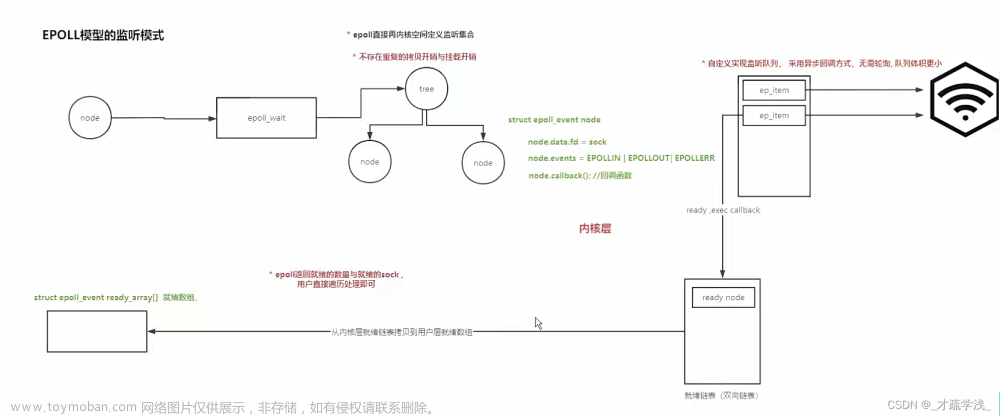
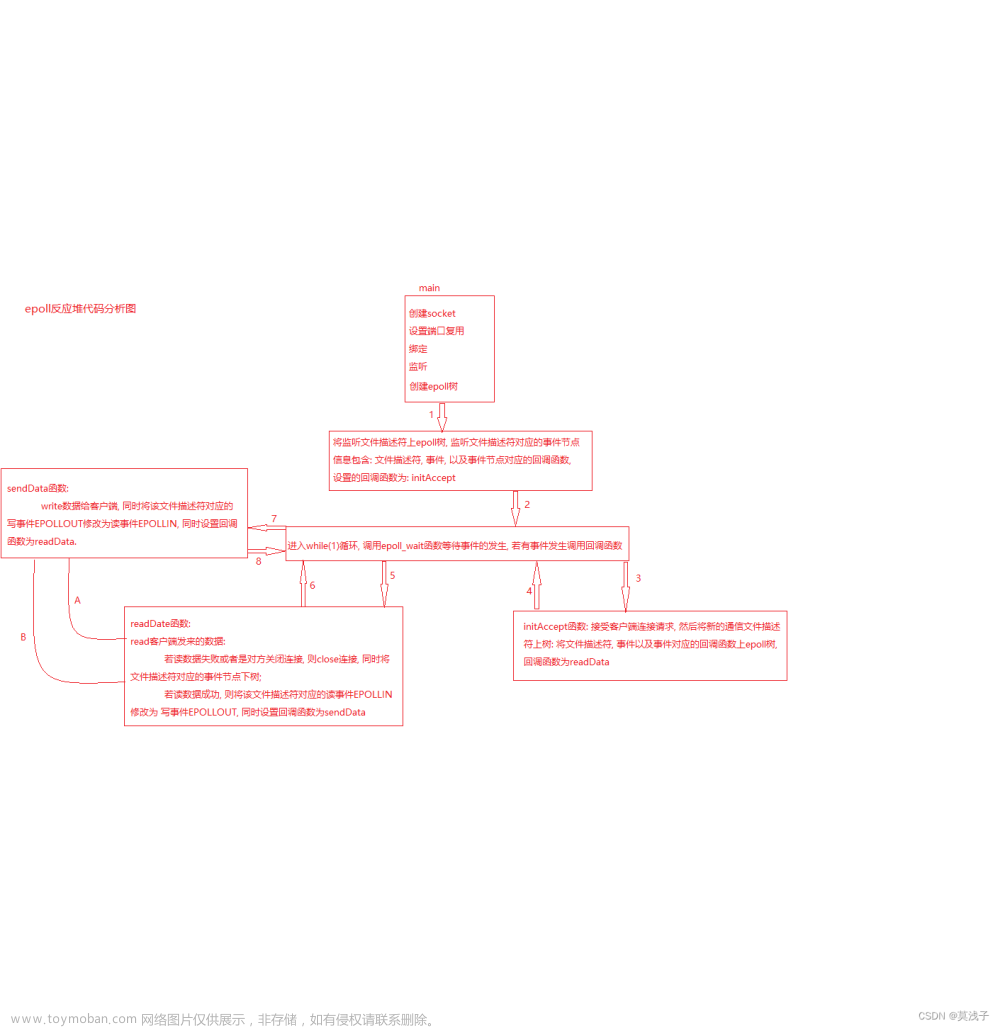
看完前两篇再看这篇,本篇将会写Reactor
1、数据所有处理都放在底层
EpollServer.hpp中创建一个函数HandlerRequest,用它来做Recver函数的数据处理,也就是数据分析。
void HandlerRequest(Connection *conn)
{
//保证所有数据都被分析,要加循环
int quit = false;
while (!quit)
{
std::string requestStr;
int n = ParsePackage(conn->inbuffer_, &requestStr);
// 看ParsePackage
// n为0表示没有不合理字符串或者inbuffer剩下的不够规定的长度,不用判断
if (n > 0) // 保证读到了完整的请求
{
// 回调函数在Main.cc中
// 这边先反序列化,再交给回调函数
// 上面改成using func_t = std::function<void(const Request&)>;
requestStr = RemoveHeader(requestStr, n);
Request req;
req.Deserialize(requestStr);
func_(conn, req); // 交给回调函数处理
}
else quit = true;
}
}
void Recver(Connection* conn)
{
//读取完了本轮数据
do
{
char buffer[bsize];//1024
ssize_t n = recv(conn->fd_, buffer, sizeof(buffer) - 1, 0);
if(n > 0)
{
buffer[n] = 0;
conn->inbuffer_ += buffer;
}
else if(n == 0)//另一端关闭了套接字,要关闭连接
{
conn->excepter_(conn);//归到异常处理
}
else
{
//和之前的一样做法
if(errno == EAGAIN || errno == EWOULDBLOCK) break;
else if(errno == EINTR) continue;
else conn->excepter_(conn);
}
} while (conn->events & EPOLLET);
//根据基本协议,进行数据分析,上面读完再分析
HandlerRequest(conn);
}
改一下回调函数,不向外暴露Connection类。
void HandlerRequest(Connection *conn)
{
//保证所有数据都被分析,要加循环
int quit = false;
while (!quit)
{
std::string requestStr;
//1、提取完整报文
int n = ParsePackage(conn->inbuffer_, &requestStr);
if (n > 0)
{
//2、提取有效载荷
requestStr = RemoveHeader(requestStr, n);
//3、进行反序列化
Request req;
req.Deserialize(requestStr);
//4、进行业务处理
//using func_t = std::function<Response (const Request&)>;
Response resp = func_(req);//request保证是一个完整的报文
}
else quit = true;
}
}
Main.cc中就不需要两个函数,一个计算函数就可以
#include "EpollServer.hpp"
#include <memory>
//用之前网络计算器的计算函数
Response Calculate(const Request& req)
{
Response resp(0, 0);
switch(req._op)
{
case '+':
resp._result = req._x + req._y;
break;
case '-':
resp._result = req._x - req._y;
break;
case '*':
resp._result = req._x * req._y;
break;
case '/':
if(req._y == 0) resp._code = 1;
else resp._result = req._x / req._y;
break;
case '%':
if(req._y == 0) resp._code = 2;
else resp._result = req._x / req._y;
break;
default:
resp._code = 3;
break;
}
