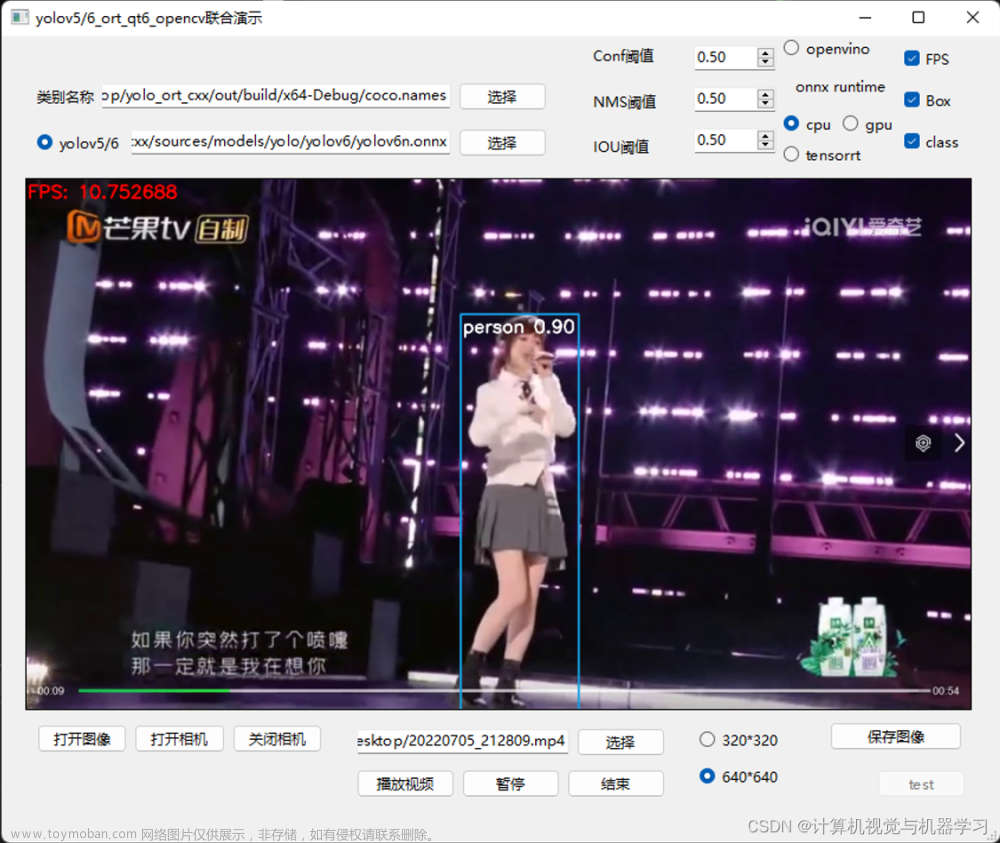
github开源代码地址
- yolov5官网还提供的dnn、tensorrt推理链接
- 本人使用的opencv c++ github代码,代码作者非本人,也是上面作者推荐的链接之一
- 如果想要尝试直接运行源码中的yolo.cpp文件和yolov5s.pt推理sample.mp4,请参考这个链接的介绍
使用github源码结合自己导出的onnx模型推理自己的视频
推理条件
windows 10
Visual Studio 2019
Nvidia GeForce GTX 1070
opencv 4.5.5、opencv4.7.0 (注意 4.7.0中也会出现跟yolov5 opencv dnn部署 github代码一样的问题)
yolov5 v6.1版本
c++部署
环境和代码的大致步骤跟yolov5 opencv dnn部署 github代码一样
在将所有前置布置好了之后,运行yolo.cpp的时候可能会出现图1problem的问题。
这个是由于yolov5 v6.1版本的问题,可以参考github源码中的issue的解决方案。当然,也可以按照下面的进行代码进行修改。
#include <fstream>
#include <opencv2/opencv.hpp>
std::vector<std::string> load_class_list()
{
std::vector<std::string> class_list;
std::ifstream ifs("./config_files/classes_fire.txt");
std::string line;
while (getline(ifs, line))
{
class_list.push_back(line);
}
return class_list;
}
void load_net(cv::dnn::Net &net, bool is_cuda)
{
auto result = cv::dnn::readNet("./config_files/yolov5n.onnx");
if (is_cuda)
{
std::cout << "Attempty to use CUDA\n";
result.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
result.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
}
else
{
std::cout << "Running on CPU\n";
result.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
result.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
}
net = result;
}
const std::vector<cv::Scalar> colors = {cv::Scalar(255, 255, 0), cv::Scalar(0, 255, 0), cv::Scalar(0, 255, 255), cv::Scalar(255, 0, 0)};
const float INPUT_WIDTH = 640.0;
const float INPUT_HEIGHT = 640.0;
const float SCORE_THRESHOLD = 0.2;
const float NMS_THRESHOLD = 0.4;
const float CONFIDENCE_THRESHOLD = 0.4;
struct Detection
{
int class_id;
float confidence;
cv::Rect box;
};
cv::Mat format_yolov5(const cv::Mat &source) {
int col = source.cols;
int row = source.rows;
int _max = MAX(col, row);
cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);
source.copyTo(result(cv::Rect(0, 0, col, row)));
return result;
}
// 所有的代码修改都在这个函数中
void detect(cv::Mat &image, cv::dnn::Net &net, std::vector<Detection> &output, const std::vector<std::string> &className) {
cv::Mat blob;
auto input_image = format_yolov5(image);
cv::dnn::blobFromImage(input_image, blob, 1./255., cv::Size(INPUT_WIDTH, INPUT_HEIGHT), cv::Scalar(), true, false);
net.setInput(blob);
std::vector<cv::Mat> outputs;
// 添加代码,使用opencv4.5.5的时候注释掉,使用opencv4.7.0可以使用
net.enableWinograd(false);
net.forward(outputs, net.getUnconnectedOutLayersNames());
