一、数据集介绍及性能评估
在常规目标检测数据集上,现有研究对大/中尺寸的目标已取得了不错的成效。但是,小目标的检测仍然是不尽人意的,一方面是由小目标自身特性所导致的的,另一方面是因为常规目标检测数据集中小目标存在占比少、分布不均匀等问题。接下来本文将按照时间顺序简要介绍现有的小目标数据集(见表2),并在一些公用数据集上对现有算法进行性能评估(见表3~6)。这些数据可供研究人员参考,希望可以为小目标检测的研究发展贡献微薄之力。
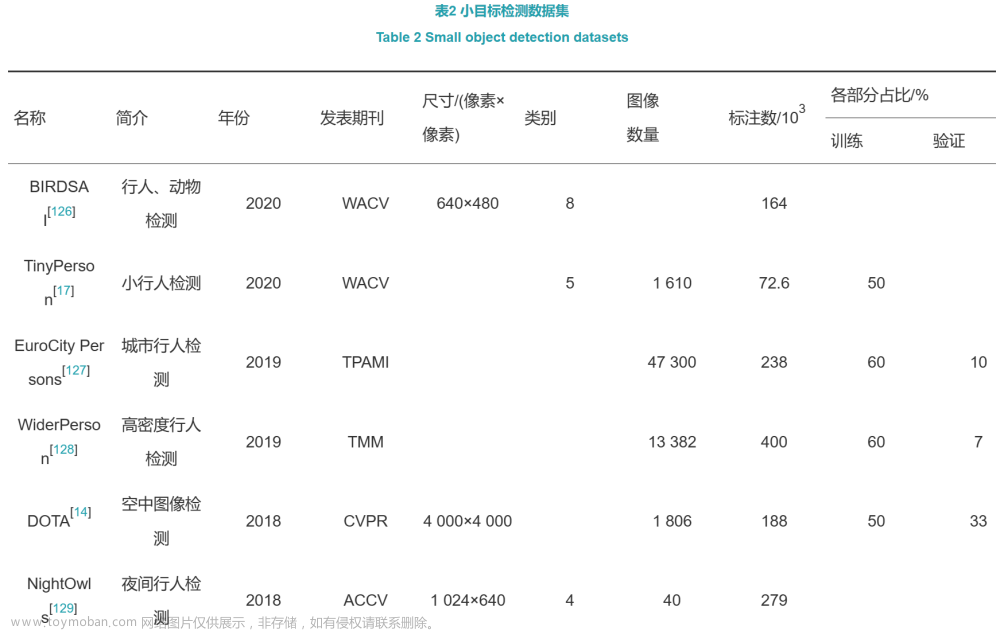







1.1 数据集介绍
(1)BIRDSAI数据集[126]。BIRDSAI寓意鸟的眼睛(bird’s‑eye),由Bondi等在WACV 2020(Winter Conference on Applications of Computer Vision 2020)上提出。该数据集使用带有红外摄像机的固定翼无人机收集,是第1个覆盖多个非洲保护区的大型数据集。主要由人类和动物的红外图像视频组成,总共包含10个类别:-1:未知,0:人类,1:大象,2:狮子,3:长颈鹿,4:狗,5:鳄鱼,6:河马,7:斑马,8:犀牛。其中涉及几个具有挑战性的场景,如尺度变化、热反射导致的背景杂波、大尺度旋转和运动模糊等。此外,该数据集还包含使用微软开源的AirSim模拟平台,即使用非洲热带草原的3D模型和TIR相机模型合成的虚拟视频。随着航空图像用于监测/监视场景的普及,该数据集将有助于推动基于航空红外视频图像的目标检测、目标跟踪以及领自适应等领域的研究。除了促进相关领域研究外,这个数据集也将有助于野生动物保护,成功的算法可以用来有效计数或跟踪保护区内的野生动物,进而避免野生动物偷猎。
(2)TinyPerson数据集[17]。随着深度卷积神经网络的兴起,视觉目标检测取得了前所未有的进展。然而,在大尺度图像中检测小于20像素的极小目标仍然没有得到很好的研究。对于极小目标的检测,一方面的挑战来自于其特征表示微弱,另一方面是复杂背景中存在大量相似特征增加了误报的风险。为了促进对于极小目标检测的研究,Yu等提出该数据集——TinyPerson,这是第1个远距离和大背景下进行人员检测的基准,为极小目标检测开辟了一个新的前景方向。该数据集由1 610幅图像构成,每幅图像包含超过200个人员,其中目标分为5个类别,共有72 651个手工标注的极小目标。
(3)EuroCity Persons数据集[127]。EuroCity Persons数据集由Braun等提出,该数据集主要为城市交通场景,包含大量种类繁多、准确且详细的目标,如行人、骑自行车者和其他乘客等。其中图像由一辆移动车辆在12个欧洲国家的31个城市收集。EuroCity Persons这一数据集包含47 300多张图像,含有手工标记的超过238 200个人员实例,比以前用于基准测试的人员数据集几乎大了一个数量级。特别地,该数据集还包含超过211 200条标明人员朝向的注释。总的来说,该数据集数量大、种类多、细节详尽,将城市交通场景中的人员注释提升到了一个新的水平。
(4)WiderPerson数据集[128]。WiderPerson是一个户外密集行人检测基准数据集,其中的图像不局限于交通场景而包含了更广泛的较拥挤场景。该数据集由13 382张图像组成,涉及5种类型的注释,共包含约400K条带有多种遮挡信息的标注,平均每幅图像标注29.87个目标,这意味着该数据集包含了各种遮挡下的密集行人。在该数据集中,训练集、验证集和测试集由随机选择的8 000/1 000/4 382张图像分别构成。与后文将提到的CityPersons和WIDER FACE数据集相似,WiderPerson数据集不发布测试图像的标注文件。
(5)DOTA数据集[14]。为了促进“Earth Vision”中的目标检测研究,Xia等提出了用于航空图像中目标检测的大型数据集DOTA。该数据集包含从不同传感器和平台上收集的2 806幅航拍图像。每幅图像的大小约为4 000像素×4 000像素,包含了各种尺度、方向和形状的对象。这些DOTA图像由航拍图像解译方面的专家使用15种常见的目标类别进行注释。完整注释的DOTA图像包含188 282个实例,每个实例都由一个任意四边形标记。
(6)Nighttowls数据集[129]。Nighttowls是一个用于夜间行人检测的公共数据集。不同于常规的白天场景,夜间的行人检测,由于存在更复杂的低光照、反射、模糊和变化的图像对比度等问题,更具挑战性。该数据集由行业标准相机跨越3个国家,在不同的季节和天气条件下拍摄,包含40个序列,共279 000帧的夜间影像。所有的图像都有详尽的注释,其中目标类别分为行人、骑自行车者、骑摩托车者和忽略区域4类。此外,注释汇总还包含了目标的额外属性,如遮挡、姿势和难度等,以及用于在多个帧中识别相同对象的跟踪信息。
(7)DeepScores数据集[19]。DeepScores是由Lukas等提出一个十分特别的小目标数据集,包含高质量的乐谱图像,由30万张包含不同形状和大小音乐符号的图像组成,共接近一亿个小目标,是最大的公共数据集。该数据集中提供了用于目标分类、目标检测和语义分割的真值标注,而且前10%的类含有整个数据集中85%的标志,可以用来模拟异常检测中的真实世界数据流。DeepScores通过将对象识别问题置于场景理解的背景下,意图促进小目标识别领域的研究,同时也对计算机视觉,尤其是光学音乐识别研究提出了相关挑战。