return resp;
}
int main()
{
std::unique_ptr<EpollServer> svr(new EpollServer(Calculate));
svr->InitServer();
svr->Disptcher();
return 0;
}
处理数据那里再加上最后的步骤
void HandlerRequest(Connection *conn)
{
//保证所有数据都被分析,要加循环
int quit = false;
while (!quit)
{
std::string requestStr;
//1、提取完整报文
int n = ParsePackage(conn->inbuffer_, &requestStr);
if (n > 0)
{
//2、提取有效载荷
requestStr = RemoveHeader(requestStr, n);
//3、进行反序列化
Request req;
req.Deserialize(requestStr);
//4、进行业务处理
//using func_t = std::function<Response (const Request&)>;
Response resp = func_(req);//request保证是一个完整的报文
//5、序列化
std::string RespStr;
resp.Serialize(&RespStr);
//6、添加报头
RespStr = AddHeader(RespStr);
//7、返回
conn->outbuffer_ += RespStr;
}
else quit = true;
}
}
回到Recver函数,调用HandlerRequest函数后
void RecverHelper(Connection* conn)
{
//读取完了本轮数据
do
{
char buffer[bsize];//1024
ssize_t n = recv(conn->fd_, buffer, sizeof(buffer) - 1, 0);
if(n > 0)
{
buffer[n] = 0;
conn->inbuffer_ += buffer;
}
else if(n == 0)//另一端关闭了套接字,要关闭连接
{
conn->excepter_(conn);//归到异常处理
}
else
{
//和之前的一样做法
if(errno == EAGAIN || errno == EWOULDBLOCK) break;
else if(errno == EINTR) continue;
else conn->excepter_(conn);
}
} while (conn->events & EPOLLET);
}
void Recver(Connection* conn)
{
RecverHelper(conn);
//根据基本协议,进行数据分析,上面读完再分析
HandlerRequest(conn);
//读完并分析完了,该写入了
//写入的时候,直接写入,没写完再交给epoll
if(!conn->outbuffer_.empty()) conn->sender_(conn);
}
走到发送函数Sender这一步,调整一下思路,有多少就移除多少,也不判断了,而能走出循环只有要发到的缓冲区满了或者异常了
void Sender(Connection* conn)
{
do
{
ssize_t n = send(conn->fd_, conn->outbuffer_.c_str(), conn->outbuffer_.size(), 0);
if(n > 0) conn->outbuffer_.erase(0, n);
else
{
if(errno == EAGAIN || errno == EWOULDBLOCK)//对面缓冲区满了
{
//下句表示我们还有数据没发送完,然而大条件是对面的缓冲区满了
//此时发送条件不满足了,所以只能告知epoll关心读写事件,让epoll底层去做
if(!conn->outbuffer_.empty()) EnableReadWrite(conn, true, true);
else EnableReadWrite(conn, true, false);//空了那就不管了
break;
}
else if(errno == EINTR) continue;//收到信号中断,但还要继续发
else
{
conn->excepter_(conn);
break;
}
}
} while (conn->events & EPOLLET);//ET模式就一直循环,不是就退出
}
不过这样还不够严谨
void Sender(Connection* conn)
{
bool safe = true;
do
{
ssize_t n = send(conn->fd_, conn->outbuffer_.c_str(), conn->outbuffer_.size(), 0);
