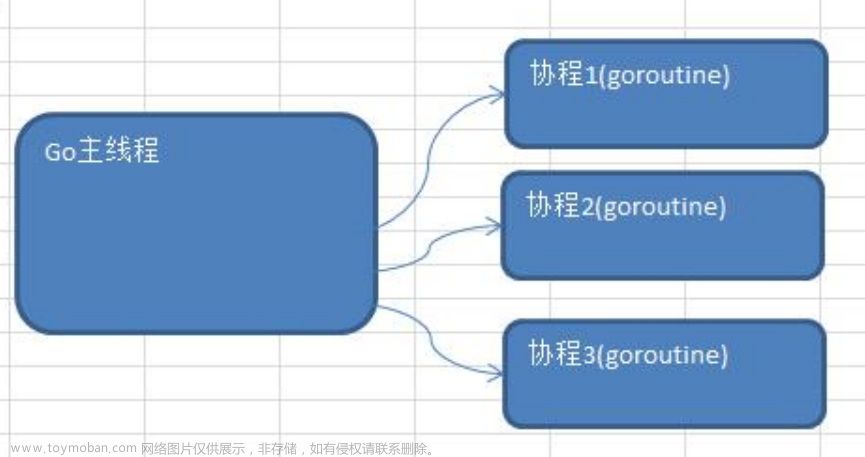
Go后端开发 – goroutine && channel
一、goroutine介绍
1.协程的由来
- 多进程操作系统
解决了阻塞的问题
存在切换成本

