典型架构设计中缓存的存储位置
在现代软件架构中,缓存是优化数据检索、提高应用性能的关键组件。缓存的存储位置多种多样,每个位置针对特定的优化目标和需求。理解这些层级对于设计高效的系统至关重要。
-
浏览器缓存:这是最接近用户端的缓存层。浏览器缓存存储了用户经常访问的静态资源,如CSS文件、JavaScript脚本和图片。通过减少重复的网络请求,浏览器缓存显著提高了网页加载速度,并减少了服务器的负载。
-
内容分发网络(CDN)缓存:CDN缓存静态内容,如视频、图片和网页文件,分散在全球的多个地理位置。这样做可以减少数据传输距离,降低延迟,加快内容的交付速度。
-
反向代理缓存:位于服务器和用户之间,如Nginx或Varnish。它们缓存动态生成的网页和其他内容,减少了对原始服务器的直接请求,从而提高了响应速度和系统的整体性能。
-
分布式缓存系统:如Redis和Memcached,通常部署在应用服务器和数据库之间。它们在内存中存储频繁访问的数据,极大地减少了数据库的负载和响应时间。
-
应用服务器缓存:在应用层实现,用于临时存储计算成本高的数据。例如,应用服务器可能缓存复杂查询的结果,以快速响应相似的未来请求。
-
数据库缓存:大多数现代数据库管理系统内置了缓存机制,用于存储查询结果和常用数据。这可以显著加快数据库查询速度,特别是对于重复的查询请求。
通过在这些不同的层级实施缓存策略,系统可以显著减少数据处理和传输时间,提高用户体验,并降低后端系统的负担。在设计系统时,正确地利用这些不同类型的缓存是实现高性能和可扩展性的关键。
为什么 Redis 这么快
Redis(Remote Dictionary Server)是一种高性能的键值对数据库,它将数据存储在内存中,从而提供快速的数据读写能力。作为一个开源的内存数据结构存储系统,Redis 支持多种数据结构,如字符串(strings)、哈希(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)以及更复杂的数据结构,例如流(streams)、超日志(hyperloglogs)和地理空间索引(geospatial indexes)。
Redis 不仅仅是一个缓存解决方案,它还提供了一系列高级功能,如事务、发布/订阅消息系统、Lua 脚本支持等。Redis 的这些特性使其成为了构建现代、响应快速的应用程序的强大工具。
-
基于内存的数据存储:Redis 将所有数据存储在内存中,内存操作的速度远远超过磁盘操作,这是 Redis 高性能的主要原因。
-
效率高的数据结构:Redis 使用的数据结构非常高效,例如,它使用压缩列表(ziplist)和跳表(skiplist)来存储有序集合。这些结构既节省空间又提供了快速的读写能力。
-
单线程模型:虽然 Redis 是单线程的,但正是由于这种设计,它避免了常见的多线程或多进程的问题,比如上下文切换和锁竞争。单线程加上高效的数据结构使得 Redis 可以充分利用CPU的计算能力。
-
IO多路复用:Redis 使用 IO 多路复用技术来监听和响应来自客户端的请求。这使得单个线程可以同时处理多个网络连接,极大地提高了并发处理能力。
-
简单高效的协议:Redis 使用一种简单的协议(RESP)来与客户端通信。这种协议易于解析,降低了处理命令和返回结果的开销。
-
持久化策略:Redis 提供了灵活的数据持久化选项,如 RDB(快照)和 AOF(追加文件)。这些持久化策略在提供数据安全的同时,也保持了高效的性能。
通过这些设计决策和优化,Redis 能够提供极快的数据操作速度,适用于需要高速数据读写和实时性能的应用场景。
Redis的一些主要使用场景
-
缓存系统:Redis最常见的用途是作为缓存系统,用于临时存储热点数据,如网页、查询结果等,以减轻后端数据库的负担并提高数据检索速度。
