目录
目录
一、脚本适用范围
二、将脚本配置到浏览器
三、脚本用法
四、脚本原理
五、脚本代码
一、脚本适用范围
脚本适用范围:一次性提取任意网站的布局类似的数据,例如 淘宝的商品价格、微博的热搜标题、必应搜索的图片链接



脚本不适用范围:页面布局不相似的数据。如下图圈出了两种样式的数据,不能一次性提取,需要手动分两次提取。

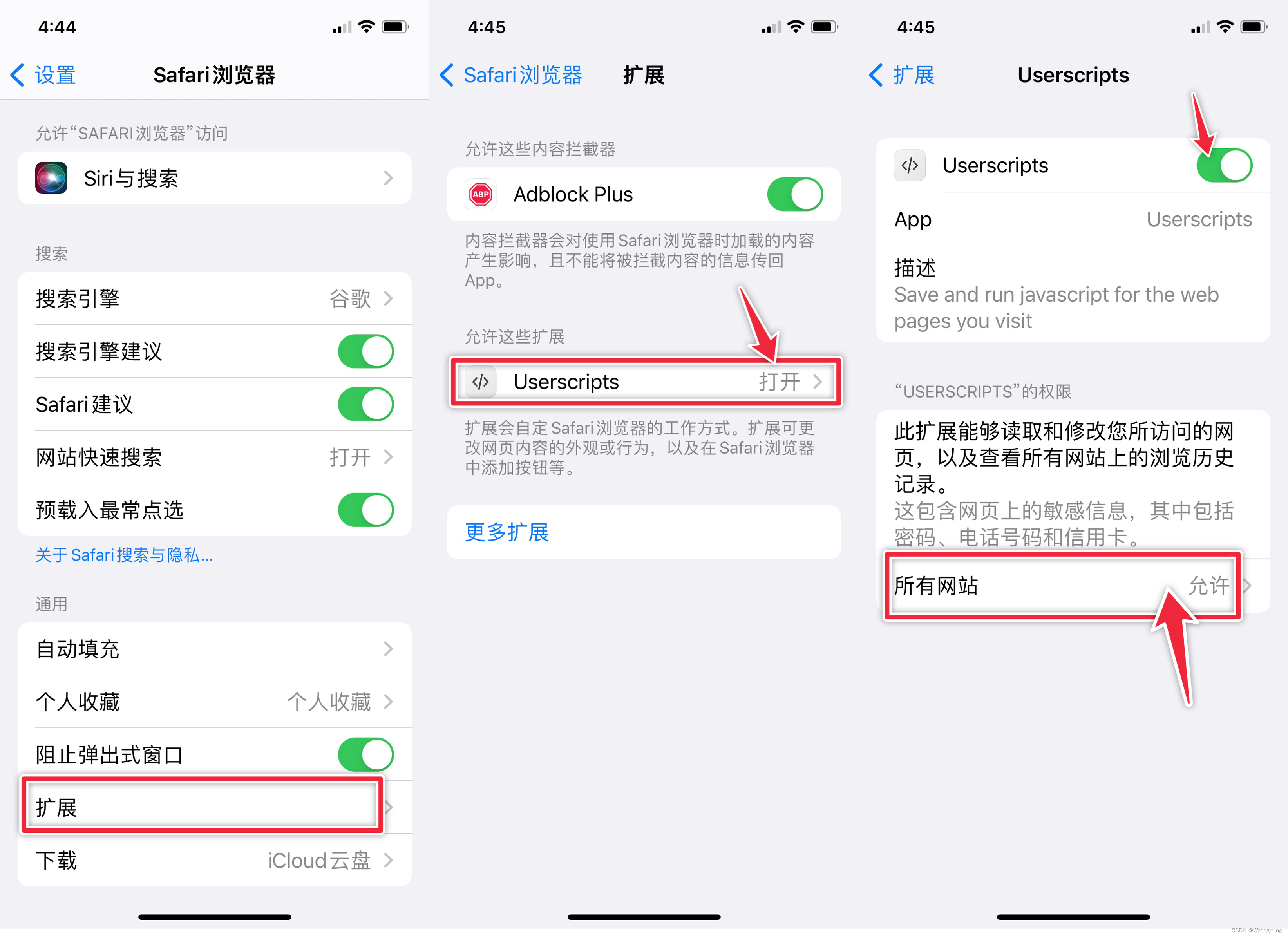
二、将脚本配置到浏览器
步骤:
(1)浏览器安装Tampermonkey(中文名 油猴、篡改猴)(可参考:油猴(Tampermonkey)安装教程-CSDN博客)
(2)将脚本源码(见本文最后一章节)保存到 Tampermonkey (中文名 油猴、篡改猴)中(可参考:)