(8)Bosch小交通灯数据集[18]。Bosch小交通灯数据集是一个基于视觉图像的交通灯检测的精准数据集。该数据集由13 427幅分辨率为1 280像素×720像素的摄像机图像组成,其中包含约24 000个带标注的交通信号灯。标注信息包括交通灯的边框以及每个交通灯的当前状态。该数据集图像包含摄像机拍摄的原始12位HDR图像和重构的8位RGB彩色图像。RGB图像可用于训练和测试,但由于原始图像的压缩转换问题,RGB图像可能颜色异常或包含伪像。
(9)CityPersons数据集[16]。为了更好地训练数据,CityPersons这一数据集由Zhang等基于Cityscape数据集[130]提出。Cityscape数据集是一个大型数据集,包含来自50个不同城市街道场景中记录的多种立体视频序列,除了20 000个弱注释帧以外,还包含5 000帧高质量像素级注释。Citypersons数据集基于Cityscapes数据集为27个城市的5 000幅图像提供了30个视觉类的精细像素级注释,精细的标注包括人员和车辆的实例标签。另外来自其他23个城市的20 000张图片用粗糙的语义标签标注,没有实例标签。
(10)Tsinghua‑Tencent 100K数据集[131]。Tsinghua‑Tencent 100K是由Zhu等从中国5个城市的腾讯街景全景图中创建的一个大型交通标志基准。该数据集由100 000幅分辨率为2 048像素×2 048像素的图像组成,涵盖了不同光线和天气状况。在该数据集中,包含3万个交通标志实例,45个类别,其中每个交通标志都带有一个类别标签、边界框以及像素蒙版。此外,Tsinghua‑Tencent 100K这一基准使用与MS COCO基准相同的检测指标进行性能评估。
(11)WIDER FACE数据集[15]。WIDER FACE是由香港中文大学发布的大型人脸数据集,包含32 203图像,393 703标注人脸,涉及问题全面,难度较大。该数据集中以60个事件类别为基础进行划分,每个事件类别中随机选择40%/10%/50%的数据分别作为训练集/验证集/测试集。WIDER FACE考虑到通用目标的检测率和人眼的辨别能力,以图像的高将人脸分成3个尺度:小(1050像素)、中(50300像素)、大(大于300像素)。除尺度之外,该数据集中还标注了遮挡和姿态等信息用于对事件进行描述,并将事件分为了简单、中等、困难3类。
(12)MS COCO数据集[1]。MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。其中包括91类目标,328 000幅图像和2 500 000个标签。该数据集通过大量使用Amazon Mechanical Turk来收集数据,以场景理解为目标,主要从复杂的日常场景中截取。图像中的目标通过精确的分割标注进行位置的标定。现在有3种标注类型:目标实例、目标上的关键点和看图说话。
(13)Caltech行人检测数据集[132]。Dollar等提出的Caltech行人检测基准提供25万帧分辨率为640像素×480像素的图像序列,这些序列主要在城市环境中拍摄。Caltech数据集中注释了350 000个边界框和2 300个独立行人,包括边界框和详细的遮挡标签之间的时间对应关系,比同年的其他任何数据集都大两个数量级。此外,该数据集包含彩色视频序列,并包含了比典型行人数据集尺度范围更大、姿态变化更多的行人,也是第一个将边界框与详细遮挡时间对应的数据集。
(14)Penn‑Fudan行人检测与分割数据库[133]。Penn‑Fudan Database是由Wang等提出的1个图像数据库,由用于行人检测的图像组成。该图像数据库中包含170张取自校园周围和城市街道场景的图片,其中96张来自宾夕法尼亚大学周围,74张来自复旦大学周围。这些图片中共有345个带有标记的行人,而且每张图片中至少有一个行人。在Penn‑Fudan Database中,所有带标记的行人都是直立行走姿态,行人的高度范围为180~390像素。
二、性能评估
为了便于研究人员更好地了解小目标的发展现状,本文在几个常用的小目标数据集上对现有算法的性能进行了评估。
(1)MS COCO数据集。表3给出了较为先进的检测算法在COCO数据数据集上的检测结果。其中,AP表示平均精准率(Average precision),AP50、AP75分别表示IoU设为0.5、0.75时的平均精准率,APS、APM、APL分别表示小目标、中等尺寸目标、大尺寸目标的平均精准率。可以发现,大目标的检测性能是远远高于小目标的,小目标的检测性能只有大目标的一半。在所有比较算法中,Scaled‑YOLOv4[134]取了最好的检测性能,将小目标的检测性能提升到了38.1%。Scaled‑YOLOv4的成功主要归功于大量先进思想的集合,包括数据增强、特征融合、上下文学习和多尺度学习等。
