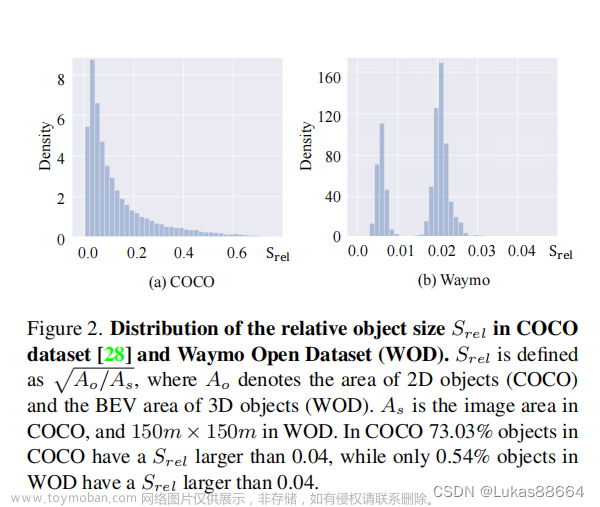
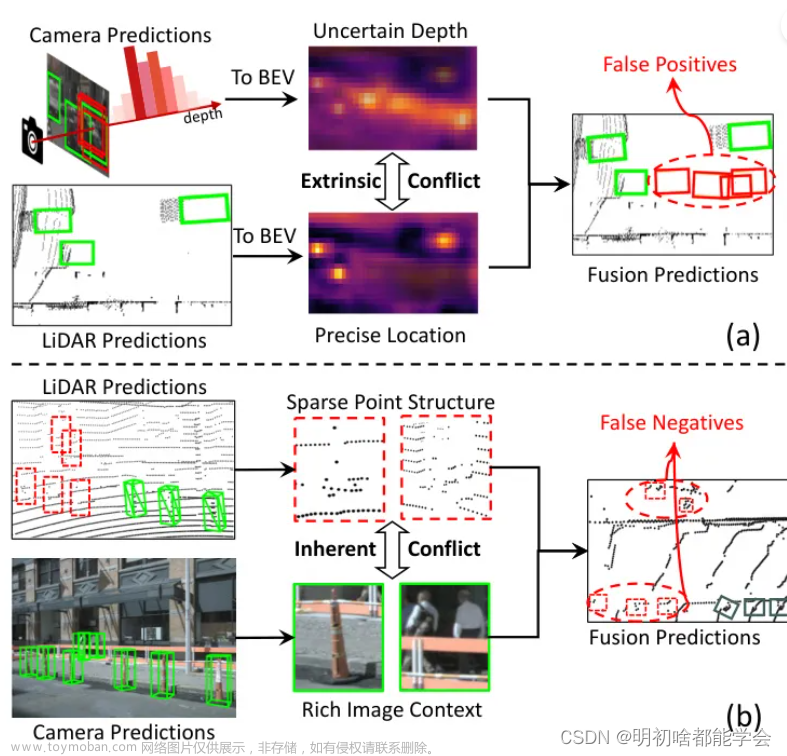
MVF
End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
论文网址:MVF
论文代码:
简读论文
这篇论文提出了一个端到端的多视角融合(Multi-View Fusion, MVF)算法,用于在激光雷达点云中进行3D目标检测。论文的主要贡献有两个:
-
提出了动态体素化(Dynamic Voxelization)的概念。相比传统的硬体素化(Hard Voxelization),动态体素化可以完整地保留原始点云信息,消除体素特征的不确定性,为不同视角的特征融合奠定基础。
-
设计了多视角特征融合的网络架构。该架构从鸟瞰图和透视图透视图(Perspective View)指的是从激光雷达传感器的视角所看到的点云范围图像表示。具体来说,对于激光雷达扫描得到的点云{(x, y, z)},可以转换到球坐标系{(φ, θ, d)},其中:φ是点在xy平面上的角度值,θ是点的仰角,d是点到传感器的距离。于是可以得到一个二维的透视图图像,其中一个维度是φ,另一个维度是θ,像素的值是距离d。这可以视为从传感器视角投影得到的点云范围图像。相比鸟瞰图,透视图保留了点云的原始扫描结构信息,是一个更接近原始点云的表示。它的优点是可以更稠密地表示点云,尤其是在远距离区域。但缺点是物体的形状会随距离发生变形。 两个视角对点云进行动态体素化,学习每个点的视角相关特征,然后将不同视角的体素特征融合到每个点上,增强点特征的表达能力。
具体来说:
-
动态体素化不需预先定义体素的数量和大小,根据点云分配的体素数量和点数量是可变的,从而可以完整保留原始点信息,消除硬体素化中因采样带来的信息丢失和特征不确定性。
-
网络架构包含三个模块:
(1) 共享的点特征学习模块,将每个点投影到高维特征空间。
(2) 不同视角的动态体素化和视角相关特征学习模块。其中鸟瞰图采用垂直pillar结构,透视图采用范围图像结构。
(3) 基于动态体素化建立的点-体素关系,将不同视角的体素特征融合到每个点上。 -
在Waymo和KITTI数据集上验证了该方法,结果显示动态体素化和多视角融合均可以明显提升检测性能,尤其是在远距离小目标的检测上取得显著改进。
整体来说,该论文通过动态体素化和多视角特征融合,提出了一个端到端的网络架构,可以更有效地利用点云的互补信息,增强点特征表达,从而提高基于激光雷达的3D目标检测性能。该思想可以推广到其他基于点云的检测网络中。
摘要
最近关于 3D 目标检测的工作提倡鸟瞰视图中的点云体素化,其中物体保留其物理尺寸并且自然可分离。然而,当在此视图中表示时,点云是稀疏的并且具有高度可变的点密度,这可能会导致检测器难以检测远处或小型物体(行人、交通标志等)。另一方面,透视图提供了密集的观察,这可以为这种情况提供更有利的特征编码。本文的目标是协同鸟瞰图和透视图,并提出一种新颖的端到端多视图融合(MVF)算法,该算法可以有效地学习利用两者的互补信息。具体来说,引入了动态体素化,与现有的体素化方法相比,它具有四个优点:i)无需预先分配固定大小的张量; ii) 克服由于随机点/体素丢失导致的信息丢失; iii) 产生确定性的体素嵌入和更稳定的检测结果; iv)建立点和体素之间的双向关系,这可能为跨视图特征融合奠定自然基础。通过采用动态体素化,所提出的特征融合架构使每个点能够学习融合来自不同视图的上下文信息。 MVF 在点上运行,可以自然地扩展到使用 LiDAR 点云的其他方法。在新发布的 Waymo 开放数据集和 KITTI 数据集上广泛评估了 MVF 模型,并证明它比可比较的单视图 PointPillars 基线显着提高了检测精度。