float x_factor = input_image.cols / INPUT_WIDTH;
float y_factor = input_image.rows / INPUT_HEIGHT;
float *data = (float *)outputs[0].data;
const int dimensions = 85;
const int rows = 25200;
const int max_wh = 768; // 这个值是偏移量,这个酌情选择,不然太大会导致dnn:nms不工作
// 添加代码
int out_dim2 = outputs[0].size[2]; // 这里的是class+conf+xywh,相当于COCO的指标的85
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
std::vector<cv::Rect> boxes_muti;
for (int i = 0; i < rows; ++i) {
// 添加代码
int index = i * out_dim2; // 每一次循环索引都是下一个pre_box的初始位置
float confidence = data[4 + index]; // 修改代码 这样读取的值就是下一个的pre_box的conf
if (confidence >= CONFIDENCE_THRESHOLD) {
// 修改代码 这样读取的值就是下一个的pre_box的class
float * classes_scores = data + 5 + index;
cv::Mat scores(1, className.size(), CV_32FC1, classes_scores);
cv::Point class_id;
double max_class_score;
minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
max_class_score *= confidence; // conf = obj_conf * cls_conf
if (max_class_score > SCORE_THRESHOLD) {
confidences.push_back(max_class_score);
class_ids.push_back(class_id.x);
// 修改代码,这样读取的值就是下一个的pre_box的xywh
float x = data[0 + index];
float y = data[1 + index];
float w = data[2 + index];
float h = data[3 + index];
int left = int((x - 0.5 * w) * x_factor);
int top = int((y - 0.5 * h) * y_factor);
int width = int(w * x_factor);
int height = int(h * y_factor);
boxes.push_back(cv::Rect(left, top, width, height));
// 实现多分类NMS,如果不需要实现,就直接删掉该部分
// 在这里添加的是类似yolov5nms的class_id位置偏移
int left_muti = int((x - 0.5 * w) * x_factor + class_id.x * max_wh);
int top_muti = int((y - 0.5 * h) * y_factor + class_id.x * max_wh);
int width_muti = int(w * x_factor + class_id.x * max_wh);
int height_muti = int(h * y_factor + class_id.x * max_wh);
boxes_muti.push_back(cv::Rect(left_muti, top_muti, width_muti, height_muti));
}
}
}
std::vector<int> nms_result;
cv::dnn::NMSBoxes(boxes_muti, confidences, SCORE_THRESHOLD, NMS_THRESHOLD, nms_result);
for (int i = 0; i < nms_result.size(); i++) {
int idx = nms_result[i];
Detection result;
result.class_id = class_ids[idx];
result.confidence = confidences[idx];
result.box = boxes[idx];
output.push_back(result);
}
}
int main(int argc, char **argv)
{
std::vector<std::string> class_list = load_class_list();
cv::Mat frame;
cv::VideoCapture capture("sample_fire2.mp4");
// 如果想要将结果保存为视频
/*
cv::VideoWriter writer;
int coder = cv::VideoWriter::fourcc('M', 'J', 'P', 'G');
