片外内存攻击面
- 攻击者通过操纵片外的未保护的内存
- 直接观察
- 解决方案:内存加密
- 篡改数据
- 任意修改(spoofing),拼接(splicing),重放(replay)
- 解决方案:完整性保护和防重放
- 观察地址总线的访问模式
- 侧信道
- 解决方案:ORAM
AES分组算法保护机密性
- 内存加密模式
- AES+ECB/CBC/CTR/XTS/GCM
- 可调分组密码:QARMA
1.ECB模式(电子密码本模式)
用相同的密钥分别对明文组加密;各个分组独立加密和解密。
优点:
算法简单,加解密速度快。
易于并行计算,因此在硬件中实现时非常高效。
缺点:
不支持并行加解密,因此安全性较差。
明文块内部存在重复,容易受到攻击。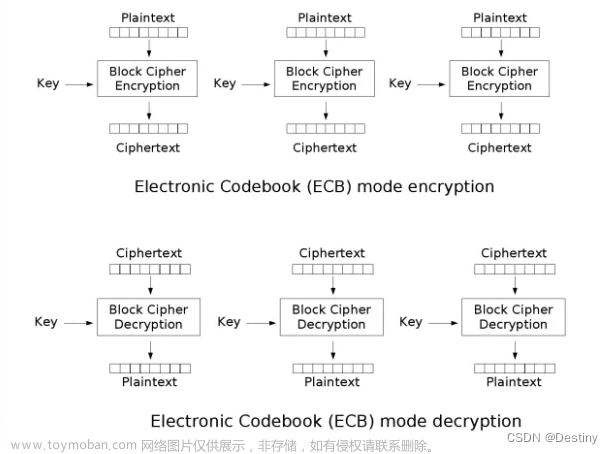
2.CBC模式(密码分组链接模式)
当前明文分组先和前一个密文异或,再加密;初始向量IV,不必保密,但需要保存并占据空间
优点:
相邻的明文块加密后的密文块是不同的,增加了加密的安全性。
可以处理变长的明文,适用性更广。
缺点:
加密过程是串行的,无法并行,不适合硬件加速。
初始向量IV必须是随机的,否则容易受到攻击。
3.CTR模式(计数器模式)
CTR模式是一种通过将逐次累加的计数器进行加密来生成密钥流的流密码。最终的密文分组是通过将计数器加密的到的比特序列,与明文分组进行XOR而得到的。
优点:不泄露明文;仅需实现加密函数;无需填充;可并行计算。
缺点:需要瞬时值IV,难以保证IV的唯一性。
4.CFB模式(密码反馈模式)
在CFB模式中,前一个密文分组会被送回到密码算法的输入端。所谓反馈,这里指的就是返回输入端的意思。类似于CBC,可以将块密码变为自同步的流密码;工作过程亦非常相似,CFB的解密过程几乎就是颠倒的CBC的加密过程:
优点:
支持加密和解密的输出反馈模式,因此可以进行流加密。
可以处理变长的明文,适用性更广。
缺点:
加密过程是串行的,不适合硬件加速。
密钥流的产生需要时间,因此加解密的时延较大。

5.OFB模式(输出反馈模式)
可以将块密码变成同步的流密码。它产生密钥流的块,然后将其与明文块进行异或,得到密文。与其它流密码一样,密文中一个位的翻转会使明文中同样位置的位也产生翻转。这种特性使得许多错误校正码,例如奇偶校验位,即使在加密前计算,而在加密后进行校验也可以得出正确结果。
密码反馈模式也需要一个初始量,无须保密,但对每条消息必须有一个不同的初始量。
优点:
支持加密和解密的输出反馈模式,因此可以进行流加密。
可以处理变长的明文,适用性更广。
缺点:
加密过程是串行的,不适合硬件加速。
密钥流的产生需要时间,因此加解密的时延较大。
需要注意的是,以上模式中,ECB模式安全性最差,CBC、CFB和OFB模式相对安全性更高,因此在选择加密模式时需要根据实际情况和安全需求进行选择。