if(n > 0)
{
conn->outbuffer_.erase(0, n);
if(conn->outbuffer_.empty()) break;
}
else
{
if(errno == EAGAIN || errno == EWOULDBLOCK) break;
else if(errno == EINTR) continue;
else
{
safe = false;
conn->excepter_(conn);
break;
}
}
} while (conn->events & EPOLLET);//ET模式就一直循环,不是就退出
if(!safe) return ;
//下句表示我们还有数据没发送完
//此时发送条件不满足了,所以得告知epoll关心读写事件,让epoll底层去做
if(!conn->outbuffer_.empty()) EnableReadWrite(conn, true, true);
else EnableReadWrite(conn, true, false);//空了那就不管了
}
这样Recver那里的调用sender只是第一次触发发送,发完了就直接关掉,没发完底层就会持续关注读写事件,此后收到数据底层就会调用Sender函数。
2、处理异常事件
void Excepter(Connection* conn)
{
//1、先从epoll移除fd
epoller_.DelEvent(conn->fd_);
//2、移除unordered_map的KV关系
//因为这一步需要conn里的fd,所以在关闭fd之前做这步
connections_.erase(conn->fd_);
//3、关闭fd
close(conn->fd_);
//4、conn对象释放掉
delete conn;
logMessage(Debug, "Excepter...done, fd: %d, clientinfo: [%s:%d]", conn->fd_, conn->clientip_.c_str(), conn->clientport_);
}
异常处理不能重复调用。在Recver函数里,调用Helper后如果因为异常而退出,后面还有HandlerRequest以及剩下的操作,所以这里得区分一下。Sender也是。Recver里加个ret来判断,Sender不需要改
int RecverHelper(Connection* conn)
{
int ret = true;
//读取完了本轮数据
do
{
char buffer[bsize];//1024
ssize_t n = recv(conn->fd_, buffer, sizeof(buffer) - 1, 0);
if(n > 0)
{
buffer[n] = 0;
conn->inbuffer_ += buffer;
}
else if(n == 0)//另一端关闭了套接字,要关闭连接
{
conn->excepter_(conn);//归到异常处理
ret = false;
}
else
{
//和之前的一样做法
if(errno == EAGAIN || errno == EWOULDBLOCK) break;
else if(errno == EINTR) continue;
else
{
conn->excepter_(conn);
ret = false;
break;
}
}
} while (conn->events & EPOLLET);
return ret;
}
void Recver(Connection* conn)
{
if(!RecverHelper(conn)) return ;
//根据基本协议,进行数据分析,上面读完再分析
HandlerRequest(conn);
//读完并分析完了,该写入了
//写入的时候,直接写入,没写完再交给epoll
if(!conn->outbuffer_.empty()) conn->sender_(conn);
}
Protocol.hpp中改一下打印形式,用FaseWriter而不是StyleWriter。
#else
Json::Value root;
root["result"] = _result;
root["code"] = _code;
Json::FastWriter writer;
//Json::StyledWriter writer;
*outstr = writer.write(root);
3、理解Reactor(代码链接在这里)
像前一篇加上这一篇代码所体现,底层有epoll驱动,进行事件派发的就是Reactor服务器。
