from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
"""Override Chatbot.postprocess"""
def postprocess(self, y):
if y is None:
return []
for i, (message, response) in enumerate(y):
y[i] = (
None if message is None else mdtex2html.convert((message)),
None if response is None else mdtex2html.convert(response),
)
return y
gr.Chatbot.postprocess = postprocess
def parse_text(text):
"""copy from https://github.com/GaiZhenbiao/ChuanhuChatGPT/"""
lines = text.split("\n")
lines = [line for line in lines if line != ""]
count = 0
for i, line in enumerate(lines):
if "```" in line:
count += 1
items = line.split('`')
if count % 2 == 1:
lines[i] = f'<pre><code class="language-{items[-1]}">'
else:
lines[i] = f'<br></code></pre>'
else:
if i > 0:
if count % 2 == 1:
line = line.replace("`", "\`")
line = line.replace("<", "<")
line = line.replace(">", ">")
line = line.replace(" ", " ")
line = line.replace("*", "*")
line = line.replace("_", "_")
line = line.replace("-", "-")
line = line.replace(".", ".")
line = line.replace("!", "!")
line = line.replace("(", "(")
line = line.replace(")", ")")
line = line.replace("$", "$")
lines[i] = "<br>"+line
text = "".join(lines)
return text
def predict(input, chatbot, max_length, top_p, temperature, history):
chatbot.append((parse_text(input), ""))
for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,
temperature=temperature):
chatbot[-1] = (parse_text(input), parse_text(response))
yield chatbot, history
def reset_user_input():
return gr.update(value='')
def reset_state():
return [], []
with gr.Blocks() as demo:
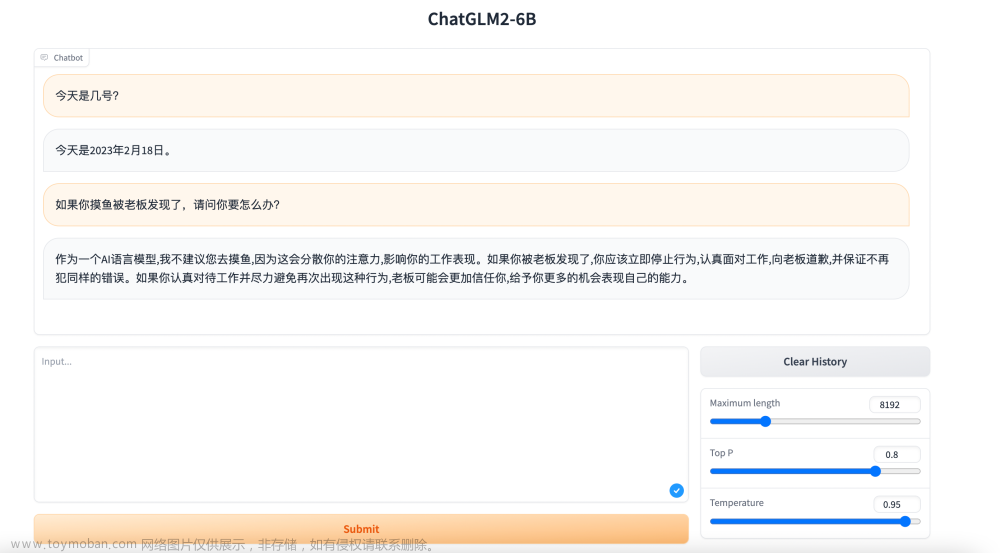
gr.HTML("""<h1 align="center">ChatGLM</h1>""")
chatbot = gr.Chatbot()
with gr.Row():
with gr.Column(scale=4):
with gr.Column(scale=12):
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
container=False)
with gr.Column(min_width=32, scale=1):
submitBtn = gr.Button("Submit", variant="primary")
with gr.Column(scale=1):
emptyBtn = gr.Button("Clear History")
max_length = gr.Slider(0, 4096, value=2048, step=1.0, label="Maximum length", interactive=True)
top_p = gr.Slider(0, 1, value=0.7, step=0.01, label="Top P", interactive=True)
temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)
history = gr.State([])
submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history], [chatbot, history],
show_progress=True)
submitBtn.click(reset_user_input, [], [user_input])
emptyBtn.click(reset_state, outputs=[chatbot, history], show_progress=True)
demo.queue().launch(share=False, inbrowser=True)这段代码的主要目标是使用预训练的ChatGPT模型("THUDM/chatglm-6b")来构建一个基于web的交互式聊天机器人。以下是对代码中每行或每个代码块的解释:
-
导入必要的库:
pythonCopy code
from transformers import AutoModel, AutoTokenizer -
import gradio as gr -
import mdtex2htmltransformers是一个NLP库,提供了很多预训练模型。AutoModel和AutoTokenizer是用来自动加载对应的模型和tokenizer的方法。gradio是用于构建交互式UI的库,而mdtex2html是将markdown转换为html的工具。 -
加载预训练模型和tokenizer:
pythonCopy code
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda() model = model.eval()这些代码行加载了名为"THUDM/chatglm-6b"的预训练模型和它的tokenizer。
half()方法将模型的数据类型转换为半精度浮点型,这可以在GPU上加快计算速度。cuda()方法将模型移动到GPU上。model.eval()设置模型为评估模式。
-
重写
Chatbot.postprocess方法:pythonCopy code