(2)WIDER FACE数据集。表4给出了较为先进的检测算法在WIDER FACE数据集上的检测结果。在这些比较的算法中,IENet[135]取得了最好的检测性能,在Easy、Medium和Hard测试集上的AP分别为96.1%、94.7%和89.6%。在IENet中,特征融合和上下文被得到了充分利用。SRFACE(Super resolving face)[136]通过利用超分的思想也取得了不错的检测效果,在Hard测试集上的AP能达到87.3%。
(3)TinyPerson数据集。表5给出了较为先进的检测算法在TinyPerson数据数据集上的检测结果。其中,MRsamll50表示小目标在IoU设置为0.5时的漏检率(Miss rate),MRtiny50、MRtiny25、MRtiny75分别表示极小目标在IoU设置为0.5、0.25、0.75时的漏检率;APsamll50表示小目标在IoU设置为0.5时的平均精确率,APtiny50、APtiny25、APtiny75分别表示极小目标在IoU设置为0.5、0.25、0.75时的平均精确率。在这些比较的算法中,FCOS[102]在MRtiny50上以96.28%取得了最好的检测结果。尽管如此,在表4中可以发现它在APtiny50上的性能不尽人意,仅有17.90%,完全不能达到实际应用的需求。对于极小目标,RetinaNet with S‑α[155]设计一种专门针对极小目标的特征融合的方法,对FPN进行了改进,在APtiny50上以48.48%取得了最高的检测精度。文章来源:https://www.toymoban.com/news/detail-815538.html
(4)Tsinghua‑Tencent 100K数据集。表6给出了较为先进的检测算法在Tsinghua‑Tencent 100K数据数据集上的检测结果。在这些比较的算法中,YOLOv3‑Final[156]取得了最好的检测性能,在小目标的召回率和精确率上均取得了91%。Perceptual GAN[90]通过生成对抗网络将小目标的特征映射成与大目标等价的特征,显著提升了小目标的检测性能,取得了89%和84%的召回率和精确率。文章来源地址https://www.toymoban.com/news/detail-815538.html
三、参考文献
- BONDI E, JAIN R, AGGRAWAL P, et al. Birdsai: A dataset for detection and tracking in aerial thermal infrared videos[C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Los Alamitos:IEEE, 2020: 1747-1756. [百度学术]
- BRAUN M,KREBS S,FLOHR F,et al.The eurocity persons dataset: A novel benchmark for object detection[EB/OL].(2018-05-18)[2018-06-05].https://arxiv.org/abs/1805.07193. [百度学术]
- ZHANG S,XIE Y,WAN J,et al.Widerperson: A diverse dataset for dense pedestrian detection in the wild[J].IEEE Transactions on Multimedia,2019,22(2): 380-393. [百度学术]
- NEUMANN L, KARG M, ZHANG S, et al. Nightowls: A pedestrians at night dataset[C]//Proceedings of Asian Conference on Computer Vision. Cham: Springer, 2018: 691-705. [百度学术]
- CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 3213-3223. [百度学术]
- ZHU Z, LIANG D, ZHANG S, et al. Traffic-sign detection and classification in the wild[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 2110-2118. [百度学术]
- DOLLÁR P, WOJEK C, SCHIELE B, et al. Pedestrian detection: A benchmark[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2009: 304-311. [百度学术]
- WANG L, SHI J, SONG G, et al. Object detection combining recognition and segmentation[C]//Proceedings of Asian Conference on Computer Vision. Berlin, Heidelberg: Springer, 2007: 189-199. [百度学术]
