完全分布式Hadoop署集群
大家好,我是行不更名,坐不改姓的宋晓刚,下面将带领大家从基础到小白Hadoop学习,跟上我的步伐进入Hadoop的世界。
微信:15319589104
QQ: 2981345658
文章介绍:
在大数据时代,Hadoop已成为处理海量数据的必备工具。但如何从零开始搭建一个完整的Hadoop分布式集群呢?本文将为你详细介绍这一过程,帮助你轻松搭建自己的Hadoop集群,从硬件准备到集群配置,再到优化与维护,每一步都为你详细解读。
1.1部署Hadoop集群
在前面单机模式下克隆出来三台虚拟机分别是HadoopMaster,HadoopSlave,HadoopSlave1
1.0修改主机名
1.1修改主机1的名字为HadoopMaster
[hadoop@master ~]$ hostnamectl set-hostname hadoopmaster
[hadoop@master ~]$ bash
[hadoop@hadoopmaster ~]$
1.2修改主机2的名字为HadoopSlave
[hadoop@master sbin]$ hostnamectl set-hostname hadoopslave
[hadoop@master ~]$ bash
[hadoop@hadoopslave ~]$
1.3修改主机3的名字为HadoopSlave1
[hadoop@master ~]$ hostnamectl set-hostname hadoopslave1
[hadoop@master ~]$ bash
[hadoop@hadoopslave1 ~]$
2.0添加主机映射
2.1添加主机HadoopMaster的映射
[hadoop@hadoopmaster ~]$ sudo vi /etc/hosts
192.168.139.136 hadoopmaster //主机1
192.168.139.138 hadoopslave //主机2
192.168.139.1 hadoopslave1 //主机3
2.2将/etc/hosts文件复制给我主机hadoopslave和hadoopslave1上
[hadoop@hadoopmaster ~]$ sudo scp /etc/hosts 192.168.139.138:/etc/hosts //主机的ip地址
[hadoop@hadoopmaster ~]$ sudo scp /etc/hosts 192.168.139.1:/etc/hosts
2.3在主机hadoopmaster上查看主机映射:
[hadoop@hadoopmaster ~]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.139.136 hadoopmaster
192.168.139.138 hadoopslave
192.168.139.1 hadoopslave1
2.4在主机hadoopslave上查看主机映射:
[hadoop@hadoopslave ~]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.139.136 hadoopmaster
192.168.139.138 hadoopslave
192.168.139.1 hadoopslave1
2.5在主机hadoopslave1上查看主机映射:
[hadoop@hadoopslave1 ~]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.139.136 hadoopmaster
192.168.139.138 hadoopslave
192.168.139.1 hadoopslave1
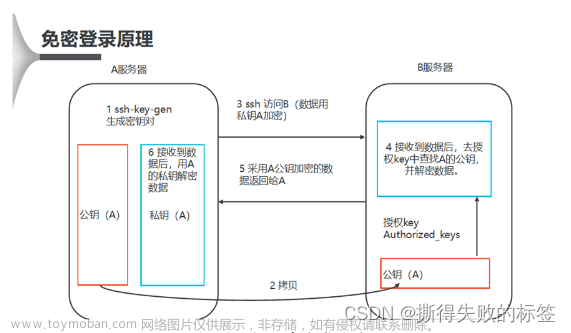
3.0配置免密登录
3.1为主机hadoopmaster配置免密登录:
[hadoop@hadoopmaster ~]$ ssh-keygen
[hadoop@hadoopmaster ~]$ ssh-copy-id hadoopmaster
[hadoop@hadoopmaster ~]$ ssh-copy-id hadoopslave
[hadoop@hadoopmaster ~]$ ssh-copy-id hadoopslave1
3.2验证免密登录
各节点之间需要进行验证,通过主机名称判断当前主机
[hadoop@hadoopmaster ~]$ ssh hadoopmaster //主机1
Last login: Thu Apr 6 20:55:43 2023
[hadoop@hadoopmaster ~]$ exit
登出
Connection to hadoopmaster closed.
[hadoop@hadoopmaster ~]$ ssh hadoopslave //主机2
Last login: Thu Apr 6 21:23:24 2023 from master
[hadoop@hadoopslave ~]$ exit
登出
Connection to hadoopslave closed.
[hadoop@hadoopmaster ~]$ ssh hadoopslave1 //主机3
Last login: Thu Apr 6 21:43:16 2023
[hadoop@hadoopslave1 ~]$ exit
登出
Connection to hadoopslave1 closed.
4.0设置时间同步
各个主机的时钟与ntp1.aliyum.com时钟保持同步
[hadoop@hadoopmaster ~]$ sudo ntpdate ntp1.aliyum.com
[hadoop@hadoopslave ~]$ sudo ntpdate ntp1.aliyum.com
[hadoop@hadoopslave1 ~]$ sudo ntpdate ntp1.aliyum.com
5.0配置hadoop
部署hadoop集群时,每个节点上的hadoop配置基本相同,只需要在hadoopMaster节点操作,配置完成后复制到hadoopSlave和hadoopSlave1上就可以了
在hadoopmaster中进行以下设置:
5.1设置环境变量hadoop-env.sh的内容如下:文章来源:https://www.toymoban.com/news/detail-816773.html
[hadoop@hadoopmaster ~]$ cd hadoop/etc/hadoop/
[hadoop@hadoopmaster hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/home/hadoop/java //因为我们将jdk的名字修改为java
5.2设置核心组件core-site.xml的内容如下:文章来源地址https://www.toymoban.com/news/detail-816773.html
[hadoop@hadoopmaster hadoop]$ vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS到了这里,关于1.1完全分布式Hadoop署集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!