-
会话存储(Session Store):Redis可以用来存储用户会话信息,特别是在Web应用中,它可以有效地处理大量并发的会话。
-
消息队列系统:Redis的发布/订阅(pub/sub)模式和列表结构使其成为实现消息队列的理想选择,支持高吞吐量和实时消息处理。
-
实时分析:Redis的快速数据处理能力使其适合用于实时分析应用,如计数器、统计信息的实时更新等。
-
排行榜和计数器:使用Redis的有序集合(sorted sets),可以非常方便地实现排行榜系统。这在社交网络、游戏排名等领域非常有用。
-
地理空间数据处理:Redis的地理空间索引功能可以存储地理位置信息并快速执行如范围查询、邻近查询等操作,适合用于地理空间数据相关的应用。
-
全文搜索:虽然Redis不是一个全面的全文搜索数据库,但它的数据结构可被用于实现简单的全文搜索。
-
分布式锁:在分布式系统中,Redis可以用来实现分布式锁,以确保跨多个节点的操作顺序和一致性。
-
数据流和实时计算:Redis的流数据结构(streams)适合用于构建消息流和进行实时计算任务。
-
机器学习模型服务:Redis的高速读写能力使其适合作为机器学习模型的服务接口,快速提供预测结果。
由于Redis的多样性和高性能,它被应用于从小型应用到大型企业级系统的各个领域。其灵活性和高效性使得Redis成为当前软件架构中不可或缺的组件之一。
设计和实现缓存系统时遵循的最佳实践
设计和实现缓存系统时遵循一系列最佳实践是至关重要的,以确保缓存机制的高效性、可靠性和可维护性。以下是一些关键的最佳实践:
-
合理选择缓存数据:
- 识别哪些数据最适合缓存,通常是频繁读取且不经常更改的数据。
- 避免缓存大量写频繁的数据,这可能导致缓存和数据库之间的频繁同步。
-
设置合理的过期策略:
- 为缓存数据设置适当的过期时间,以避免过时的数据长时间占用缓存空间。
- 使用不同的过期策略,如基于时间的过期、LRU(最近最少使用)策略等。
-
避免缓存雪崩:
- 缓存雪崩发生在大量缓存数据同时过期,导致对数据库的请求激增。解决方法包括设置随机的过期时间、使用分布式缓存和备用缓存策略。
-
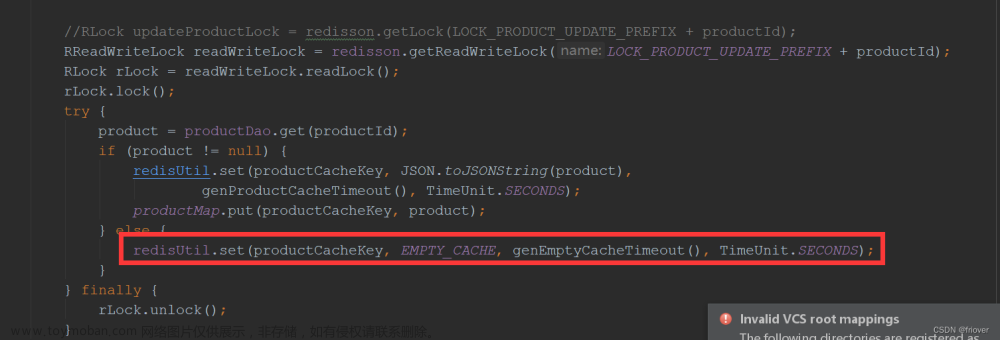
处理缓存穿透:
- 防止对不存在的数据进行重复查询。解决方案包括使用布隆过滤器或将查询结果(即使是空)缓存一段时间。
-
避免缓存击穿:
- 对于热点数据,使用锁或同步机制来防止大量并发请求击中数据库。
-
数据一致性:
- 确保缓存数据与数据库中的数据保持一致。在数据更新时,同步更新或失效相关缓存。
-
使用多级缓存:
- 结合本地缓存和分布式缓存,以减少延迟和分散负载。
-
监控和日志记录:
- 监控缓存系统的性能指标,如命中率、负载、响应时间等。
- 记录关键操作和异常,以便于问题追踪和性能调优。
-
容量规划:
- 根据应用需求合理规划缓存大小,避免内存溢出或资源浪费。
-
安全性考虑:
- 保护缓存数据的安全,特别是涉及敏感信息时。考虑使用加密和访问控制。
-
灵活性和可扩展性:文章来源:https://www.toymoban.com/news/detail-815906.html
- 设计时考虑未来的扩展性,确保缓存策略可以适应不断变化的需求。
遵循这些最佳实践可以帮助确保您的缓存系统既高效又可靠,同时减少潜在的维护问题和性能瓶颈。文章来源地址https://www.toymoban.com/news/detail-815906.html
到了这里,关于缓存解析:从架构设计到Redis应用及最佳实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!