引言
通过激光雷达传感器理解 3D 环境是自动驾驶所需的核心能力之一。大多数技术都采用某种形式的体素化,要么通过 3D 点云的自定义离散化(例如 Pixor ),要么通过学习的体素嵌入(例如 VoxelNet 、PointPillars )。后者通常涉及汇集来自同一体素的各点的信息,然后用有关其邻居的上下文信息来丰富每个点。然后,这些体素化特征被投影到与标准 2D 卷积兼容的鸟瞰图 (BEV) 表示形式。在 BEV 空间中操作的好处之一是它保留了度量空间,即物体大小相对于距传感器的距离保持恒定。这允许模型在训练期间利用有关对象大小的先验信息。另一方面,随着点云变得越来越稀疏或者随着测量距离传感器越来越远,可用于每个体素嵌入的点的数量变得更加有限。
最近,在利用透视距离图像方面取得了很多进展,这是原始 LiDAR 数据的更原生的表示(例如 LaserNet)。这种表示法已被证明在点云变得非常稀疏的较长范围内表现良好,尤其是在小物体上。通过对“密集”距离图像进行操作,这种表示的计算效率也非常高。然而,由于透视性质,对象形状不是距离不变的,并且对象可能在杂乱的场景中彼此严重重叠。
其中许多方法利用 LiDAR 点云的单一表示,通常是 BEV 或距离图像。由于每种视图都有自己的优点,一个自然的问题是如何将多个 LiDAR 表示组合到同一个模型中。有几种方法着眼于将 BEV 激光数据与透视 RGB 图像相结合,无论是在 ROI 池化阶段(MV3D 、AVOD )还是在每点级别(MVX-Net)。与组合来自两个不同传感器的数据的想法不同,本文重点关注如何融合同一传感器的不同视图为模型提供比单个视图本身更丰富的信息。
在本文中,做出了两项主要贡献。首先,提出了一种新颖的端到端多视图融合(MVF)算法,该算法可以利用同一 LiDAR 点云的 BEV 和透视视图之间的互补信息。受到学习生成每点嵌入的模型强大性能的激励,设计了融合算法以在早期阶段运行,其中网络仍然保留点级表示(例如,在 VoxelNet 中的最终池化层之前)。现在,每个单独的 3D 点都成为跨视图共享信息的渠道,这是构成多视图融合基础的关键思想。此外,可以为每个视图定制嵌入类型。对于 BEV 编码,使用垂直列体素化(即 PointPillars),它已被证明在准确性和延迟方面提供了非常强大的基线。对于透视嵌入,在“类范围图像”特征图上使用标准的 2D 卷积塔,它可以跨大感受野聚合信息,有助于缓解点稀疏问题。现在,每个点都从 BEV 和透视图中注入了有关其邻居的上下文信息。这些点级嵌入最后一次汇集以生成最终的体素级嵌入。由于 MVF 增强了点级别的特征学习,因此本文的方法可以方便地合并到其他基于 LiDAR 的检测器中。
本文的第二个主要贡献是动态体素化 (DV) 的概念,与传统体素化(即硬体素化 (HV) 相比,它具有四个主要优点:
- DV 无需对每个体素预定义数量的点进行采样。这意味着模型可以使用每个点,从而最大限度地减少信息丢失。
- 它消除了将体素填充到预定义大小的需要,即使它们的点明显较少。这可以大大减少 HV 的额外空间和计算开销,尤其是在点云变得非常稀疏的较长范围内。例如,之前的模型(如 VoxelNet 和 PointPillars)为每个体素(或每个等效的 3D 体积)分配 100 个或更多点。
- DV 克服了点/体素的随机丢失,并产生确定性的体素嵌入,从而带来更稳定的检测结果。
- 它是融合来自多个视图的点级上下文信息的自然基础。
MVF 和动态体素化能够显着提高最近发布的 Waymo 开放数据集和 KITTI 数据集的检测精度。