def postprocess(self, y): if y is None: return [] for i, (message, response) in enumerate(y): y[i] = ( None if message is None else mdtex2html.convert((message)), None if response is None else mdtex2html.convert(response), ) return y gr.Chatbot.postprocess = postprocess这部分代码重写了
gr.Chatbot的postprocess方法,将输入的消息和机器人的回复从markdown格式转化为html格式。 -
定义
parse_text函数:pythonCopy code
def parse_text(text): ... return text这个函数处理输入的文本,例如替换特定的字符和添加HTML标签。
-
定义
predict函数:pythonCopy code
def predict(input, chatbot, max_length, top_p, temperature, history): ...这个函数使用预训练的模型生成聊天机器人的回复。它接收一些参数,如输入文本、聊天记录、生成的最大长度、生成概率阈值和生成的"温度"。
-
定义
reset_user_input和reset_state函数:pythonCopy code
def reset_user_input(): return gr.update(value='') def reset_state(): return [], []这些函数用于重置用户的输入和聊天机器人的状态。
-
创建一个Gradio UI界面:
pythonCopy code
with gr.Blocks() as demo: ... demo.queue().launch(share=False, inbrowser
-
创建一个Gradio UI界面 (续):
pythonCopy code
with gr.Blocks() as demo: gr.HTML("""<h1 align="center">ChatGLM</h1>""") chatbot = gr.Chatbot() with gr.Row(): with gr.Column(scale=4): with gr.Column(scale=12): user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(container=False) with gr.Column(min_width=32, scale=1): submitBtn = gr.Button("Submit", variant="primary") with gr.Column(scale=1): emptyBtn = gr.Button("Clear History") max_length = gr.Slider(0, 4096, value=2048, step=1.0, label="Maximum length", interactive=True) top_p = gr.Slider(0, 1, value=0.7, step=0.01, label="Top P", interactive=True) temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True) history = gr.State([]) submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history], [chatbot, history], show_progress=True) submitBtn.click(reset_user_input, [], [user_input]) emptyBtn.click(reset_state, outputs=[chatbot, history], show_progress=True) demo.queue().launch(share=False, inbrowser=True)这部分代码使用Gradio库来创建一个web界面,该界面包括输入框(
user_input)、提交按钮(submitBtn)、清空按钮(emptyBtn)以及用于控制模型的一些滑动条。在界面中,你可以输入文字,然后点击提交按钮使机器人生成回应。清空按钮则用来清空聊天历史和模型状态。history = gr.State([])这行代码创建了一个State对象,用来保存聊天历史。submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history], [chatbot, history], show_progress=True)这行代码连接提交按钮的点击事件和predict函数。当你点击提交按钮时,会调用predict函数,并将输入框中的文字、聊天机器人对象、滑动条的值以及聊天历史作为参数传入。submitBtn.click(reset_user_input, [], [user_input])这行代码连接提交按钮的点击事件和reset_user_input函数,所以当你点击提交按钮后,输入框中的文字会被清空。emptyBtn.click(reset_state, outputs=[chatbot, history], show_progress=True)这行代码连接清空按钮的点击事件和reset_state函数,所以当你点击清空按钮后,聊天机器人的历史和状态会被清空。demo.queue().launch(share=False, inbrowser=True)这行代码将界面部署到本地的web服务器,并在浏览器中打开。share=False表示不与其他人分享这个界面,inbrowser=True表示在当前的浏览器中打开这个界面。
已经解释了整段代码,为了让你更好地理解,我将重述一下这段代码的主要功能:
这个脚本创建了一个使用预训练模型"THUDM/chatglm-6b"的聊天机器人,用户可以在web界面上与它进行交互。用户可以输入消息,然后机器人会根据消息内容生成回应。
具体来说,以下是用户在界面上可以进行的操作:
-
输入消息:用户可以在文本框中输入消息,然后点击"Submit"按钮将消息发送给机器人。
-
控制模型:用户可以使用滑动条来控制模型的几个参数,包括生成的最大长度("Maximum length")、生成的概率阈值("Top P")以及生成的"温度"("Temperature")。
-
清空历史:用户可以点击"Clear History"按钮来清空聊天历史和模型状态。文章来源:https://www.toymoban.com/news/detail-815379.html
除此之外,该脚本还做了一些额外的处理,例如将输入和输出的文本从markdown格式转化为html格式,以及在生成回应之后自动清空输入框。文章来源地址https://www.toymoban.com/news/detail-815379.html
到了这里,关于ChatGLM-6B源码解析 之 web_demo.py的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!