Reactor是基于多路转接的包含事件派发器,连接管理器等半同步半异步的IO服务器。最底层第一层是Epoller.hpp,Sock.hpp,Util.hpp,第二层是EpollServer.hpp,第三层是协议Protocol.hpp,第四层就是上层的业务处理。同步体现在事件就绪是由epoll通知的,读取是服务器做的,异步体现在多线程,业务处理,只是代码里没写。异步的操作可以在Main.cc的计算函数时一开始就接入线程池,进入多线程,可以把Request封装成任务,放到任务队列去多线程处理,然后可以通过回调把任务结果返回来。
Reactor事件分为三个,事件派发,读写,业务处理。派发和读写是同步的,业务处理是异步的。Reactor一般只负责派发和读写,业务处理交给多线程。也有只负责事件派发的,一旦有事件就绪,就将读写和业务处理都交给多线程,这样的方式下,Reactor部分只有事件派发,这部分叫做前摄式。Linux绝大部分的服务器都用Reactor,包括前摄式。
Reactor是一个底座,上面有很多个connection,哪个conn有事件就绪了哪个就回调已经自己对应的函数。
1、连接管理
一般的连接管理是应用层做的,比如TCP的每隔一段时间就去询问连接是否还存在。应用层的做法有很多,以我们的代码为例,可以在Connection类中添加一个字段
#include <ctime>
const static int linkTimeout = 30;
//Connection成员时间戳
time_t lasttime;//该connection最近一次就绪的时间
//AddConnection函数
conn->lasttime = time(nullptr);
//RecverHelper的do之前
//重新获取一下时间
conn->lasttime = time(nullptr);//更新conn最近访问时间
//事件派发器
void Disptcher()
{
int timeout = 1000;
while(true)
{
LoopOnce(timeout);
checkLink();
}
}
void checkLink()
{
time_t curr = time(nullptr); // 获取当前时间
for (auto &connection : connections_)
{
if (connection.second->lasttime + linkTimeout > curr)
continue;
else // 已超时
Excepter(connection.second);
}
}
timeout的设置应当找最近一次超时的时间,可以用最小堆。
Reactor
派发 + 读写的部分也可以改成多线程。一个fd以及对应的connection只能由一个线程来进行管理,防止多个来读写会错误混乱。主线程包含Reactor,listen套接字添加到Reactor,也就是说,主线程就可以是EpollServer.hpp文件;然后创建多个线程,每个线程都有EpollServer类,但没有listen套接字;构建一个任务队列,当listen套接字上有事件就绪时,把套接字sock封装,放到队列里,然后再分给子线程,子线程将得到的sock,添加到自己的epoll中,那么文件描述符的处理就交给多线程处理了。以上主线程做的工作就是连接派发,中间的任务队列去做负载均衡。
Reactor多进程。和线程一样,每个进程都有自己的Reactor。主进程有eactor加上listen套接字,以及其它子进程,还有和每个子进程之间的管道,主进程写,子进程读。子进程继承父进程的listen套接字,能看到listen套接字,但不添加到epoll,而是将管道的读端添加到epoll;父进程如果有listen套接字就绪,不读,通过管道随机挑选一个子进程,向管道随机写一个值来唤醒这个子进程,子进程醒来后调用accept来接收这个套接字,随后添加到自己的Reactor中。父进程还可以通过管道向子进程发送别的信息,比如移除这个进程,再开启一个新的子进程,所以父可以通过管道对子进行操作,类似这样的叫做master-slaver模式。Nginx就是master-slaver模式。
另有一个多进程的办法是父进程和子进程低位相同。每一个进程都把listen套接字添加到自己的epoll中,当底层有事件就绪时,所有进程通过多进程加锁的方式竞争,只有一个可以accept得到套接字。只不过这种方式有可能让优先级更高的进程多次拿到机会,有一些进程就没法去操作了,这里也可以用些策略去控制。但实际的方法还是上面的多线程和多进程两个办法。
多线程也可以用管道,也是把自己的写端放到子线程自己的epoll里,这样的话,可以不用担心线程之间的同步关系,建立多个管道对应多个线程。文章来源:https://www.toymoban.com/news/detail-816398.html
结束。文章来源地址https://www.toymoban.com/news/detail-816398.html
到了这里,关于Linux学习记录——사십오 高级IO(6)--- Epoll型服务器(3)(Reactor)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!