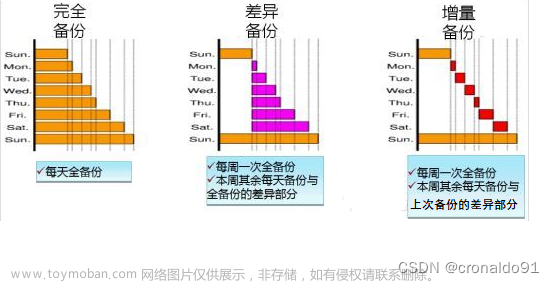
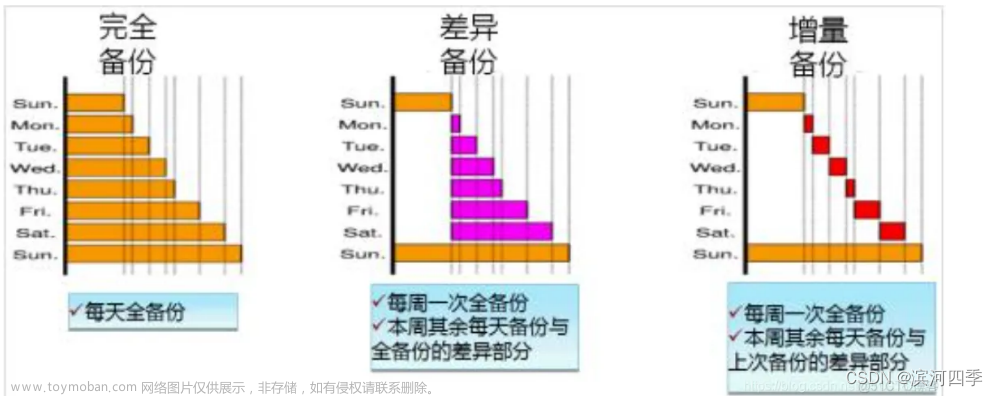
完全备份
完全备份是指对数据库进行一个完整的备份。
-
增量备份
增量备份是指上次完全备份的基础上,对于更改的数据进行备份。
-
日志备份
日志备份主要是指对MySQL数据库二进制日志的备份,通过对一个完全备份呢进行二进制日志的重做(replay)来完成数据库的
point-in-time的恢复工作。MySQL数据库复制(replaction)的原理就是异步实时的将二进制日志重做传送到从数据库(slave/standy)
对于MySQL数据库来说,官方没有提供真正的增量备份的方法,大部分是通过二进制日志完成增量备份的工作。这种备份较之真正的增量备份来说,效率还是很低的。例如一个100GB的数据库,要通过二进制日志完成备份的话,可能同一个页需要执行多次的SQL语句完成重做的工作。但是对于真正的增量备份来说,只需要记录当前页最后的检查点LSN,如果大于之前全备时的LSN,则备份该页,否则不用备份,这大大加快了备份的速度和恢复的时间,同时这也是xtrabackup工具增量备份的原理。
此外还需要理解数据库备份的一致性,这种备份要求在备份的时候数据在这一时间点上是一致的。
对于InnoDB存储引擎来说,因为其支持MVCC功能,因此实现一致的备份比较简单。用户可以先开启一个事务,然后导出一组相关的表,最后提交。当然用户的事务隔离级别必须设置为repeatable read ,这样的作法就可以给出一个完美的一致性备份。然后这个方法的前提是需要用户争取设计应用程序。对于上述的购买道具的过程,不可以分为两个事务完成,如一个完成扣费,一个完成道具购买。
对于mysqldump备份工具来说,可以通过添加--single-transaction选项获得InnoDB存储引擎的一致性备份,原理和之前所说的相同。需要了解的是,这时的备份是在一个执行很长的事务中完成的。另外,对于Innodb存储引擎的备份,务必加上--single-transcation参数。
任何时候都要做好远程异地备份,也就是容灾的防范。
2 冷备
对于InnoDB存储引擎的冷备,只需要备份MySQL数据库的frm文件、共享表空间文件、独立表空间文件、重做日志文件。另外建议定期备份MySQL数据库的配置文件my.cnf,这样有利于恢复操作。
当然只是在同一台机器上对数据库进行冷备是远远不够的,至少还需要将本地产生的备份文件存放到远程的服务器中,确保不会因为本地数据库的宕机而影响备份文件的使用。
冷备的优点是:
- 备份简单,只需要复制相关文件即可
- 备份文件易于在不同操作系统,不同MySQL版本上进行恢复。
- 恢复相当简单,只需要把文件恢复到指定位置即可
- 恢复速度快,不需要执行任何SQL语句,也不需要重建索引
冷备的缺点是:
- Innodb存储引擎冷备的文件通常比逻辑文件大,因为表空间文件存放很多其他数据,比如undo段,插入缓冲等信息
- 冷备也不总是可以轻易跨平台。操作系统、MySQL版本、文件大小写、浮点数格式都有可能成为问题。
3 逻辑备份
3.1 mysqldump
mysqldump备份工具,通过完成转存数据库的备份及不同数据库之间的移植,如从MySQL低版本升级到MySQL高版本数据库,又或者从MySQL数据库移植到Oracle、sql server数据库等。
mysqldump语法:
mysqldump [aguments] > file_name
如果想要备份所有数据库,可以使用--all-databases选项:
mysqldump --all-databases > dump.sql
如果想要备份指定数据库,可以使用--databases选项:
mysqldump --databases db1 db2 db3 > dump.sql
如果想要对test这个架构进行备份,使用--single-transcation保证备份一致性,可以使用如下语句:
mysqldump --single-transcation test > test_backup.sql
而且mysqldump有很多的参数,可以通过mysqldump --help命令来查看所有的参数,有些参数有缩写形式,如--lock-tables的缩写形式-l。简单列举一些常用的重要参数:
-
–single-transcation
在执行备份前,先执行start transcation命令,以此获得备份的一致性,当前该参数只对InnoDB存储引擎有效。当启用该参数并进行备份时,确保没有其他DDL语句执行,因为一致性读不能隔离DDL