- WANG C Y,BOCHKOVSKIY A,LIAO H Y M.Scaled-YOLOv4: Scaling cross stage partial network[EB/OL].(2020-11-16)[2021-02-22].https://arxiv.org/abs/2011.08036. [百度学术]
- LENG J,REN Y,JIANG W,et al.Realize your surroundings: Exploiting context information for small object detection[J].Neurocomputing,2021,433: 287-299. [百度学术]
- BAI Y, ZHANG Y, DING M, et al. Finding tiny faces in the wild with generative adversarial network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 21-30. [百度学术]
- REDMON J,FARHADI A.Yolov3: An incremental improvement[EB/OL].(2018-04-08)[2018-04-08].https://arxiv.org/abs/1804.02767. [百度学术]
- ZHU X, HU H, LIN S, et al. Deformable convnets v2: More deformable, better results[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 9308-9316. [百度学术]
- LI Y, CHEN Y, WANG N, et al. Scale-aware trident networks for object detection[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 6054-6063. [百度学术]
- TAN Z, NIE X, QIAN Q, et al. Learning to rank proposals for object detection[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 8273-8281. [百度学术]
- SONG G, LIU Y, WANG X. Revisiting the sibling head in object detector[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. new york: IEEE, 2020: 11563-11572. [百度学术]
- ZHU X,SU W,LU L,et al.Deformable DETR: Deformable transformers for end-to-end object detection[EB/OL].(2020-10-08)[2021-03-18].https://arxiv.org/abs/2010.04159. [百度学术]
- TAN M, PANG R, LE Q V. Efficientdet: Scalable and efficient object detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 10781-10790. [百度学术]
- YANG S, LUO P, LOY C C, et al. From facial parts responses to face detection: A deep learning approach[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2015: 3676-3684. [百度学术]
- ZHANG K,ZHANG Z,LI Z,et al.Joint face detection and alignment using multitask cascaded convolutional networks[J].IEEE Signal Processing Letters,2016,23(10): 1499-1503. [百度学术]
- ZHU C, ZHENG Y, LUU K, et al. CMS-RCNN: Contextual multi-scale region-based cnn for unconstrained face detection[C]//Deep learning for biometrics. Cham: Springer, 2017: 57-79. [百度学术]
- HU P, RAMANAN D. Finding tiny faces[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 951-959. [百度学术]