double fps_w = 25.0;//设置视频帧率
std::string filename = "fire.avi";//保存的视频文件名称
writer.open(filename, coder, fps_w, cv::Size(640, 360));//创建保存视频文件的视频流 Size(640, 360)是smaple_fire2.mp4的分辨率
*/
if (!capture.isOpened())
{
std::cerr << "Error opening video file\n";
return -1;
}
// 因为是window系统,且直接使用VStudio运行代码的,如果想使用cuda,直接将is_cuda = true即可
bool is_cuda = argc > 1 && strcmp(argv[1], "cuda") == 0;
cv::dnn::Net net;
load_net(net, is_cuda);
auto start = std::chrono::high_resolution_clock::now();
int frame_count = 0;
float fps = -1;
int total_frames = 0;
while (true)
{
capture.read(frame);
if (frame.empty())
{
std::cout << "End of stream\n";
break;
}
std::vector<Detection> output;
detect(frame, net, output, class_list);
frame_count++;
total_frames++;
int detections = output.size();
for (int i = 0; i < detections; ++i)
{
auto detection = output[i];
auto box = detection.box;
auto classId = detection.class_id;
const auto color = colors[classId % colors.size()];
cv::rectangle(frame, box, color, 3);
cv::rectangle(frame, cv::Point(box.x, box.y - 20), cv::Point(box.x + box.width, box.y), color, cv::FILLED);
cv::putText(frame, class_list[classId].c_str(), cv::Point(box.x, box.y - 5), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
if (frame_count >= 30)
{
auto end = std::chrono::high_resolution_clock::now();
fps = frame_count * 1000.0 / std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
frame_count = 0;
start = std::chrono::high_resolution_clock::now();
}
if (fps > 0)
{
std::ostringstream fps_label;
fps_label << std::fixed << std::setprecision(2);
fps_label << "FPS: " << fps;
std::string fps_label_str = fps_label.str();
cv::putText(frame, fps_label_str.c_str(), cv::Point(10, 25), cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(0, 0, 255), 2);
}
cv::imshow("output", frame);
// writer.write(frame); // 如果想要将结果保存为视频
if (cv::waitKey(1) != -1)
{
capture.release();
// writer.release(); // 如果想要将结果保存为视频
std::cout << "finished by user\n";
break;
}
}
std::cout << "Total frames: " << total_frames << "\n";
return 0;
}
c++ 推理结果
opencv 4.5.5
yolov5 v6.1 导出的是yolov5n.onnx
yolov5_deploy_fire
opencv 4.7.0
yolov5 v6.1 导出的是yolov5n.onnx
文章来源:https://www.toymoban.com/news/detail-817261.html
yolov5_deploy_fire2文章来源地址https://www.toymoban.com/news/detail-817261.html
到了这里,关于yolov5 opencv dnn部署自己的模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!