-
–lock-tables(-l)
在备份中,依次锁住每个架构下的所有表。一般MyISAM引擎使用
--lock-tables,而InnoDB引擎使用--single-transcation即可。如果该架构下同时存在MyISAM表和InnoDB引擎表,则使用--lock-tables。 -
–lock-all-tables (-x)
在备份中对所有架构中的所有表上锁。这个可以避免之前说的
--lock-tables参数不能同时锁住所有表的问题 -
–add-drop-database
在create database前先运行drop database。这个参数需要和–all-databases或者–databases参数一起使用。
-
mysqldump -uroot -p zxy > zxy.sql
因为没有使用--databases参数,所以zxy.sql中没有create database 语句,即使使用 --add-drop-database也无用 -
mysqldump -uroot -p --databases zxy > zxy2.sql
# 添加--databases参数后,在文件首部生成如下指令。 -- -- Current Database: `zxy` -- CREATE DATABASE /*!32312 IF NOT EXISTS*/ `zxy` /*!40100 DEFAULT CHARACTER SET utf8 */; USE `zxy`; -
mysqldump -uroot -p --add-drop-database --databases zxy > zxy3.sql
# 在--databases基础上添加了--add-drop-database参数后,生成如下指令 -- -- Current Database: `zxy` -- /*!40000 DROP DATABASE IF EXISTS `zxy`*/; CREATE DATABASE /*!32312 IF NOT EXISTS*/ `zxy` /*!40100 DEFAULT CHARACTER SET utf8 */; USE `zxy`;
-
-
–master-data [=value]
使用该参数在生成备份文件时,会记录有change master语句,用于从数据库与主数据库建立连接。当
--master-data=1时,change master语句不被注释。当--master-data=2时,change master语句被注释。–master-data会自动忽略–lock-tables选项。如果没有使用–single-transaction选项,则自动使用–lock-all-tables选项
-
–events (-E)
备份事件调度器
-
–routines (-R)
备份存储过程和函数
-
–triggers
备份触发器
-
hex-blob
将binay,varbinary,blog,bit列类型备份为十六进制的格式。mysqldump导出的文件一般是我呢本。但是如果导出的数据中有上述类型,在我呢本文件模式下可能有些字符不可见,若添加–hex-blob,结果会以十六进制方式显示。
-
–tab=path
通过–tab指定文件生成目录,可以将每个表生成一个table.sql和一个table.txt文件。table.sql记录的是建表语句,table.txt记录的是表数据。通用可以使用
--fields-terminated-by='',--fields-enclosed-by='',--fields-optionally-enclosed-by='',--fields-escaped-by='',--ines-terminated-by=''来改变默认的切割符、换行符。 -
–where=‘where_condition’ (-w ‘where_condition’)
导出给定条件的数据
[root@zxy mysql]# mysqldump -uroot -p --single-transaction --where='id=1' zxy logs > logs.sql
3.2 select … into outfile
select…into语句也是逻辑备份的方法,更准确的说是导出一张表中的数据。select…into的语法如下:
select [column 1],[column 2]...