设计复杂

- 将一个线程分为用户线程和内核线程,CPU只能看到内核线程


- 使用协程调度器调度多个协程,形成N:1关系

- 多个线程管理多个协程,M:N,语言的重点就在于协程调度器的优化

2.Golang对协程的处理
- goroutine内存更小,可灵活调度

- Golang早期对调度器的处理

协程队列中有锁,对协程的运行进行保护,协程获取锁后,会从队首获取goroutine执行,剩余goroutine会向队列前方移动
当前goroutine执行完后,会放回队列尾部
老的调度器有几个缺陷:
-
GMP:Golang对调度器的优化
处理器是用来处理goroutine的,保存每个goroutine的资源
每个P都会管理一个goroutine的本地队列,M想获取协程需要从P获取;P的数量由GOMAXPROCS确定;
一个P同时只能执行一个协程;
还存在一个goroutine的全局队列,存放等待运行的协程;
当前程序最高并行的goroutine的数量就是P的数量;
Golang调度器的设计策略 - 复用线程:
work stealing机制
M1在执行G1,而M2是空闲的
M2就会从M1的本地队列中进行偷取,G3就会在M2中执行
hand off机制
若目前有两个M,M1中的G1被阻塞了,M2即将运行G3
此时会创建/唤醒一个thread M3,并将M1绑定的P切换到M3,阻塞的G1继续和M1绑定
- 利用并行
利用GOMAXPROCS限定P的个数
- 抢占
普通调度器的协程和CPU是绑定的,其他的协程会等待使用CPU资源,只有该协程主动释放资源,才会解绑CPU,为其他协程提供资源
goroutine是轮询机制,如果有其他协程等待资源,那么每个协程最高轮训10ms,时间一到,无论是否释放资源,新的协程都会抢占CPU资源
- 全局G队列
work stealing机制可以从全局队列中偷取协程
3.协程并发
协程:coroutine。也叫轻量级线程。
与传统的系统级线程和进程相比,协程最大的优势在于“轻量级”。可以轻松创建上万个而不会导致系统资源衰竭。而线程和进程通常很难超过1万个。这也是协程别称“轻量级线程”的原因。
一个线程中可以有任意多个协程,但某一时刻只能有一个协程在运行,多个协程分享该线程分配到的计算机资源。
多数语言在语法层面并不直接支持协程,而是通过库的方式支持,但用库的方式支持的功能也并不完整,比如仅仅提供协程的创建、销毁与切换等能力。如果在这样的轻量级线程中调用一个同步 IO 操作,比如网络通信、本地文件读写,都会阻塞其他的并发执行轻量级线程,从而无法真正达到轻量级线程本身期望达到的目标。
在协程中,调用一个任务就像调用一个函数一样,消耗的系统资源最少!但能达到进程、线程并发相同的效果。
在一次并发任务中,进程、线程、协程均可以实现。从系统资源消耗的角度出发来看,进程相当多,线程次之,协程最少。
4.Go并发
- Go 在语言级别支持协程,叫goroutine。Go 语言标准库提供的所有系统调用操作(包括所有同步IO操作),都会出让CPU给其他goroutine。这让轻量级线程的切换管理不依赖于系统的线程和进程,也不需要依赖于CPU的核心数量。
- 有人把Go比作21世纪的C语言。第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持并发。同时,并发程序的内存管理有时候是非常复杂的,而Go语言提供了自动垃圾回收机制。
- Go语言为并发编程而内置的上层API基于顺序通信进程模型CSP(communicating sequential processes)。这就意味着显式锁都是可以避免的,因为Go通过相对安全的通道发送和接受数据以实现同步,这大大地简化了并发程序的编写。
- Go语言中的并发程序主要使用两种手段来实现。goroutine和channel。
5.Goroutine
- goroutine是Go语言并行设计的核心,有人称之为go程。 Goroutine从量级上看很像协程,它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
- 一般情况下,一个普通计算机跑几十个线程就有点负载过大了,但是同样的机器却可以轻松地让成百上千个goroutine进行资源竞争。
创建Goroutine
- 只需在函数调⽤语句前添加 go 关键字,就可创建并发执行单元。开发⼈员无需了解任何执行细节,调度器会自动将其安排到合适的系统线程上执行。
- 在并发编程中,我们通常想将一个过程切分成几块,然后让每个goroutine各自负责一块工作,当一个程序启动时,主函数在一个单独的goroutine中运行,我们叫它
main goroutine。新的goroutine会用go语句来创建。而go语言的并发设计,让我们很轻松就可以达成这一目的。
实例:
package main
import (
"fmt"
"time"
)
//子goroutine
func newTask() {
i := 0
for {
i++
fmt.Println("new Goroutine : i =", i)
time.Sleep(1 * time.Second)
}
}
//主goroutine
func main() {
//创建一个go程,去执行newTask流程
go newTask()
i := 0
for {
i++
fmt.Println("main Goroutine : i =", i)
time.Sleep(1 * time.Second)
}
}

- 上述实例中,newTask是由创建的goroutine执行的,与main函数的goroutine是并发执行的
- main函数的goroutine是主goroutine;newTask的goroutine是子goroutine,其内存空间是依赖于main的主goroutine的,如果main退出,其他goroutine会被杀掉
使用匿名方法创建goroutine:
- 匿名函数:
func () {
//函数体
}() //匿名函数{}后面加()代表直接调用
实例:
package main
import (
"fmt"
"time"
)
// 主goroutine
func main() {
//用go创建承载一个形参为空,返回值为空的一个函数
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
//退出当前goroutine
fmt.Println("B")
}()
fmt.Println("A")
}()
//死循环
for {
time.Sleep(1 * time.Second)
}
}

Goexit函数
- 如果在子goroutine的函数中返回,则该goroutine会终止运行,如果在其子函数中return返回,则只会停止运行子函数,该goroutine不会终止运行;
- 如果想要在子函数中退出当前的goroutine,需要用
runtime.Goexit() - 调用 runtime.Goexit() 将立即终止当前 goroutine 执⾏,调度器确保所有已注册 defer 延迟调用被执行。
package main
import (
"fmt"
"runtime"
"time"
)
// 主goroutine
func main() {
//用go创建承载一个形参为空,返回值为空的一个函数
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
//退出当前goroutine
runtime.Goexit()
fmt.Println("B")
}()
fmt.Println("A")
}()
//死循环
for {
time.Sleep(1 * time.Second)
}
}

