作者:来自 Elastic Carly Richmond

来自不健康应用程序服务的重复事件使日志搜索变得棘手。 查看如何使用 Logstash、Beats 和 Elastic Agent 处理重复项。
使用 Elasticsearch 进行日志重复数据删除
SRE 每天都会被来自嘈杂应用程序的大量日志淹没。 Frederick P. Brooks 在他的开创性著作《人月神话》中说,“所有程序员都是乐观主义者”。 这种乐观态度体现在软件工程师没有采取控制措施来阻止其应用程序在异常故障情况下发送连续日志。 在拥有集中式日志记录平台的大型组织中,大量事件被吸收到日志记录平台中,并占用大量存储量和处理计算。 在人员方面,这让 SRE 感到不知所措,并遭受警报疲劳,因为他们被消息浪潮吞没,有点像这样:

构建包括微服务和关键应用程序在内的软件的开发人员有责任确保他们不发送重复的日志事件,并且在正确的级别发送正确的日志事件。 然而,使用第三方解决方案或维护老化服务等情况意味着我们不能始终保证采用负责任的日志记录实践。 即使我们按照本文中关于从传入日志事件中修剪字段的内容删除不必要的字段,我们仍然存在存储大量重复事件的问题。 在这里,我们讨论从有问题的服务中识别重复日志的挑战,以及如何使用 Elastic Beats、Logstash 和 Elastic Agent 删除重复数据。
什么是重复日志条目?
在深入研究防止这些重复项进入你的日志平台的各种方法之前,我们需要了解什么是重复项。 在我之前担任软件工程师时,我负责开发和维护庞大的微服务生态系统。 有些人考虑过重试逻辑,在一段时间后,将正常关闭服务并触发适当的警报。 然而,并非所有服务都是为了妥善处理这些情况而构建的。 服务配置错误也会导致事件重复。 无意中将生产日志级别从 WARN 更改为 TRACE 可能会导致日志记录平台必须处理更严重的事件量。
Elasticsearch 会自动为摄取的每个文档生成唯一 ID,除非文档在摄取时包含 _id 字段。 因此,如果你的服务发送重复的警报,你将面临将同一事件存储为具有不同 ID 的多个文档的风险。 另一个原因可能是用于日志收集的工具的重试机制。 一个值得注意的例子是 Filebeat,其中丢失的连接或关闭可能会导致 Filebeat 的重试机制重新发送事件,直到输出确认收到事件。
Elasticsearch 中出现重复的原因是什么?
当 Filebeat 输出被阻止时,Filebeat 中的重试机制会尝试重新发送事件,直到输出确认这些事件。 如果输出接收到事件,但无法确认它们,则数据可能会多次发送到输出。 由于文档 ID 通常由 Elasticsearch 在接收到来自 Beats 的数据后设置,因此重复事件将被索引为新文档。
工具概述
在本博客中,我们将研究四种 Elastic 工具中可用的工具:
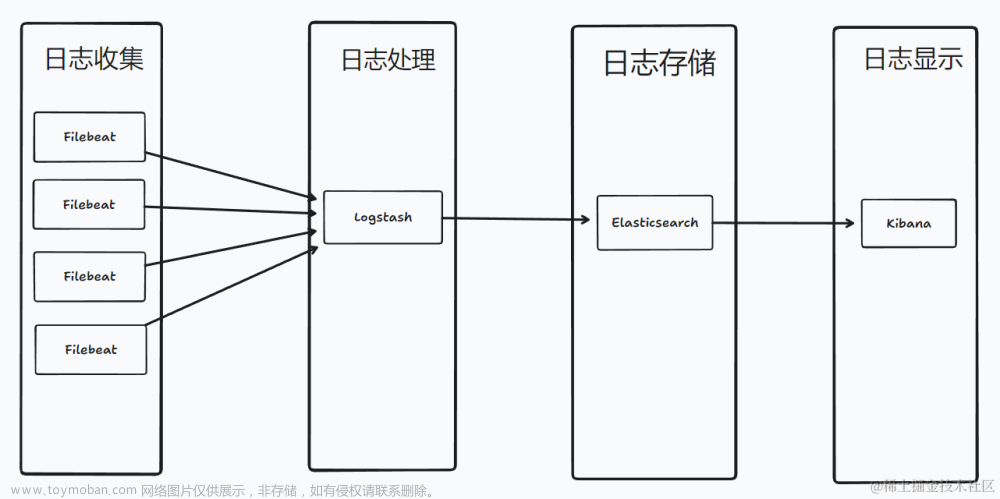
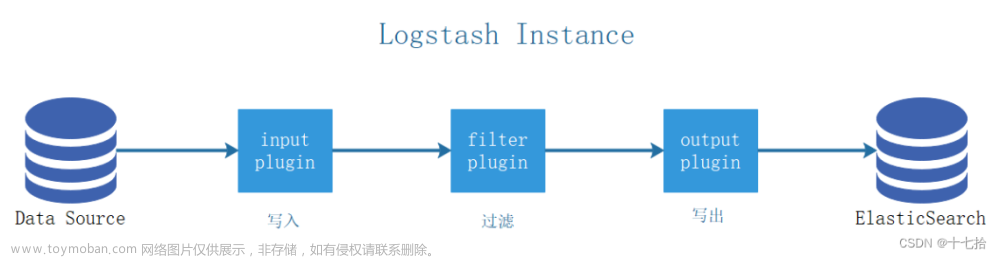
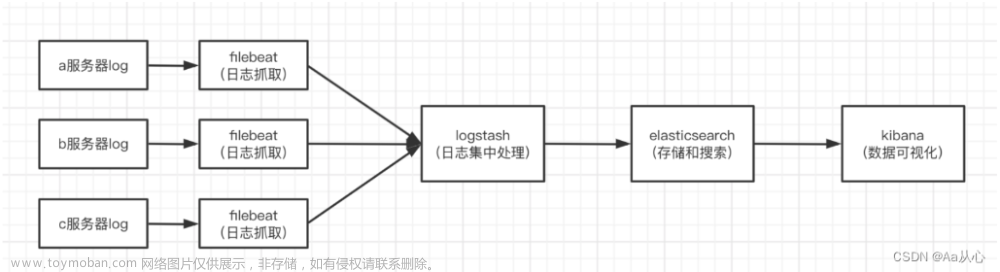
- Logstash 是一个免费、开放的 ETL 管道工具,允许您在无数源之间摄取、转换和输出数据,包括从 Elasticsearch 摄取和输出。 这些示例将用于展示 Elasticsearch 在生成带有和不带有特定 ID 的日志时的不同行为。更多描述关于如何使用 Logstash 的文章请阅读 “Logstash:Logstash 入门教程 (一)”。
- Beats 是一系列轻量级托运程序,使我们不仅可以将给定源的事件摄取到 Elasticsearch 中,还可以将事件摄取到其他输出中,包括 Kafka、Redis 或 Logstash。更多描述如何使用 Beats 的文章请详细阅读文章 “Beats:Beats 入门教程 (一)”。
- Ingest pipeline 允许将转换和丰富应用于摄取到 Elasticsearch 中的文档。 这就像将 Logstash 的 filter 部分直接运行到 Elasticsearch 中,而不需要运行其他服务。 可以在 Stack Management > Ingest Pipelines 页面中或通过 _ingest API 创建新管道,如文档中所述。