相关工作
2D Object Detection. : 从 R-CNN 检测器开始,研究人员开发了许多基于卷积神经网络(CNN)的现代检测器架构。其中,有两个代表性分支:两阶段检测器和单阶段检测器。开创性的 Faster RCNN 论文提出了一个两阶段检测器系统,由生成候选对象提案的区域提案网络 (RPN) 和处理这些提案以预测对象类别和回归边界框的第二阶段网络组成。在单级探测器中, SSD 同时对密集集中的哪些锚框包含感兴趣的对象进行分类,并回归它们的维度。就推理时间而言,单阶段检测器通常比两级检测器更有效,但在 MSCOCO等公共基准上,与两阶段检测器相比,它们的精度略低,尤其是在较小的物体上。最近证明在单阶段检测器上使用焦点损失函数在准确性和推理时间方面可以比两阶段方法获得更优越的性能。
3D Object Detection in Point Clouds. : 处理 LiDAR 生成的点云的一种流行范例是将其投影到鸟瞰图 (BEV) 中并将其转换为多通道 2D 伪图像,然后可以通过 2D CNN 架构处理 2D 和 3D 目标检测。转换过程通常是手工设计的,一些代表性的作品包括Vote3D、Vote3Deep、3DFCN、AVOD、PIXOR和Complex YOLO。由 Zhou 等人设计的 VoxelNet,将点云划分为 3D 体素网格(即体素),并使用类似 PointNet 的网络学习每个体素内点的嵌入。 PointPillars基于 VoxelNet 的思想构建,对Pillar(即垂直柱)上的点特征进行编码。后来提出了一种利用两阶段pipeline的 PointRCNN 模型,其中第一阶段产生 3D 边界框提案,第二阶段细化规范 3D 框。透视图是 LiDAR 的另一种广泛使用的表示形式。沿着这条研究路线,一些代表性的工作是 VeloFCN 和 LaserNet 。
Multi-Modal Fusion. : 除了仅使用 LiDAR 之外,MV3D 还结合了从多个视图(前视图、鸟瞰图以及摄像机视图)提取的 CNN 特征来提高 3D 物体检测精度。单独的工作,例如 Frustum PointNet 和 PointFusion ,首先使用标准图像检测器从 RGB 图像生成 2D 目标建议,并将每个 2D 检测框拉伸到 3D 视锥体,然后由类似 PointNet 的网络来预测相应的 3D 边界框。 ContFuse 通过基于 3D 点邻域插值 RGB 特征,将离散 BEV 特征图与图像信息结合起来。 HDNET 将高程图信息与 BEV 特征图一起编码。 MMF通过多任务学习融合BEV特征图、高程图和RGB图像以提高检测精度。本文的工作引入了一种逐点特征融合的方法,该方法在点级别而不是体素或 ROI 级别上运行。这使得它能够在通过 ROI 或体素级池聚合点之前更好地保留 LiDAR 数据的原始 3D 结构。
Multi-View Fusion
多视图融合
本文的多视图融合(MVF)算法由两个新颖的组件组成:动态体素化和特征融合网络架构。
体素化和特征编码
体素化将点云划分为均匀间隔的体素网格,然后在 3D 点与其各自的体素之间生成多对一映射。 VoxelNet 将体素化表述为两个阶段的过程:分组和采样。给定点云 P = {p1, . , pN},该过程将 N 个点分配给大小为 K×T×F 的缓冲区,其中 K 是体素的最大数量,T 是体素中的最大点数,F 表示特征维度。在分组阶段,点{pi}根据空间坐标分配给体素{vj}。由于体素可能被分配比其固定点容量 T 允许的更多的点,因此采样阶段从每个体素中对固定 T 个点进行子采样。类似地,如果点云产生的体素多于固定体素容量 K,则对体素进行二次采样。另一方面,当点(体素)少于固定容量T(V)时,缓冲器中未使用的条目被零填充。本文将此过程称为硬体素化。