6.XTS
- 明文和密钥之外,算法包括一个tweak作为输入
- 相比CBC、CTR等模式,不需要额外的存储IV和counter
- 整体与ECB类似,例如可以并行
- 但规避了ECB的缺点:频率分析攻击,密文替换攻击

- 但规避了ECB的缺点:频率分析攻击,密文替换攻击
保护完整性
- MAC
- SHA1/SHA3……
- 认证加密模式
- CTR+GMAC
- Counter需要保存、不能重复

Xom
Architectural Support for Copy and Tamper Resistant Software ASPLOS 2000
- 机密性
- CTR模式
- cipher = plain ⊕ encryptedkey(address || seq)
- plain = cipher ⊕ encryptedkey(address || seq)
- key = XOM ID
- address = virtual address of data/instruction
- seq = mutating sequence number
- encryptedkey(address + seq)的计算可以与内存访问并行,最终的计算只需要1个cycle进行异或
为什么需要address作为counter的一部分?
防止从一个内存地址复制合法的密文,替换到另外一个内存地址
- cipher = plain ⊕ encryptedkey(address || seq)
- plain = cipher ⊕ encryptedkey(address || seq)
Xom的问题:无法提供新鲜性保证
使用同一地址的旧的数据替换该地址的新的数据–>需要防重放攻击
新鲜性,Merkel Tree 防重放
Caches and Merkle Trees for Efficient Memory Integrity Verification. HPCA 2003 优化
优化
- 若每次都计算到根节点
- 4GB内存,128-bit hash,性能损失可以达到10倍
- 专门的cache结构,缓存了最近使用的内部hash块
- 不需要计算到根节点,只需要计算到查找到的中间节点
- 若中间节点被换出,则将其父节点放入cache,并更新父节点
- 平均22%,最坏52%
优化:Counter的压缩模式
Improving Cost, Performance, and Security of Memory Encryption and Authentication. ISCA 2006
-
CTR的问题
- 每次cache write back需要增加一次counte
- 每个chuck一个counter+addr
- 当counter溢出时,需要换一个AES key
- 但整个内存加密只有一个key,因此需要重新加密整个物理内存 – freeze the system

- 但整个内存加密只有一个key,因此需要重新加密整个物理内存 – freeze the system
- 每次cache write back需要增加一次counte
-
Counter = Major Counter || Minor Counter
- Major Counter
- 每个加密的页面内所有的数据块共享一个major counter
- 在系统的生命周期内都不会溢出(64 bit)
- Minor Counter
- 页面内每个数据块具有的独立的counter
- 长度较短,容易溢出,但溢出时只需要更换一个major counter,并重新加密该页面,而不是全部的物理内存
- Major Counter
-
Stored together in a counter cache line
- 存储开销为1/64=1.6%

- 存储开销为1/64=1.6%
-
使用GMAC优化完整性保护

优化:AISE
Using address Independent Seed Encryption and Bonsai Merkle Trees to Make Secure Processors OS- and Performance-Friendly. MICRO 2007
motivation
- 内存加密
- CTR模式可以隐藏内存访问关键路径的延迟,但是该模式下要求counter是唯一的
- 之前的工作,采用了地址(spatial uniqueness,va或pa)作为counter的一部分
- 每次write操作,counter+1,用于保证temporal uniqueness
- CTR模式可以隐藏内存访问关键路径的延迟,但是该模式下要求counter是唯一的
- 问题
- 使用物理地址,则每次page swapping都需要重新加密和解密
- 且需要增加额外的完整性保护机制
- 使用虚拟地址,但不同的进程可以使用同样的虚拟地址
- 若把每个进程的ID也作为counter的一部分
- 无法支持shared memory based IPC和shared library – process fork的copy on write的优化不可用,原因是parent/child的counter是不一样的
- 进程ID是由不信任的OS指定的
- 若把每个进程的ID也作为counter的一部分
- 使用物理地址,则每次page swapping都需要重新加密和解密
主要优化
- Address Independent Seed Encryption (AISE)
- 为每个页分配一个逻辑识别码(logical identifiers);与虚拟地址或物理地址无关,在整个系 统的生命周期确保对所有的内存页都是不同的
- 可以避免page swapping等的性能问题
- 可以支持shared memory/shared library等机制