- Elastic Agent 是一个单一代理,可以在你的主机上执行,并使用各种受支持的集成将日志、指标和安全数据从多个服务和基础设施发送到 Elasticsearch。 无论重复的原因是什么,Elastic 生态系统中都有几种可能的行动方案。
没有指定 ID 的摄取
默认方法是忽略并摄取所有事件。 当文档上未指定 ID 时,Elasticsearch 将为收到的每个文档自动生成一个新 ID。 让我们举一个简单的例子,可以在这个 GitHub 存储库中找到,使用简单的 Express HTTP 服务器。 服务器在运行时公开一个端点,返回一条日志消息:
{"event":{"transaction_id":1,"data_set":"my-logging-app"},"message":"WARN: Unable to get an interesting response"}使用 Logstash,我们可以每 60 秒轮询一次端点 http://locahost:3000/ 并将结果发送到 Elasticsearch。 我们的 logstash.conf 如下所示:
logstash.conf
input {
http_poller {
urls => {
simple_server => "http://localhost:3000"
}
request_timeout => 60
schedule => { cron => "* * * * * UTC"}
codec => "json"
}
}
output {
elasticsearch {
cloud_id => "${ELASTIC_CLOUD_ID}"
cloud_auth => "${ELASTIC_CLOUD_AUTH}"
index => "my-logstash-index"
}
}Logstash 将推送每个事件,并且事件上没有任何 ID,Elasticsearch 将生成一个新的 _id 字段作为每个文档的唯一标识符:
GET my-logstash-index/_search
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 11,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "my-logstash-index",
"_id": "-j83XYsBOwNNS8Sc0Bja",
"_score": 1,
"_source": {
"@version": "1",
"event": {
"transaction_id": 1,
"original": """{"event":{"transaction_id":1,"data_set":"my-logging-app"},"message":"WARN: Unable to get an interesting response"}""",
"data_set": "my-logging-app"
},
"message": "WARN: Unable to get an interesting response",
"@timestamp": "2023-10-23T15:47:00.528205Z"
}
},
{
"_index": "my-logstash-index",
"_id": "NT84XYsBOwNNS8ScuRlO",
"_score": 1,
"_source": {
"@version": "1",
"event": {
"transaction_id": 1,
"original": """{"event":{"transaction_id":1,"data_set":"my-logging-app"},"message":"WARN: Unable to get an interesting response"}""",
"data_set": "my-logging-app"
},
"message": "WARN: Unable to get an interesting response",
"@timestamp": "2023-10-23T15:48:00.314262Z"
}
},
// Other documents omitted
]
}