将 Fv(pi) 定义为将每个点 pi 分配给该点所在的体素 vj 的映射,并将 FP(vj) 定义为收集体素 vj 内的点的映射。形式上,硬体素化可以概括为:
硬体素化(HV)具有三个固有的局限性:(1)由于点和体素在超过缓冲区容量时被丢弃,HV 迫使模型丢弃可能对检测有用的信息; (2) 这种点和体素的随机丢失也可能导致体素嵌入的不确定性,从而导致检测结果不稳定或不稳定; (3) 填充的体素会消耗不必要的计算量,从而影响运行时性能。
本文引入动态体素化(DV)来克服这些缺点。 DV 保持分组阶段相同,但是,它不是将点采样到固定数量的固定容量体素中,而是保留了点和体素之间的完整映射。因此,体素的数量和每个体素的点数都是动态的,具体取决于特定的映射函数。这消除了对固定大小缓冲区的需要,并消除了随机点和体素丢失。点-体素关系可以形式化为:
由于保留了所有原始点和体素信息,动态体素化不会引入任何信息丢失并产生确定性体素嵌入,从而获得更稳定的检测结果。此外,Fv(pi) 和 Fp(vj) 在每对 pi 和 vj 之间建立双向关系,这为融合不同视图的点级上下文特征奠定了天然基础。
图 1 说明了硬体素化和动态体素化之间的主要区别。在此示例中,设置 K = 3 和 T = 5 作为点/体素覆盖率和内存/计算使用率之间的平衡权衡。这仍然使近一半的缓冲区为空。此外,由于随机采样,它会导致体素 v1 中的点丢失和体素 v2 的完全丢失。为了完全覆盖四个体素,硬体素化至少需要 4 × 6 × F 缓冲区大小。显然,对于具有高度可变点密度的现实世界 LiDAR 扫描,在点/体素覆盖范围和高效内存使用之间实现良好平衡将是硬体素化的一个挑战。另一方面,动态体素化动态且有效地分配资源来管理所有点和体素。在本文的例子中,它保证了空间的完全覆盖,并且内存占用最小为13F。完成体素化后,LiDAR 点可以通过[Pointnet,Voxelnet,Pointpillars]中报告的特征编码技术转换到高维空间。
Feature Fusion
Multi-View Representations. : 本文的目标是基于相同的激光雷达点云有效地融合来自不同视图的信息。考虑两种视图:鸟瞰图和透视图。鸟瞰视图是基于笛卡尔坐标系定义的,其中对象保留其规范的 3D 形状信息并且自然可分离。目前大多数具有硬体素化功能的 3D 目标检测器都在此视图中运行。然而,它的缺点是点云在较长距离内变得高度稀疏。另一方面,透视图可以密集地表示LiDAR距离图像,并且可以在球面坐标系中具有相应的场景平铺。透视图的缺点是对象形状不是距离不变的,并且在杂乱的场景中对象可能会彼此严重重叠。因此,需要利用两种观点的补充信息。
到目前为止,已经将每个体素视为鸟瞰图中的长方体形状。在这里,建议将传统体素扩展到更通用的想法,在本文的例子中,在透视图中包含 3D 平截头体。给定一个点云 {(xi, yi, zi) | i= 1,,,N}cart 定义在笛卡尔坐标系中,其球坐标表示计算为:
对于激光雷达点云,在鸟瞰图和透视图中应用动态体素化将暴露不同局部邻域内的每个点,即笛卡尔体素和球面平截头体,从而允许每个点利用互补的上下文信息。对于鸟瞰图和透视图,建立的点/体素映射分别为(Fcart V (pi)、Fcart P (vj))和(Fsphe V (pi)、Fsphe P (vj))。
Network Architecture 网络架构