into
outfile 'file_name'
[
{fields | columns}
--每个列的分隔符
[terminated by 'string']
--字符串包含符
[[optionally] enclosed by 'char']
--转义字符
[escaped by 'char']
]
[
lines
--每行的开始符号
[starting by 'string']
--每行的结束符号
[terminated by 'string']
]
from table where ...
如果没有指定任何的fields和lines选项,默认使用以下设置:
fields terminated by '\t' enclosed by '' escaped by '\\'
lines terminated by '\n' starting by ''
file_name表示导出的文件,但文件所在路径权限必须是mysql:mysql,否则MySQL会报没有权限的错误。
mysql> select * from zxy into outfile '/zxy/data/mysql/zxy/zxy.txt';
ERROR 1 (HY000): Can't create/write to file '/zxy/data/mysql/zxy/zxy.txt' (Errcode: 13 - Permission denied)
案例测试
-
1.表数据查看
mysql> select * from zxy; +------+------+------------+------+ | id | name | testtime | sku | +------+------+------------+------+ | 1 | ZXY | 2023-03-10 | A-1 | | 2 | zxy | 2023-03-11 | B-1 | | 3 | ZXY | 2023-03-12 | C-1 | +------+------+------------+------+ 3 rows in set (0.00 sec) -
2.导出语句
-
fileds
按照逗号划分数据,每个数据使用单引号包裹,对反斜杠转义
-
lines
每条数据以zxy开头,每条数据间使用换行符划分
mysql> select * -> into outfile '/zxy/data/mysql/zxy/zxy11.txt' -> fields -> terminated by ',' -> enclosed by '\'' -> escaped by '\\' -> lines -> starting by 'zxy' -> terminated by '\n' -> from zxy; Query OK, 3 rows affected (0.00 sec) -
-
3.导出数据结果
[root@zxy zxy]# cat zxy11.txt zxy'1','ZXY','2023-03-10','A\\-1' zxy'2','zxy','2023-03-11','B\\-1' zxy'3','ZXY','2023-03-12','C\\-1'
3.3 逻辑备份的恢复
mysqldump恢复比较简单,因为备份的文件就是导出的SQL语句,一般只需要执行这个文件就可以了,可以通过如下两种方法:
-
mysql
[root@zxy zxy]# mysql -uroot -p < /zxy/data/mysql/zxy.sql -
source
mysql> source /zxy/data/mysql/zxy.sql;
通过mysqldump可以恢复数据库,但是mysqldump可以导出存储过程、触发器、事件、数据,但是不能导出视图,因此,如果还需要用到视图,那么在mysqldump备份数据库后还需要导出视图的定义,或者备份视图定义的frm文件,在恢复时导入。
3.4 load data infile
使用select into outfile导出的数据需要恢复,可以使用load data infile命令导入。其语法是:
load data infile 'file_name'
into table table_name
[charater set charset_name]
[
{fileds | columns}
[terminated by 'string']
[[optionally] enclosed by 'char']
[escaped by 'char']
]
[
lines
[starting by 'string']
[terminated by 'string']
]
[ignore number lines]
[{col_nameor_user_var,...}]
[set col_name=expr,...]