}此行为对于 Beats、Ingest Pipelines 和 Elastic Agent 来说是一致的,因为它们将发送收到的所有事件,无需额外配置。
自带 ID (Bring Your Own - ID)
使用现有 ID 为每个事件指定唯一 ID 会绕过上一节中讨论的 Elasticsearch ID 生成步骤。 提取已存在此属性的文档将导致 Elasticsearch 检查索引中是否存在具有此 ID 的文档,如果存在则更新该文档。 这确实会产生开销,因为需要搜索索引以检查是否存在具有相同 _id 的文档。 扩展上面的 Logstash 示例,可以通过在 Elasticsearch 输出插件中指定 document_id 选项来指定 Logstash 中的文档 ID 值,该插件将用于将事件提取到 Elasticsearch 中:
# http_poller configuration omitted
output {
elasticsearch {
cloud_id => "${ELASTIC_CLOUD_ID}"
cloud_auth => "${ELASTIC_CLOUD_AUTH}"
index => "my-unique-logstash-index"
document_id => "%{[event][transaction_id]}"
}
}这会将 _id 字段的值设置为 event.transaction_id 的值。 在我们的例子中,这意味着新文档将在摄取时替换现有文档,因为两个文档的 _id 均为 1:
GET my-unique-logstash-index/_search
{
"took": 48,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "my-unique-logstash-index",
"_id": "1",
"_score": 1,
"_source": {
"@timestamp": "2023-10-23T16:33:00.358585Z",
"message": "WARN: Unable to get an interesting response",
"@version": "1",
"event": {
"original": """{"event":{"transaction_id":1,"data_set":"my-logging-app"},"message":"WARN: Unable to get an interesting response"}""",
"data_set": "my-logging-app",
"transaction_id": 1
}
}
}
]
}
}根据工具的不同,可以通过多种方式指定 ID,这将在后续部分中进一步讨论。
Beats
对于 JSON 文档(这是许多日志源的常见格式),如果你的事件确实有一个有用且有意义的 ID,可以用作文档的唯一 ID 并防止重复条目,请使用decode_json_fields 处理器或 json .document_ID 输入设置,如文档中建议的那样。 当消息中的 JSON 字段中存在自然键时,此方法优于生成密钥。 这两种设置均显示在以下示例中:
filebeat.inputs:
- type: filestream
id: my-logging-app
paths:
- /var/tmp/other.log
- /var/log/*.log
json.document_id: "event.transaction_id"
# Alternative approach using decode_json_fields processor
processors:
- decode_json_fields:
document_id: "event.transaction_id"
fields: ["message"]
max_depth: 1
target: ""更多关于如何使用 decode_json_fields,请参考 “Beats:使用 Filebeat 导入 JSON 格式的日志文件” 及 “Beats: 使用 Filebeat 进行日志结构化 - Python”。
摄取管道
在这种情况下,可以使用 set processor 结合 copy_from 选项来设置 ID,以将值从唯一字段传输到 Elasticsearch @metadata._id 属性:
PUT _ingest/pipeline/test-pipeline
{
"processors": [
{
"set": {
"field": "_id",
"copy_from": "transaction_id"
}
}
]
}Elastic Agent
Elastic Agent 有类似的方法,你可以使用 copy_fields 处理器将值复制到集成中的 @metadata._id 属性:
- copy_fields:
fields:
- from: transaction_id
to: @metadata._id
fail_on_error: true
ignore_missing: true当 fail_on_error 设置为 true 时,将通过恢复故障处理器应用的更改来返回到先前的状态。 同时,当 ignore_missing 设置为 false 时,只会对字段不存在的文档触发失败。
自动生成的 ID
Logstash
使用事件字段子集上的指纹识别(fingerprinting)等技术生成唯一 ID。 通过对一组字段进行哈希处理,会生成一个唯一值,当匹配时,将导致在 Elasticsearch 中摄取时更新原始文档。 正如这篇关于使用 Logstash 处理重复项的文章特别概述的那样,fingerprint filter plugin 可以配置为使用指定的哈希算法生成 ID 以字段 @metadata.fingerprint:
filter {
fingerprint {
source => ["event.start_date", "event.data_set", "message"]
target => "[@metadata][fingerprint]"
method => "SHA256"
}
}
output {
elasticsearch {
hosts => "my-elastic-cluster.com"
document_id => "%{[@metadata][fingerprint]}"
}
}你可以详细参考文章 “Logstash:运用 Elastic Stack 分析 CSDN 阅读量” 来更进一步了解如何使用。
如果未指定,将使用默认哈希算法 SHA256 对组合 |event.start_date|start_date_value|event.data_set|data_set_value|message|message_value| 进行哈希处理。 如果我们想使用其他允许的算法选项之一,可以使用 method 选项指定。 这将导致 Elasticsearch 更新与生成的 _id 匹配的文档:
GET my-fingerprinted-logstash-index/_search
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "my-fingerprinted-logstash-index",
"_id": "b2faceea91b83a610bf64ac2b12e3d3b95527dc229118d8f819cdfaa4ba98af1",
"_score": 1,
"_source": {
"@timestamp": "2023-10-23T16:46:00.772480Z",
"message": "WARN: Unable to get an interesting response",
"@version": "1",
"event": {
"original": """{"event":{"transaction_id":1,"data_set":"my-logging-app"},"message":"WARN: Unable to get an interesting response"}""",
"data_set": "my-logging-app",
"transaction_id": 1
}
}
}
]
}
}如果你的事件没有单个有意义的标识字段,并且你愿意承担生成 ID 的处理开销,或者不同事件解析为相同生成的哈希时可能发生冲突,那么这可能是一个有用的选项。 类似的功能可用于其他工具,如后续部分所述。
Beats
