实验7 Spark初级编程实践
一、实验目的
1. 掌握使用Spark访问本地文件和HDFS文件的方法
2. 掌握Spark应用程序的编写、编译和运行方法
二、实验平台
1. 操作系统:Ubuntu18.04(或Ubuntu16.04);
2. Spark版本:2.4.0;
3. Hadoop版本:3.1.3。
三、实验步骤(每个步骤下均需有运行截图)
实验前期准备:




1. Spark读取文件系统的数据
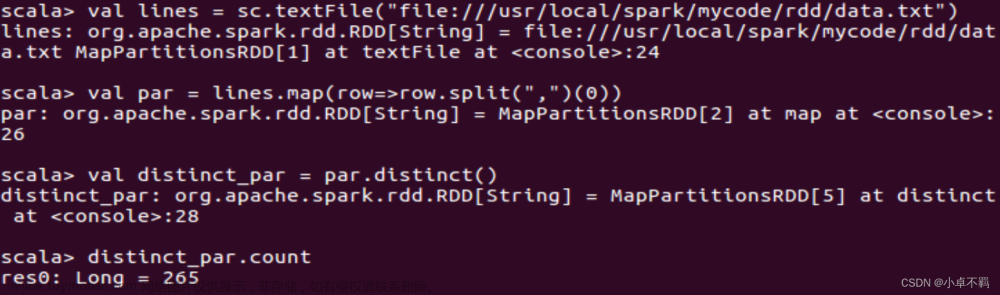
(1)在spark-shell中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;


 文章来源:https://www.toymoban.com/news/detail-816311.html
文章来源:https://www.toymoban.com/news/detail-816311.html
(2)在spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;文章来源地址https://www.toymoban.com/news/detail-816311.html
到了这里,关于大数据技术原理及应用课实验7 :Spark初级编程实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!