load data infile '/zxy/data/mysql/zxy/zxy11.txt'
into table zxy_1
fields
terminated by ','
enclosed by '\''
escaped by '\\'
lines
starting by 'zxy'
terminated by '\n'
;
案例测试
-
1.创建相同表结构
mysql> create table zxy_1 like zxy; Query OK, 0 rows affected (0.02 sec) -
2.导入数据
mysql> load data infile '/zxy/data/mysql/zxy/zxy11.txt' -> into table zxy_1 -> fields -> terminated by ',' -> enclosed by '\'' -> escaped by '\\' -> lines -> starting by 'zxy' -> terminated by '\n' -> ; Query OK, 3 rows affected (0.00 sec) Records: 3 Deleted: 0 Skipped: 0 Warnings: 0 -
3.检查数据
mysql> select * from zxy_1;
+------+------+------------+------+
| id | name | testtime | sku |
+------+------+------------+------+
| 1 | ZXY | 2023-03-10 | A\-1 |
| 2 | zxy | 2023-03-11 | B\-1 |
| 3 | ZXY | 2023-03-12 | C\-1 |
+------+------+------------+------+
3 rows in set (0.00 sec)
3.5 mysqlimport
mysqlimport是MySQL数据库提供的一个命令行的程序,从本质上来说,是load data infile的命令接口,而且大多数选项都和load data infile语法相同。其语法格式是:
mysqlimport [options] db_name textfile [textfile2...]
和load data infile不同的是,mysqlimport命令可以导入多张表。并且通过–user-thread参数可以并发导入不同的文件。
[root@zxy zxy]# mysqlimport -uroot -p --use-threads=2 zxy /zxy/data/mysql/zxy/zxy_2.txt /zxy/data/mysql/zxy/zxy_3.txt
Enter password:
zxy.zxy_2: Records: 3 Deleted: 0 Skipped: 0 Warnings: 0
zxy.zxy_3: Records: 3 Deleted: 0 Skipped: 0 Warnings: 0
4 二进制日志备份与恢复
二进制日志非常关键,用户可以通过完成point-in-time的恢复工作。MySQL数据库的replication同样需要二进制日志。在默认情况下并不启用二进制日志,要使用point-in-time则必须启用它。如配置文件中进行设置:
[mysqld]
log-bin=mysql-bin
除此之外,还可以额外设置:
当sync_binlog=1时,表示采用同步写磁盘的方式,不使用系统的缓冲来写二进制日志。即使系统宕机,也只是影响一个事务。
但是可能会造成二进制日志和InnoDB存储引擎数据不一致,这时可以使用innodb_support_xa=1处理,该参数支持多实例分布式事务,支持内部xa事务也就是支持binlog与innodb redo log之间的数据一致性。
sync_binlog=1
innodb_support_xa=1
在备份二进制日之前,可以通过flush logs命令来生成一个新的二进制文件。
-
1.恢复单个binlog
-
直接恢复
[root@zxy_master mysql]# mysqlbinlog mysql-bin.000001 | mysql -uroot -p zxy -
SQL文件恢复
[root@zxy_master mysql]# mysqlbinlog mysql-bin.000001 > mysql-bin000001.sql[root@zxy_master mysql]# mysql -uroot -p zxy < mysql-bin000001.sql
-
-
2.恢复多个binlog
-
直接恢复
[root@zxy_master mysql]# mysqlbinlog binlog.[0-10]* | mysql -uroot -p zxy -
SQL文件恢复
[root@zxy_master mysql]# mysqlbinlog mysql-bin.[0-10]* > mysqlbin.sql[root@zxy_master mysql]# mysql -uroot -p zxy < mysqlbin.sql
-
可以通过--start-position和--stop-position选项可以用来指定从二进制的某个偏移量来进行恢复,这样可以跳过某些不正确的语句,如:
[root@zxy_master mysql]# mysqlbinlog --start-position=10102 --stop-position=20234 mysql-bin.000001 > mysqlbin000001.sql