Beats 和 Elastic Agent 的 add_id processor 将允许生成唯一的 Elasticsearch 兼容 ID。 默认情况下,该值将存储在 @metadata._id 字段中,该字段是 Elasticsearch 文档的 ID 字段。
filebeat.inputs:
- type: filestream
ID: my-logging-app
paths:
- /var/tmp/other.log
- /var/log/*.log
json.document_ID: "event.transaction_id"
processors:
- add_ID: ~
target_field: @metadata._id或者,fingerprint processor生成由 | 操作符分隔的指定字段名称和值对串联而成的散列值。
filebeat.inputs:
- type: filestream
ID: my-logging-app
paths:
- /var/tmp/other.log
- /var/log/*.log
processors:
- fingerprint:
fields: ["event.start_date", "event.data_set", "message"]
target_field: "@metadata._id"
method: "sha256"
ignore_missing: false在上面的示例中,默认哈希算法 sha256 将用于对组合 |event.start_date|start_date_value|event.data_set|data_set_value|message|message_value| 进行哈希处理。 如果我们想使用其他允许的算法选项之一,可以使用 method 选项指定。 错误处理也是一个重要的考虑因素,ignore_missing 选项可以提供帮助。 例如,如果给定文档中不存在 event.start_date 字段,则当 ignore_missing 设置为 false 时将引发错误。 如果没有显式设置 ignore_missing,这是默认实现,但通常通过将该值指定为 true 来忽略错误。
Elastic Agent
就像 Beats 一样,Elastic Agent 有一个 add_id processor,可用于生成唯一 ID,如果未指定 target_field 属性,则默认为 @metadata._id:
- add_id:
target_field: "@metadata._id"另外,fingerprint processor 也可在 Elastic Agent 中使用,并且可应用于包含高级配置部分(包括处理器选项)的任何集成部分。 处理器逻辑如下所示:
- fingerprint:
fields: ["event.start_date", "event.data_set", "message"]
target_field: "@metadata._id"
ignore_missing: false
method: "sha256"以 Kafka 集成为例,上面的处理器片段可以应用在高级配置部分的处理器段中,用于从 Kafka 代理收集日志:
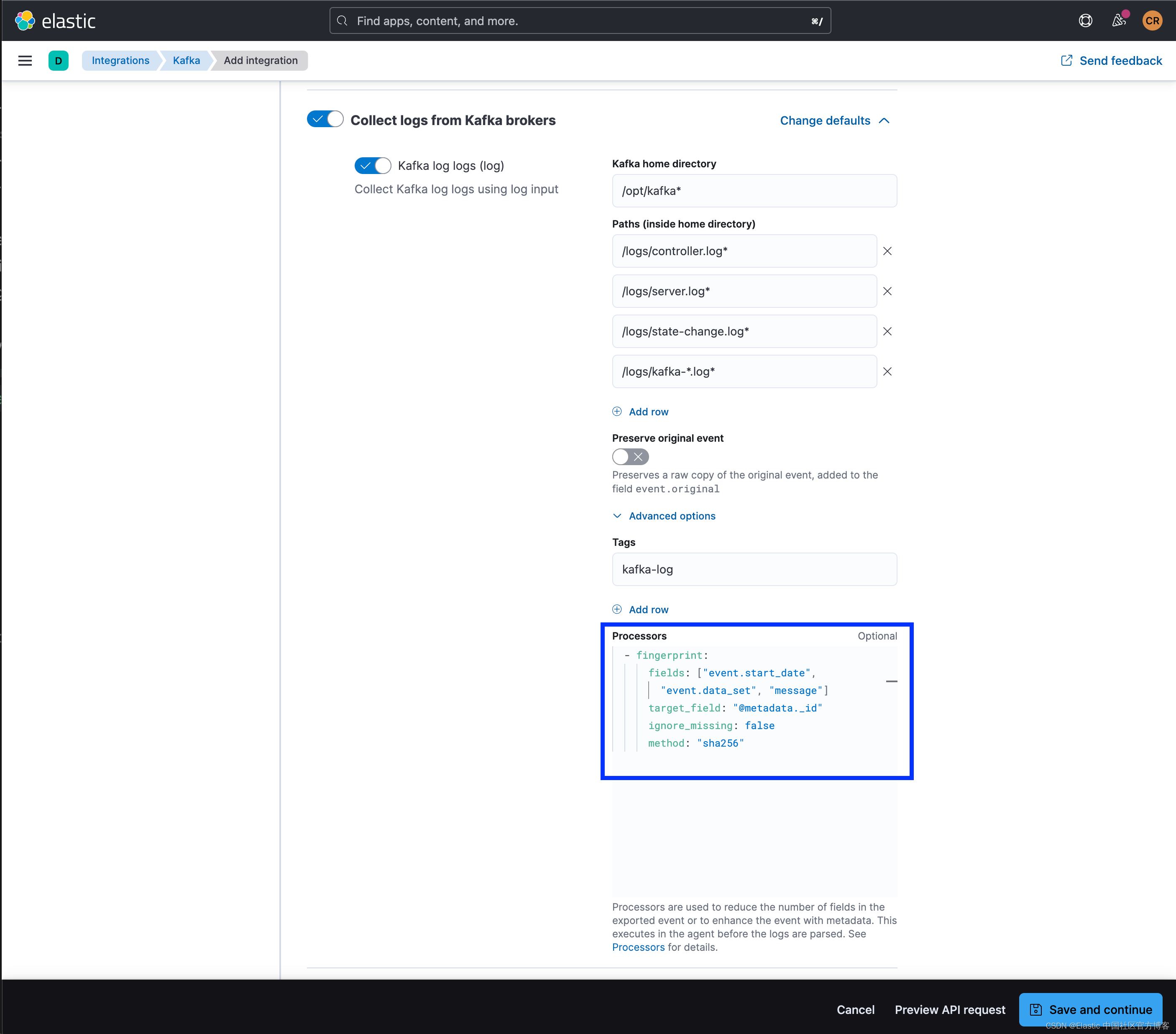
就像 Beats 一样,被哈希的值是由字段名称和字段值串联而成,并用 | 分隔。 例如 |field1|value1|field2|value2|。 然而,就像在 Beats 中一样,与在 Logstash 中不同,尽管支持相同的编码算法,但 method 值是小写的。
摄取管道
在这里,我们将展示使用 _ingest API 创建带有 fingerprint processor 的管道的示例请求。 请注意以下配置与我们的 Beats 处理器的相似之处:
PUT _ingest/pipeline/my-logging-app-pipeline
{
"description": "Event and field dropping for my-logging-app",
"processors": [
{
"fingerprint": {
fields: ["event.start_date", "event.data_set", "message"]
target_field: "@metadata._id"