- 为每个页分配一个逻辑识别码(logical identifiers);与虚拟地址或物理地址无关,在整个系 统的生命周期确保对所有的内存页都是不同的
- LPID
- 在页分配时分配的唯一值(unique value)
- 在生命周期(系统启动到关闭)内与页绑定,包括物理页和交换空间页
- Global Page Counter:64比特
- 无法篡改,几乎不会溢出
- LPID的存储:与压缩counter结合

- 以1个4KB的页为例,每个block为64字节,每个block的LPID长度为64比特,每个 block分配一个7比特的counter
- 若block counter溢出,则为该页分配一个新的LPID,并重新加密该页
- 存储开销为1/64=1.6%
其他优化方向
-
1.Merkle Tree的目的是防止replay attack,而CTR模式为每个block提供了一个 counter
- 如果我们能够保证counter的新鲜性(freshness),则可以保证数据的新鲜性
- 因此,只需要使用Merkle Tree保护counter的新鲜性

-
2.counter要比data小的多(64B v.s. 4KB),因此一个Tree node可以容纳更多的 counter
- cache压力更小,查询更快

- cache压力更小,查询更快
-
3.VAULT. ASPLOS 2018:增加可以支持的受保护内存大小
- EPC hit: 200 cycles;EPC miss 40K cycles
- SGX中树的每一层8个节点,VAULT使用了16到64个可变节点
- 压缩MAC的存储
- 16 GB受保护内存

-
4.Morphable Counters. MICRO 2018
- 根据应用程序的特点,每个cache line中的counter数量是动态可变的(counter的大小可变,之 前的方案都是固定的64个)
- 通过对counter做压缩,降低Merkle tree的大小以及占用的cache大小,减少counter溢出后的 重加密代价
- 16GB受保护内存

-
5.Synergy. HPCA 2018
- 将MAC放在ECC区域,对MAC的存取不需要额外的一次memory transaction
-
6.Compact Leakage-Free Support for Integrity and Reliability. ISCA 2020
- 对integrity tree中的metadata布局的优化,降低metadata miss的概率
现有TEE完整性保护
Intel SGX
A Memory Encryption Engine Suitable for General Purpose Processors文章来源:https://www.toymoban.com/news/detail-817435.html
- 只对counter进行完整性保护
- counter:包括时间和空间counter,没有做压缩

SGX V2/Scalable SGX
- 移除了基于Merkle Tree的完整性检查
- 利用ECC比特表明每个cache line是否属于某个enclave
- 降低了对片外存储的完整性保护
- 无法防御memory bus replay attacks
Intel TDX/MLTME/AMD SEV
- 使用XTS加密模式
- 使用物理地址作为tweak
- 同样的明文,在不同的物理地址,其密文是 不同的
- SEV
- 除加密外,不包含任何可以保护完整性的metadata
- 不知道密钥的情况下的任何修改,会使得其变为随机值
- 仍然可以被利用(*)
- 仅适用于AMD SEV-SNP之前的版本
- 逆向tweak后,可以使用已知的明文覆盖目标的物理地址
- 仅适用于AMD SEV-SNP之前的版本
- SEV-SNP防止了基于软件的完整性破坏
- 但是无法防御基于物理的内存完整性攻击(包括bus replay attack)
- 允许对加密数据进行读取,通过观察数据是否改变同样泄露信息
- TDX
- 为每个64B自动生成28-bit的截断的sha-3输出作为MAC
- MAC存储在DRAM ECC-bit之内,提供完整性保护
- 1个额外比特用于表明cache line是否属于某个TD
参考文献:
[1] https://zh.wikipedia.org/wiki/分组密码工作模式#
[2] https://heartever.github.io/files/understanding_tee_design.pdf文章来源地址https://www.toymoban.com/news/detail-817435.html
到了这里,关于【TEE】片外内存保护:AES分组算法+MAC完整性验证的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![《现代密码学》学习笔记——第三章 分组密码 [二] AES](https://imgs.yssmx.com/Uploads/2024/02/447027-1.png)