(3)之后每次打开任意一个网页,浏览器页面右下角会出现三个输入框和一个按键,如下图

三、脚本用法
步骤:
(1)从类似的数据中选择两条,拷贝它们的 xpath 粘贴到脚本生成的前两个输入框中



(2)填入数据对应的标签的属性名称到第三个框中,如果不填,则提取标签体的文本(innerText)


(3)点击提取数据,会出现弹窗,说明运行结果。成功提取出的数据会被拷贝到粘贴板,直接Ctrl+V即可粘贴
四、脚本原理
如果元素样式类似,则它们在HTML源码的标签树路径应该是类似的(xpath路径就是寻找元素的一种方式)。
给定两个xpath:
/html/body/div[1]/div[1]/div[2]/div[3]/div/div/div[14]/div/div/div/div/span[2]/span[1]
/html/body/div[1]/div[1]/div[2]/div[3]/div/div/div[17]/div/div/div/div/span[2]/span[1]
找出它们的数字差异,删除,得到的xpath即可匹配页面中所有类似的元素
/html/body/div[1]/div[1]/div[2]/div[3]/div/div/div/div/div/div/div/span[2]/span[1]
再给出需要提取的数据在标签中对应的属性名称,就可以提取出需要的数据文章来源:https://www.toymoban.com/news/detail-815704.html
五、脚本源码
脚本源码(JavaScript):文章来源地址https://www.toymoban.com/news/detail-815704.html
// ==UserScript==
// @name 傻瓜式提取网页数据
// @namespace gzp
// @version 0.1
// @description 用XPath与属性名提取数据
// @author gzp
// @match *://*/*
// @grant GM_setClipboard
// @grant GM_setValue
// @grant GM_getValue
// ==/UserScript==
(function () {
'use strict';
// 给页面添加输入框与按键,并绑定回调函数。clickFunction 为点击按键时的回调函数
function insertElement(clickFunction) {
// 创建 XPath 输入框 1
let xpathInput1 = document.createElement("input");
xpathInput1.setAttribute('type', 'text')
xpathInput1.setAttribute('placeholder', '填写第一个标签的XPath路径')
xpathInput1.setAttribute('id', xpathInputId1)
xpathInput1.style.cssText = 'font-weight: normal; border: 2px solid #5813fe;box-shadow: 0px 0px 12px 0px rgba(98, 19, 254, 0.6); border-radius: 5px; height: 32px;width: 350px;margin: 5px; padding-left: 10px;'
// 创建 XPath 输入框 1
let xpathInput2 = document.createElement("input");
xpathInput2.setAttribute('type', 'text')
xpathInput2.setAttribute('placeholder', '填写第二个标签的XPath路径')
xpathInput2.setAttribute('id', xpathInputId2)
xpathInput2.style.cssText = 'font-weight: normal; border: 2px solid #5813fe;box-shadow: 0px 0px 12px 0px rgba(98, 19, 254, 0.6); border-radius: 5px; height: 32px;width: 350px;margin: 5px; padding-left: 10px;'
// 创建 需要提取的属性名称
let attributeInput = document.createElement("input");
attributeInput.setAttribute('type', 'text')
attributeInput.setAttribute('placeholder', '输入需要的属性名称(不输入时提取标签内文本)')
attributeInput.setAttribute('id', attributeInputId)
attributeInput.style.cssText = 'font-weight: normal; border: 2px solid #5813fe;box-shadow: 0px 0px 12px 0px rgba(98, 19, 254, 0.6); border-radius: 5px; height: 32px;width: 350px;margin: 5px; padding-left: 10px;'
// 创建 按键
let extractButton = document.createElement('button')
extractButton.setAttribute('id', 'extractButton')
extractButton.textContent = '提取数据'
extractButton.style.cssText = 'background-color: #4CAF50; border: none; color: white; margin: 5px; text-align: center; text-decoration: none; display: inline-block; font-size: 16px;border-radius: 5px; height: 32px;padding-left: 5px;'
extractButton.onclick = clickFunction // 绑定回调函数
// 添加上述几个元素到到一个位置固定的 div 中
let div = document.createElement('div')
div.appendChild(xpathInput1)
div.appendChild(document.createElement('br'))
div.appendChild(xpathInput2)
div.appendChild(document.createElement('br'))
div.appendChild(attributeInput)
div.appendChild(document.createElement('br'))
div.appendChild(extractButton)
div.style.cssText = 'position: fixed; bottom: 20px; right: 20px;z-index: 10000;'
// 显示之前缓存的输入数据
xpathInput1.value = GM_getValue(xpathInputId1 + url, '')
xpathInput2.value = GM_getValue(xpathInputId2 + url, '')
attributeInput.value = GM_getValue(attributeInputId + url, '')
// 添加 div 到网页中
document.body.appendChild(div)
}
// 一个工具函数,给定 xpath 路径,返回对应的多个元素的数组
function $x(STR_XPATH) {