- NAJIBI M, SAMANGOUEI P, CHELLAPPA R, et al. SSH: Single stage headless face detector[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 4875-4884. [百度学术]
- WANG Y,JI X,ZHOU Z,et al.Detecting faces using region-based fully convolutional networks[EB/OL].(2017-09-14)[2017-09-18].https://arxiv.org/abs/1709.05256. [百度学术]
- WANG J,YUAN Y,YU G.Face attention network: An effective face detector for the occluded faces[EB/OL].(2017-11-20)[2017-11-22].https://arxiv.org/abs/1711.07246. [百度学术]
- LIU Y, SHI M, ZHAO Q, et al. Point in, box out: Beyond counting persons in crowds[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 6469-6478. [百度学术]
- ZHANG C,XU X,TU D.Face detection using improved faster RCNN[EB/OL].(2018-02-06)[2018-02-06].https://arxiv.org/abs/1802.02142. [百度学术]
- SAM D B,PERI S V,SUNDARARAMAN M N,et al.Locate, size and count: Accurately resolving people in dense crowds via detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020. DOI: 10.1109/TPAMI.2020.2974830. [百度学术]
- WANG Y,HOU J,HOU X,et al.A Self-training approach for point-supervised object detection and counting in crowds[J].IEEE Transactions on Image Processing,2021,30: 2876-2887. [百度学术]
- GONG Y, YU X, DING Y, et al. Effective fusion factor in FPN for tiny object detection[C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. New York: IEEE, 2021: 1160-1168. [百度学术]
- WAN J,DING W,ZHU H,et al.An efficient small traffic sign detection method based on YOLOv3[J].Journal of Signal Processing Systems,2020: DOI: 10.1007/S11265-020-01614-2. [百度学术]
- PANG J, CHEN K, SHI J, et al. Libra R-CNN: Towards balanced learning for object detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 821-830. [百度学术]
- LU X, LI B, YUE Y, et al. Grid R-CNN[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 7363-7372. [百度学术]
- ZHANG X,WAN F,LIU C,et al.Learning to match anchors for visual object detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2021. DOI: 10.1109/TPAMI.2021.3050494. [百度学术]
- SONG S,QUE Z,HOU J,et al.An efficient convolutional neural network for small traffic sign detection[J].Journal of Systems Architecture,2019,97: 269-277. [百度学术]
到了这里,关于【计算机视觉】小目标检测研究进展:数据集介绍及性能评估(详细讲解)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!