5 热备
5.1 ibbakup
ibbackup是InnoDB存储引擎提供的热备工具,可以同时备份MyISAM存储引擎和InnoDB存储引擎表。对于InnoDB存储引擎表其备份工作原理如下:
- 1)记录备份开始,InnoDB存储引擎重做日志文件检查点LSN
- 2)复制共享表空间文件以及独立表空间文件
- 3)记录复制完表空间文件后,InnoDB存储引擎重做日志文件检查点LSN
- 4)复制在备份时产生的重做日志
对于事务的数据库,如SQL Server和Oracle数据库,热备的原理大致和上述相同。可以发现,在备份期间不会对数据库本身有任何影响,所做的操作只是复制数据库文件,因此任何对数据库的操作都是允许的,不会阻塞任何操作。故ibbackup的优点如下:
- 在线备份,不阻塞任何的SQL语句
- 备份性能好,备份的实质是复制数据库文件和重做日志文件
- 支持压缩备份,通过选项,可以支持不同级别的压缩
-
跨平台支持,ibbackup可以运行在linux、Windows以及主流的unix系统平台上。ibbackup对InnoDB存储引擎表的恢复步骤为:
- 恢复表空间文件
- 应用重做日志文件
ibbackup提供了一种高性能的热备方式,是InnoDB存储引擎备份的首选方式。Ibbackup是收费软件,但是Percona公司也为用户提供了开源、免费的Xtrabackup热备工具,具备ibbackup的功能,并且支持真正的增量热备功能。因此,最好的选择是使用XtraBackup来完成热备工作。
5.2 XtraBackup
MySQL–基于Xtrabackup+Shell+Crond实现的数据库(全量+增量)热备份方案
XtraBackup备份工具是由Percona公司开发的开源热备工具。支持MySQL数据库的热备,并且是免费、开源,适用于MySQL所有版本、非阻塞、紧密压缩、高度安全。
XtraBackUp在备份的时候首先记录重做日志的位置,然后对备份的InnoDB存储引擎表文件的共享表空间和独立表空间进行copy,最后记录备份完成后的重做日志位置。
XtraBackup可选参数如下:
xtrabackup --help 查看
-
–print-defaults
打印默认配置,就是my.cnf的配置
-
–no-defaults
不读取配置
-
–defaults-file
指定默认配置文件
-
–defaults-extra-file
除了my.cnf外,额外读取的配置文件
-
–target-dir
备份地址,备份到哪
-
-backup
备份任务
-
–stats
输出统计信息
-
–prepare
在启用MySQL服务时准备一个备份
-
–export
在预备份时创建一个文件来导入其他数据库
-
–print-param
打印参数
-
–throttle
限制IO
-
–incremental-lsn
基于LSN的增量备份
-
–tables
选定哪些表
-
–databases
选定哪些数据库
-
–compress
支持压缩
…
6 快照备份
MySQL数据库备份&恢复(备份恢复)【备份策略五:lvm快照备份数据库(物理角度实现的完全备份)】
MySQL数据库本身并不支持快照功能。因此快照备份是指通过文件系统支持的快照功能对数据进行备份。
7 复制
7.1 复制的工作原理
复制是MySQL数据库提供一种高可用高性能的解决方案,一般用来建立大型的应用。总体来说,replication的工作原理分为3个步骤:
- 1)主服务器把数据更改到二进制日志中
- 2)从服务器把主服务器的二进制日志复制到自己的中继日志中
- 3)从服务器重做中继日志的日志,把更改应用到自己的数据库上,以达到数据的最终一致性。
复制的工作原理并不复杂,其实就是一个完全备份加上二进制备份的还原。不同的是这个二进制日志的还原操作基本上是实时进行中。这里特别需要注意的是,复制不是完全实时的进行同步。这中间存在主从服务器之间的执行延时,如果主服务器的压力很大,则可能导致主从服务器延时较大。

从服务器有2个线程,一个是I/O线程,负责主服务器日志的读取,并将其保存为中继日志;一个是SQL线程,负责执行中继日志。
如下所示:
在从数据库可以查到有两个线程,ID为10的是IO线程,负责接受主服务器的数据。ID为11的是SQL线程,负责执行数据的更新。
mysql> show full processlist\G;
*************************** 1. row ***************************
Id: 10
User: system user
Host:
db: NULL
Command: Connect
Time: 844633
State: Waiting for master to send event
Info: NULL
*************************** 2. row ***************************
Id: 11
User: system user
Host:
db: NULL
Command: Connect
Time: 844633
State: Slave has read all relay log; waiting for more updates
Info: NULL
MySQL的复制,其实是异步实时的,并且完全的主从同步。可以分别在主库执行show master status\G;查看当前的binlog日志文件和position。在从数据库执行show slave status\G;查看当前同步的状态。
