半结构化分析主要是指对 MAP,STRUCT,JSON,ARRAY 等复杂数据类型的查询分析。这些数据类型表达能力强,因此被广泛应用到 OLAP 分析的各种场景中,但由于其实现的复杂性,对这些复杂类型分析将会比一般简单类型要更困难和耗时,例如:
-
需要对 MAP,STRUCT,JSON 等数据类型中的某个字段进行查询分析。由于这些复杂类型会被存储为一个整体,因此需要先将整个半结构化类型的字段先从存储层读取上来,然后再对其中的某些字段进行分析,IO效率较低。 -
对复杂类型进行较为耗时的分析计算(聚合,排序等等),查询的实时CPU 开销可能也是一个不可忽略的性能影响因素。
面对上述的挑战,StarRocks在3.1 版本正式推出生成列(Generated Column)特性,提供一种透明加速的解决方案,能有效提升半结构化数据的分析效率,令用户拥有更极速的分析体验。
生成列介绍
生成列是一种特殊的列,可以在建表语句或 Schema Change 语句中指定,生成列绑定到一个标量表达式上,当数据导入时,会自动根据表达式定义进行计算,并且将其计算结果写入到生成列中。
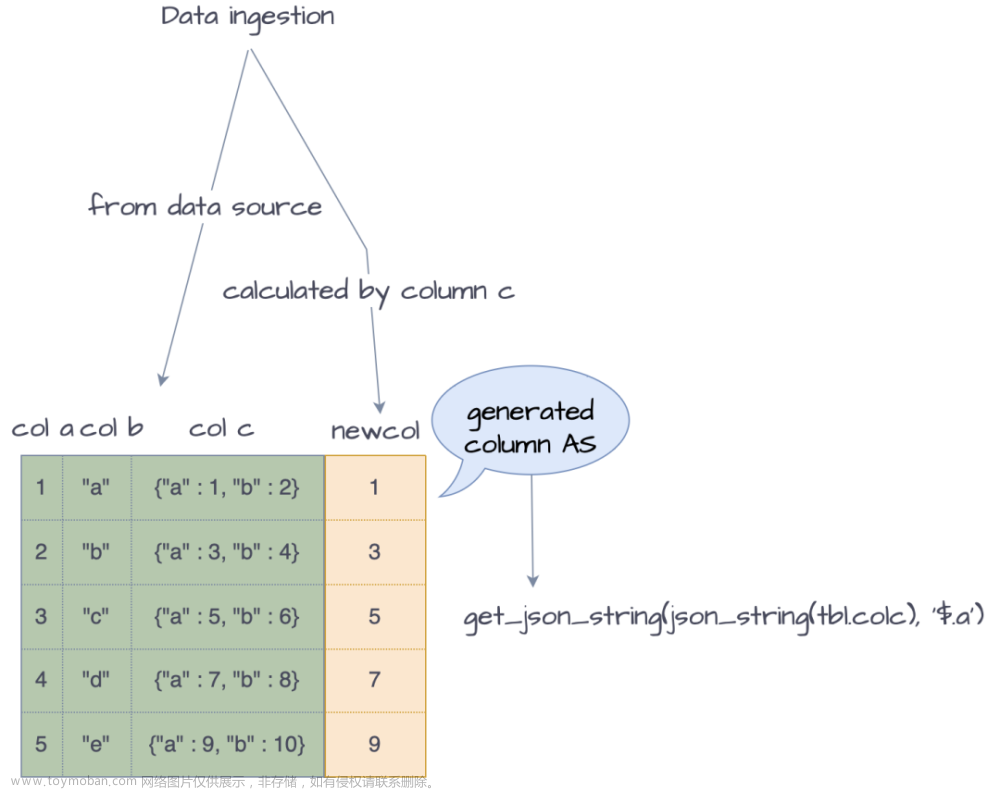
在半结构化分析的场景中,可以将复杂耗时的标量表达式绑定在某个生成列上,在数据导入阶段提前将结果计算好并且持久化到磁盘中。当需要进行查询分析时,即可马上获得表达式计算的结果。
生成列的查询改写
当希望查询生成列保存的表达式计算结果时,可以直接在 SQL 中指定生成列的列名,但是这种方法意味着需要调整已有业务 SQL,很难完全做到无缝对接。
为了进一步提升功能的使用体验,简化使用流程,StarRocks 支持生成列自动查询改写。在生成执行计划时,SQL 优化器将会检查 SQL 中所有的表达式,并且将那些已经绑定到生成列上的表达式,改写成查询生成列列值。
例如,上述例子中,如果在某个查询中需要获取 colc 中的 a 字段,则执行查询SELECT get_json_string(json_string(tbl.colc), '$.a') FROM tbl,执行过程大致如下:

可见,优化器自动将表达式改写为查询生成列的值,实现透明加速。
高效的生成列加列
在实际应用生成列的使用场景中,在已有的表添加生成列可能是一个高频操作。例如,可能在任意时间点发现某个表达式计算存在性能瓶颈,因此希望添加生成列以进行查询加速。
StarRocks 支持高效的加列操作,对于添加普通列,存储引擎并不会真正重写物理文件,而只是将物理文件重新 link 到新 Tablet 的路径下,修改元数据,完成加列操作。但是,如 MODIFY COLUMN 这类 Schema Change 操作,由于需要改变存量数据的内容,因此会重写所有物理文件。类似地,对于生成列加列来说,由于需要存储新增的生成列表达式的计算结果,重写数据似乎也是不可避免的。但是,如果仍然采用全量重写物理文件的方案,将无法很好适应频繁加列的场景,加列的代价太大。
为了进一步提高生成列加列的效率,StarRocks 针对生成列加列进行了专门的优化。当添加一个生成列时,不会改写存量的物理文件,而是为每一个存量的 segment 生成一个只包含生成列值的 cols 文件(物理格式和 segment 文件一样,但只包含生成列一列数据),当需要查询这些存量数据时,StarRocks 会自动将 segment 和 cols 文件的内容进行合并,获得正确的查询结果。
总的来说,生成列加列优化后,读 I/O 只涉及到生成列表达式的引用列,写 I/O 只涉及到生成列本身的表达式结果,整个 Schema Change 的 I/O 效率相比完全重写有大幅提高,更好支持实时动态生成列加列的用户需求。

效果验证
为了更好验证生成列对半结构化分析的加速效果,我们进行了简单的测试验证。
集群信息:StarRocks v3.1 1FE1BE ,104C376GB
创建一张如下的数据表,
CREATE TABLE `t` (
`id` bigint(20) NOT NULL COMMENT "",
`array_int` ARRAY<int(11)> NOT NULL COMMENT "",
`json_data` json NOT NULL COMMENT "",
`gc_1` double NULL AS array_avg(`test`.`t`.`array_int`) COMMENT "",
`gc_2` ARRAY<int(11)> NULL AS array_sort(`test`.`t`.`array_int`) COMMENT "",
`gc_3` varchar(65533) NULL AS get_json_string(json_string(`test`.`t`.`json_data`), '$.a') COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`) BUCKETS 48
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"replicated_storage" = "true",
"compression" = "LZ4"
)
普通列数据创建方式: id,作为 primary key 列保证唯一。
array_int,长度为 10000 的 ARRAY ,保存的都是随机数。
json_data,包含两个 key,key "a" 对应的 value 为整型 1,key "b" 对应的value 是长度为 100 个 uuid 构成的字符串 性能测试使用下面的 query:
q1:SELECT get_json_string(json_string(json_data), '$.a') FROM A
q2:SELECT array_avg(array_int) FROM A;
测试结果:

从上述的测试结果可知:
q1:使用生成列提取大 JSON 字段中的某个子字段,在查询阶段大幅节省了读取 JSON 字段的 I/O 消耗,查询性能提升达 4 倍以上。
q2:使用生成列对大 ARRAY 字段进行聚合计算(计算平均值),在查询阶段不仅节省读取该半结构化数据字段的 I/O 消耗,同时也大幅节省了 ARRAY 聚合计算所带来的 CPU 消耗,获得百倍的性能提升。
总结
生成列功能是一种加速半结构化分析的有效手段,当面对复杂的半结构化表达式计算时,可以为其添加对应的生成列,在导入阶段自动完成表达式计算,并将结果持久化。在查询阶段通过优化器的自动改写,直接从生成列中获得表达式计算结果,避免实时的表达式计算,实现透明加速。 通过使用生成列,用户能大幅减少查询时复杂表达式的 I/O,CPU 等资源消耗,在不同的场景下获得数倍甚至百倍的性能提升。文章来源:https://www.toymoban.com/news/detail-815956.html
本文由 mdnice 多平台发布文章来源地址https://www.toymoban.com/news/detail-815956.html
到了这里,关于StarRocks 生成列:百倍提速半结构化数据分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!