有参数的匿名函数
- 输入参数需要在匿名函数后面的运行()内传参
- 返回值不可以在匿名函数前直接赋值给变量,因为当前goroutine与主goroutine是并行的,主从goroutine具体执行是异步的,因此该赋值并不是一个阻塞操作

- 希望主goroutine能够获得子goroutine的返回值,就需要利用channel机制,来保证goroutine之间的通信
三、channel
1.channel介绍
- channel是Go语言中的一个核心类型,可以把它看成管道。并发核心单元通过它就可以发送或者接收数据进行通讯,这在一定程度上又进一步降低了编程的难度。
- channel是一个数据类型,主要用来解决go程的同步问题以及go程之间数据共享(数据传递)的问题。
- goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。goroutine 奉行通过通信来共享内存,而不是共享内存来通信。
- 引⽤类型 channel可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全

2.定义channel变量
和map类似,channel也是一个对应make创建的底层数据结构的引用。
-
当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。
-
定义一个channel时,也需要定义发送到channel的值的类型。channel可以使用内置的make()函数来创建
-
chan是创建channel所需使用的关键字。Type代表指定channel收发数据的类型。
make(chan Type) //等价于make(chan Type, 0)
make(chan Type, capacity)
- 当参数capacity= 0 时,channel 是无缓冲阻塞读写的;当capacity > 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity个元素才阻塞写入。
- channel非常像生活中的管道,一边可以存放东西,另一边可以取出东西。channel通过操作符
<-来接收和发送数据,发送和接收数据语法:
channel <- value //发送value到channel
<-channel //接收并将其丢弃
x := <-channel //从channel中接收数据,并赋值给x
x, ok := <-channel //功能同上,同时检查通道是否已关闭或者是否为空
- 注意:从channel取数据时,
<-和chan之间不能有空格 - 默认情况下,channel接收和发送数据都是阻塞的,除非另一端已经准备好,这样就使得goroutine同步变的更加的简单,而不需要显式的lock。
- channel传参是引用传参
实例1:
package main
import (
"fmt"
)
func main() {
c := make(chan int)
go func() {
defer fmt.Println("子go程结束")
fmt.Println("子go程正在运行……")
c <- 666 //666发送到c
}()
num := <-c //从c中接收数据,并赋值给num
fmt.Println("num = ", num)
fmt.Println("main go程结束")
}

- 以上实例使用channel实现两个goroutine之间进行通信
- 为什么每次运行都是main goroutine接收到sub goroutine的数据后才会结束:
- 因为channel拥有同步两个goroutine的能力,保证两个goroutine的执行顺序,因为当main goroutine从channel中读取数据时,如果channel中还没有数据,main goroutine就会进入阻塞状态,当数据写入channel后,main goroutine会被唤醒,并读取数据;
- 如果sub goroutine写入了数据后,main goroutine没有读取,则sub goroutine也会进入阻塞状态;
- 因此两个goroutine是能够通过channel来保证执行的先后顺序

3.无缓冲channel
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何数据值的通道。
- 这种类型的通道要求发送goroutine和接收goroutine同时准备好,才能完成发送和接收操作。否则,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。
- 这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
- 阻塞:由于某种原因数据没有到达,当前go程(线程)持续处于等待状态,直到条件满足,才解除阻塞。
- 同步:在两个或多个go程(线程)间,保持数据内容一致性的机制。
下图展示两个 goroutine 如何利用无缓冲的通道来共享一个值:
- 在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收。
- 在第 2 步,左侧的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在通道中被锁住,直到交换完成。
- 在第 3 步,右侧的 goroutine 将它的手放入通道,这模拟了从通道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成。
- 在第 4 步和第 5 步,进行交换,并最终,在第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。两个 goroutine 现在都可以去做其他事情了。
无缓冲的channel创建格式:
make(chan Type) //等价于make(chan Type, 0)
如果没有指定缓冲区容量,那么该通道就是同步的,因此会阻塞到发送者准备好发送和接收者准备好接收。
实例:
package channel_go
import (
"fmt"
"time"
)
func Channel() {
//定义一个channel
c := make(chan int)
go func() {
defer fmt.Println("goroutine1 结束")
fmt.Println("goroutine1 正在运行...")
time.Sleep(3 * time.Second)
c <- 777 //将777发送给c
}()
go func() {
defer fmt.Println("goroutine2 结束")
fmt.Println("goroutine2 正在运行...")
num := <-c //从c中接收数据,并赋值给num
fmt.Println("goroutine2 接收到数据, num = ", num)
}()
for {
time.Sleep(1 * time.Second)
}
}