如图 2 所示,所提出的 MVF 模型以原始 LiDAR 点云作为输入。首先,计算点嵌入。对于每个点,计算其所属体素或截锥体中的局部 3D 坐标。来自两个视图的局部坐标和点强度在通过一个全连接 (FC) 层嵌入到 128D 特征空间之前被连接起来。 FC层由线性层、批量归一化(BN)层和线性激活单元(ReLU)层组成。然后,在鸟瞰图和透视图中应用动态体素化,并建立点和体素之间的双向映射(FV(pi)和FP(vj)),其中 * ∈ {cart ,sphe}。
接下来,在每个视图中,使用一个额外的 FC 层来学习 64 维的视图相关特征,并通过引用 F*V(pi),通过最大池化从每个体素内的点聚合体素级信息。在这个体素级特征图上,使用卷积塔进一步处理上下文信息,其中输入和输出特征维度均为 64。最后,使用点到体素映射 F*P(vj),融合每个点来自三个不同信息源的特征:1)来自鸟瞰图的点对应的笛卡尔体素,2)来自透视图的点对应的球形体素,以及3)来自共享FC层的逐点特征。可以选择将逐点特征转换为较低的特征维度,以降低计算成本。
卷积塔的架构如图 3 所示。应用两个 ResNet 层,每个层具有 3 × 3 2D 卷积核和步幅大小 2,将输入体素特征图逐渐下采样为具有原始特征图尺寸 1/2 和 1/4的张量。然后,对这些张量进行上采样并连接以构建与输入具有相同空间分辨率的特征图。最后,将该张量转换为所需的特征维度。请注意,输入和输出特征图之间一致的空间分辨率有效地确保了点/体素对应关系保持不变。
Loss Function
本文使用与 SECOND 和 PointPillars 相同的损失函数。将真实值和锚框分别参数化为(xg,yg,zg,lg,wg,hg,θg)和(xa,ya,za,la,wa,ha,θa)。真实值和锚点之间的回归残差定义为:
总体回归损失为:
在训练过程中,使用 Adam 优化器并将余弦衰减应用于学习率。初始学习率设置为 1.33 × 10的−3次方,并在第一个 epoch 期间升至 1.5 × 10的−3次方。训练在 100 个 epoch 后结束。文章来源:https://www.toymoban.com/news/detail-817020.html
结论
本文介绍了 MVF,这是一种新颖的端到端多视图融合框架,用于从 LiDAR 点云进行 3D 对象检测。与使用硬体素化的现有 3D LiDAR 探测器相比,提出动态体素化,可以保留完整的原始点云,产生确定性体素特征,并作为融合不同视图信息的自然基础。提出了一种多视图融合架构,可以使用从不同视图中提取的更具辨别力的上下文信息来编码点特征。 Waymo 开放数据集和 KITTI 数据集上的实验结果表明,动态体素化和多视图融合技术显着提高了检测精度。添加相机数据和时间信息是令人兴奋的未来方向,这可能进一步改进本文的检测框架。文章来源地址https://www.toymoban.com/news/detail-817020.html
到了这里,关于[论文阅读]MVF——基于 LiDAR 点云的 3D 目标检测的端到端多视图融合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[论文阅读]MVX-Net——基于3D目标检测的多模态VoxelNet](https://imgs.yssmx.com/Uploads/2024/02/728981-1.png)
![[论文阅读]Voxel R-CNN——迈向高性能基于体素的3D目标检测](https://imgs.yssmx.com/Uploads/2024/02/731110-1.png)
![[论文阅读]MV3D——用于自动驾驶的多视角3D目标检测网络](https://imgs.yssmx.com/Uploads/2024/02/721503-1.png)