var xresult = document.evaluate(STR_XPATH, document, null, XPathResult.ANY_TYPE, null);
var xnodes = [];
var xres;
while (xres = xresult.iterateNext()) {
xnodes.push(xres);
}
return xnodes;
}
// 给定两个模式类似的 xpath,返回能同时匹配它们的xpath,用于之后找出所有类似的元素
// 原理:将 xpath1、xpath2 分割为 “/” 分隔的一个个子串,再找出相同的子串,对于不同的子串将“[xxx]”删除
// 示例:
// 1. 以“/”为间隔符划分两个 XPath,得到子串数组
// “//div[1]/li” 被划分为 ["","","div[1]","li"]
// “//div[3]/li” 被划分为 ["","","div[3]","li"]
// 2. 对比两个 XPath 的数组,相同的子串保留,不同的删除 “[xxx]” 模式串,得到新的子串数组
// ["","","div","li"]
// 3. 以“/”为间隔符拼接上一步得到的子串数组,作为同时能匹配多个类似标签的 XPath
// “//div/li”
function toXPath(xpath1, xpath2) {
console.log('XPath路径 1', xpath1)
console.log('XPath路径 2', xpath2)
let list1 = xpath1.split('/')
let list2 = xpath2.split('/')
let result = ""
if (list1.length === list2.length) {
for (let i = 0; i < list1.length; i++) {
console.log(`子串:${list1[i]} 与 ${list2[i]}`)
if (list1[i] === list2[i]) {
result += list1[i]
console.log('完全相同', result, list1[i])
} else {
// let pattern1 = list1[i].replace(/\[\d+\]/, '[*]')
// let pattern2 = list2[i].replace(/\[\d+\]/, '[*]')
let pattern1 = list1[i].replace(/\[\d+\]/, '')
let pattern2 = list2[i].replace(/\[\d+\]/, '')
if (pattern1 === pattern2) {
result += pattern1
console.log('正则相同', result, pattern1)
}
else {
console.log('正则不同', result, pattern1, pattern2)
result = ''
break
}
}
if (i !== list1.length - 1) {
result += '/'
}
}
} else {
console.log(`两个表达式长度不同:第一个长度为 ${list1.length},第二个长度为 ${list2.length}`)
}
return result
}
// 根据 XPath 与属性名称(dataName)提取数据。如果 dataName 为空串,则提取标签体文本
function extractDataByXPathAndAttribute(xpath, dataName) {
console.log('dataName', dataName)
let items = $x(xpath)
if (items.length === 0) {
alert('XPath路径出错,找不到数据,请检查')
console.log(`XPath路径出错,找不到数据,请检查 ${xpath}`)
} else if (dataName !== '' && !items[0].hasAttribute(dataName)) {
alert(`找出的元素没有指定的属性 ${dataName},请重新输入`)
console.log(`找出的元素样例为 ${items[0]}`)
}
else {
let result = ''
if (dataName === '') {
items.forEach(item => {
result += '\n' + item.innerText;
})
}
else {
items.forEach(item => { result += '\n' + item.getAttribute(dataName) })
}
result = result.trim()
console.log(`-------- 提取出的数据(共${items.length}条数据) -------- \n${result}`)
GM_setClipboard(result)
alert(`已经提取出 ${items.length} 条数据与粘贴板,按Ctrl+V粘贴,数据如下\n${result}`)
saveInput()
}
}
// 缓存输入框数据
function saveInput(){
let xpathInput1 = document.getElementById(xpathInputId1)
let xpathInput2 = document.getElementById(xpathInputId2)
let attributeInput = document.getElementById(attributeInputId)
GM_setValue(xpathInputId1 + url, xpathInput1.value)
GM_setValue(xpathInputId2 + url, xpathInput2.value)
GM_setValue(attributeInputId + url, attributeInput.value)
}
// 按键回调函数
function extractData() {
console.log('数据提取结果')
let xpathInput1 = document.getElementById(xpathInputId1)
let xpathInput2 = document.getElementById(xpathInputId2)
let attributeInput = document.getElementById(attributeInputId)
if (xpathInput1.value === '' || xpathInput2.value === '') {
console.log(`有的XPath输入框还未输入任何内容`)
alert(`有的XPath输入框还未输入任何内容`)
return
} else {
let xpath = toXPath(xpathInput1.value, xpathInput2.value)
if (xpath.length === 0) {
alert('输入的两个XPath模式不相同,请重新检查')
}
extractDataByXPathAndAttribute(xpath, attributeInput.value)
}
}
const xpathInputId1 = 'xpathInput1'
const xpathInputId2 = 'xpathInput2'
const attributeInputId = 'attributeInput'
const url = document.location.href.replace(/[0-9]/g, '')
insertElement(extractData)
})();到了这里,关于傻瓜式提取网页数据的油猴脚本(JavaScript 代码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!