- 以上实例中,我们创建了两个go程,和一个无缓冲的channel,goroutine1用来发送数据,在3s后将777发送到channel中;goroutine2用来接收数据并打印;
- 在程序运行后,goroutine1和goroutine2并发运行,由于此时channel中是空的,因此goroutine2阻塞等待channel中的数据,3s后goroutine1向channel中发送了777,goroutine2随即接收到数据;
4.有缓冲的channel
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个数据值的通道。
- 这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也不同。
- 只有通道中没有要接收的值时,接收动作才会阻塞。
- 只有通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
- 这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。
示例图如下:
- 在第 1 步,右侧的 goroutine 正在从通道接收一个值。
- 在第 2 步,右侧的这个 goroutine独立完成了接收值的动作,而左侧的 goroutine 正在发送一个新值到通道里。
- 在第 3 步,左侧的goroutine 还在向通道发送新值,而右侧的 goroutine 正在从通道接收另外一个值。这个步骤里的两个操作既不是同步的,也不会互相阻塞。
- 最后,在第 4 步,所有的发送和接收都完成,而通道里还有几个值,也有一些空间可以存更多的值。
有缓冲的channel创建格式:
make(chan Type, capacity)
- 如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
-
借助函数
len(ch)求取缓冲区中剩余元素个数,cap(ch)求取缓冲区元素容量大小。len(ch)返回channel中已有的元素个数cap(ch)返回channel的最大容量
实例1:
package channel_go
import (
"fmt"
"time"
)
func NonBlockChannel() {
c := make(chan int, 3)
fmt.Println("len =", len(c), "cap =", cap(c))
go func() {
defer fmt.Println("子goroutine结束")
for i := 0; i < 10; i++ {
if len(c) == cap(c) {
fmt.Println("子goroutine发送阻塞")
}
c <- i
fmt.Println("子goroutine正在运行,发送的元素:", i, "len =", len(c), "cap =", cap(c))
time.Sleep(1 * time.Second)
}
}()
for i := 0; i < 10; i++ {
if len(c) == 0 {
fmt.Println("主goroutine接收阻塞")
}
num := <-c
fmt.Println("主接收的元素:", num, "len =", len(c), "cap =", cap(c))
time.Sleep(2 * time.Second)
}
}

5.关闭channel
如果发送者知道,没有更多的值需要发送到channel的话,那么让接收者也能及时知道没有多余的值可接收将是有用的,因为接收者可以停止不必要的接收等待。这可以通过内置的close函数来关闭channel实现。
- if语句的简易写法:
可以在if后写赋值表达式,在;后对表达式的值进行条件判断
if data, ok := <-c; ok {
fmt.Println("recrive data :", data)
}
实例1:
- 非阻塞channel,sub goroutine发送结束后不关闭channel,main goroutine一直读取
package channel_go
import (
"fmt"
"time"
)
func CloseChannel() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
//close可以关闭一个channel
//close(c)
}()
for {
//ok返回的是channel是否关闭
if data, ok := <-c; ok {
fmt.Println("recrive data :", data)
} else {
break
}
}
fmt.Println("main finished")
}

- 以上实例的结果出现了报错,所有的goroutine都在阻塞,出现死锁错误
实例2:
- 在sub goroutine发送完毕后,就关闭channel
package channel_go
import (
"fmt"
"time"
)
func CloseChannel() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
//close可以关闭一个channel
//close(c)
}()
for {
//ok返回的是channel是否关闭
if data, ok := <-c; ok {
fmt.Println("recrive data :", data)
} else {
break
}
}
fmt.Println("main finished")
}