ignore_missing: false
method: "SHA-256"
}
}
]
}聚合事件
如果使用的工具支持的话,基于公共字段将事件聚合在一起是另一种选择。 事件聚合需要权衡,因为该工具需要在内存中保留多个事件来执行聚合,而不是立即将事件转发到输出。 因此,Elastic 生态系统中唯一支持事件聚合的工具是 Logstash。
要在 Logstash 中实现基于聚合的方法,请使用 aggregation plugin。 在我们的例子中,不太可能发送特定的结束事件来区分重复项,这意味着需要按照以下示例指定 timeout 来控制批处理过程:
filter {
grok {
match => [ "message", %{NOTSPACE:event.start_date} "%{LOGLEVEL:loglevel} - %{NOTSPACE:user_ID} - %{GREEDYDATA:message}" ]
}
aggregate {
task_ID => "%{event.start_date}%{loglevel}%{user_ID}"
code => "map['error_count'] ||= 0; map['error_count'] += 1;"
push_map_as_event_on_timeout => true
timeout_task_ID_field => "user_id"
timeout => 600
timeout_tags => ['_aggregatetimeout']
timeout_code => "event.set('has_multiple_occurrences', event.get('error_count') > 1)"
}
}上面的示例将在 600 秒或 10 分钟后发送事件,并向事件添加 error_count 和 has_multiple_occurrences 属性以指示聚合事件。 Push_map_as_event_on_timeout 选项将确保在每次超时时推送聚合结果,从而允许你减少警报量。 在确定数据的超时时,请考虑你的数据量并选择尽可能低的超时,因为 Logstash 会将事件保留在内存中,直到超时到期并推送聚合事件。
结论
日志量峰值可能会很快淹没日志平台和希望维护可靠应用程序的 SRE 工程师。 我们已经讨论了使用 Elastic Beats、Logstash(可在此 GitHub 存储库中找到)和 Elastic Agent 处理重复事件的几种方法。
当使用 fingerprint processor 通过哈希算法生成 ID 或执行聚合时,请仔细考虑用于平衡防止洪水和混淆指向你生态系统中大规模问题的合法流的属性。 这两种方法都有一定的开销,要么是生成 ID 的处理,要么是存储符合聚合条件的文档的内存开销。
选择一个选项实际上取决于您考虑重复的事件和性能权衡。 如前所述,当你指定 ID 时,Elasticsearch 需要在将文档添加到索引之前检查是否存在与该 ID 匹配的文档。 这会导致执行 _id 存在检查的摄取略有延迟。
使用哈希算法生成 ID 会增加额外的处理时间,因为在比较和可能摄取之前需要为每个事件生成 ID。 选择不指定 ID 会绕过此检查,因为 Elastic 将为你生成 ID,但会导致存储所有事件,从而增加你的存储空间。
放弃完整事件是一种合法的做法,本文未涉及。 如果您想删除日志条目以减少数量,请查看这篇关于从传入日志事件中修剪字段的文章。
如果此处未列出你最喜欢的重复事件删除方法,请告诉我们!
更多阅读:
-
Beats:如何避免重复的导入数据
-
Elasticsearch:消除 Elasticsearch 中的重复数据文章来源:https://www.toymoban.com/news/detail-817035.html
原文:Log deduplication with Elasticsearch | Elastic Blog文章来源地址https://www.toymoban.com/news/detail-817035.html
到了这里,关于使用 Elasticsearch 进行日志重复数据删除的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!