-
show master status
mysql> show master status\G; *************************** 1. row *************************** File: mysql-bin.000005 Position: 919 Binlog_Do_DB: zxy Binlog_Ignore_DB: Executed_Gtid_Set: 1 row in set (0.00 sec)参数 说明 File 当前binlog文件名称 Position 当前binlog文件的偏移量 Binlog_Do_DB 复制指定的数据库 Binlog_Ignore_DB 忽略指定的数据库 Executed_Gtid_Set 已经执行的事务编号 -
show slave status
mysql> show slave status\G; Slave_IO_State: Waiting for master to send event Master_Host: 121.4.105.101 Master_User: slave Master_Port: 33061 Connect_Retry: 60 Master_Log_File: mysql-bin.000006 Read_Master_Log_Pos: 409 Relay_Log_File: relay-log-master_1.000008 Relay_Log_Pos: 622 Relay_Master_Log_File: mysql-bin.000006 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 409 Relay_Log_Space: 879 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 Master_UUID: 8cc1b48b-b997-11ed-9e64-0242ac110002 Master_Info_File: mysql.slave_master_info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: master_1 Master_TLS_Version:参数 说明 Slave_IO_State 显示IO线程状态 Master_Log_File 显示当前同步主服务器的二进制日志 Read_Master_Log_Pos 显示当前同步到主服务器上二进制日志的偏移量 Relay_Log_File 当前中继日志同步的二进制日志 Relay_Log_Pos 当前执行中继日志的偏移量位置 Slave_IO_Running 从服务器IO线程运行状态 Slave_SQL_Running 从服务器SQL线程运行状态 Exec_Master_Log_Pos 表示同步到主服务器二进制日志偏移量位置
想要计算IO线程的延时,可以使用master节点的偏移量减去slave节点读取到的主偏移量。Position(master) -Read_Master_Log_Pos(slave)
对于一个优秀的MySQL数据库复制监控,用户不应该仅仅监控从服务器上IO线程和SQL线程运行是否正常,也应该监控从服务器和主服务器之间延时,确保从服务器能尽快的同步并接近主服务器的状态。
7.2 快照+复制的备份架构
复制可以用来备份,但功能不仅限于备份,还可实现:
-
数据分布
由于MySQL数据库提供的复制并不需要很大的带宽要求,因此可以在不同的数据中心之间实现数据复制
-
读取负载均衡
建立多个从服务器,可以将读取平均的分布到这些从服务器中,并且减少主服务器的压力。一般通过DNS的Round-Robin和Linux的LVS功能都能实现负载平衡
-
数据库备份
复制对备份很有帮助,但是从数据库不是备份,不能完全代替备份
-
高可用和故障转移
通过复制建立的从服务器有助于故障转移,减少故障的停机时间和恢复时间。
可见,复制的设计不是简简单单的来备份,并且只是用复制来进行备份是远远不够的。假设当前应用采用了主从的复制架构,从服务器作为备份。这时,一个初级DBA执行了误操作,如drop database或drop table,这时从服务器也跟着运行了。那这种情况怎么恢复呢?
一个比较好的方法是通过对从服务器上的数据库所在分区做快照,以此避免误操作对复制造成影响。当主服务器发生误操作时,只需要要将从服务器上的快照进行恢复,然后根据二进制日志文件进行point-in-time恢复即可。

还有一些其他的方法调整复制,比如延时复制,即间接性的开启从服务器上的同步,保证大约一小时的延时。只是数据库在高峰期和非高峰期每小时产生的二进制数量是不同的,很难把握。
此外,建议从服务上启用read-only选项,这样能保证从服务器上的数据与主服务器进行同步,避免其他线程修改数据,如:文章来源:https://www.toymoban.com/news/detail-815097.html
[mysqld]
read-only
在启用read-only选项后,如果操作从服务器的用户没有super权限,则对从服务器进行任何的修改操作会抛出错误。文章来源地址https://www.toymoban.com/news/detail-815097.html
到了这里,关于《MySQL系列-InnoDB引擎07》MySQL备份与恢复的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!