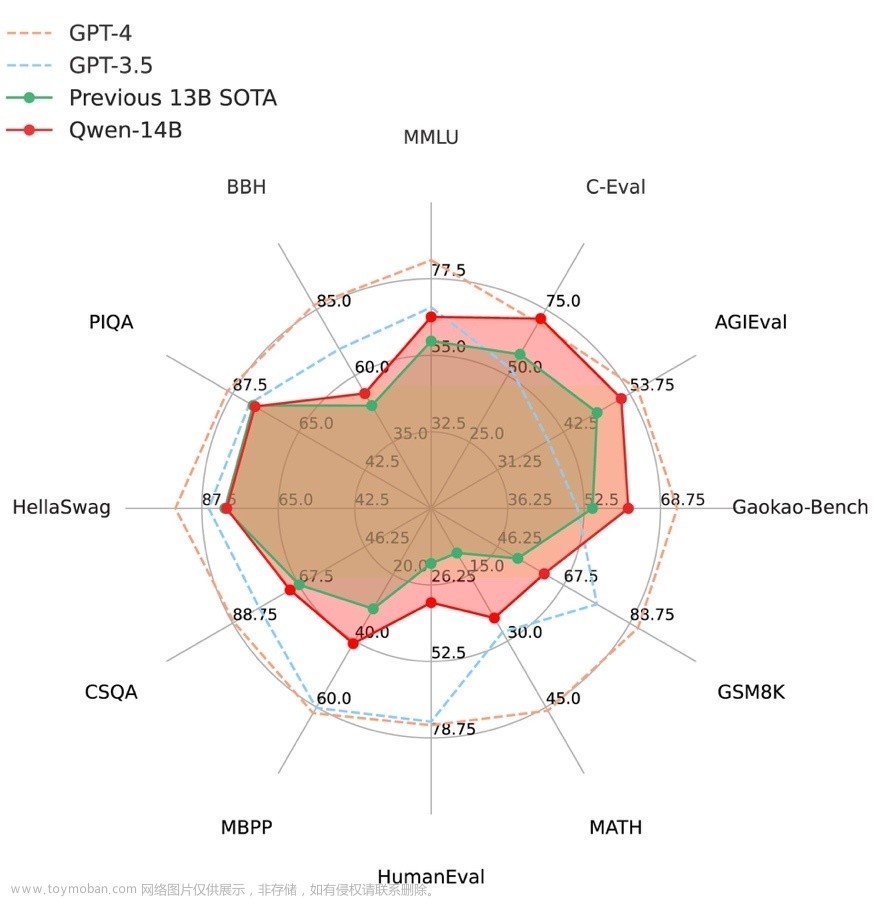
摘要:
本文介绍了使用微调技术进行自然语言生成的方法。通过使用transformers库中的AutoModelForCausalLM和AutoTokenizer,可以在多节点环境下进行微调。
训练数据的准备
你需要将所有样本放到一个列表中并存入json文件中。每个样本对应一个字典,包含id和conversation,其中后者为一个列表。示例如下所示:
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是一个语言模型,我叫通义千问。"
}
]
}
]微调方法分析
微调脚本能够帮你实现三种微调方法:文章来源:https://www.toymoban.com/news/detail-817023.html
- 全参数微调
- LoRA
- Q-LoRA
【全参数微调在训练过程中更新所有参数。】
"全参数微调"是一种在机器学习中用于优化预训练模型的技术。这种技术涉及在特定数据集上继续训练,更新模型的所有参数,以提高模型在特定任务上的性能。"参数"在这里指的是模型中的权重和偏置,它们决定了模型的行为和输出。在训练过程中,通过不断调整这些参数,模型文章来源地址https://www.toymoban.com/news/detail-817023.html
到了这里,关于【通义千问】大模型Qwen GitHub开源工程学习笔记(5)-- 模型的微调【全参数微调】【LoRA方法】【Q-LoRA方法】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!