- 上述实例的运行结果,子go程发送完数据就关闭channel,主go程接收数据时检测到channel关闭,就结束循环
总结:
- channel不像文件一样需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式的结束range循环之类的,才去关闭channel;
- 关闭channel后,无法向channel 再发送数据(引发 panic 错误后导致接收立即返回零值);
- 关闭channel后,可以继续从channel接收数据;
- 对于nil channel,无论收发都会被阻塞。
6.channel与range
可以使用 range 来迭代不断操作channel:
- for - range可以阻塞等待channel中的数据,如果c中没有数据,for - range循环会阻塞,知道channel中有数据;
- 如果channel关闭,则for - range循环会退出
package channel_go
import (
"fmt"
)
func CloseChannel() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
//close可以关闭一个channel
//close(c)
}()
//range会阻塞等待c中的数据,可以使用range来迭代不断操作channel
for data := range c {
fmt.Println("recrive data :", data)
}
fmt.Println("main finished")
}

7.channel与select
单流程下一个goroutine只能监控一个channel状态,select可以完成监控多个channel的状态
select {
case <- chan1:
//如果chan1成功读取到数据,则进行该case处理语句
case chan2 <- 1:
//如果成功向chan2写入数据,则进行该case处理语句
default:
//如果上面都没有成功,则进入default处理流程
}
- 注意:一旦case语句执行成功,则表明该channel操作成功了,就会进入该case的处理语句
实例:
- 用select实现斐波那契数列;
package channel_go
import (
"fmt"
)
func fibonacii(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <- x:
//如果c可写,则该case就会进来,并且x会写入c
pre_x := x
x = y
y = pre_x + y
case <-quit:
//如果quit可读,就退出
fmt.Println("quit")
return
}
}
}
func SelectAndChannel() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 5; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
//main
fibonacii(c, quit)
}

- 上述实例中,主go程执行fibonacii函数,使用select语句对两个channel进行监控,如果c可写,就向c中写入斐波那契数列;如果quit可读,就返回;
- 子go程用于从c中读取斐波那契数列,读取完后,就向quit中写入0
8.单向channel及应用
默认情况下,通道channel是双向的,也就是,既可以往里面发送数据也可以同里面接收数据。
但是,我们经常见一个通道作为参数进行传递而只希望对方是单向使用的,要么只让它发送数据,要么只让它接收数据,这时候我们可以指定通道的方向。
- 单向channel变量的声明非常简单,如下:
var ch1 chan int // ch1是一个正常的channel,是双向的
var ch2 chan<- float64 // ch2是单向channel,只用于写float64数据
var ch3 <-chan int // ch3是单向channel,只用于读int数据
-
chan<-表示数据进入管道,要把数据写进管道,对于调用者就是输出。 -
<-chan表示数据从管道出来,对于调用者就是得到管道的数据,当然就是输入。 - 可以将 channel 隐式转换为单向队列,只收或只发,不能将单向 channel 转换为普通 channel:
c := make(chan int, 3)
var send chan<- int = c // send-only
var recv <-chan int = c // receive-only
send <- 1
//<-send //invalid operation: <-send (receive from send-only type chan<- int)
<-recv
//recv <- 2 //invalid operation: recv <- 2 (send to receive-only type <-chan int)
//不能将单向 channel 转换为普通 channel
d1 := (chan int)(send) //cannot convert send (type chan<- int) to type chan int
d2 := (chan int)(recv) //cannot convert recv (type <-chan int) to type chan int
- 一个双向channel可以隐式转换为一个单向输入channel和一个单向输入channel,使用单向channel分别控制输入输出
实例:文章来源:https://www.toymoban.com/news/detail-817488.html
package channel_go
import (
"fmt"
)
// chan<- 只写
func counter(out chan<- int) {
defer close(out)
for i := 0; i < 5; i++ {
out <- i //如果对方不读,会阻塞
}
}
// <-chan 只读
func printer(in <-chan int) {
for num := range in {
fmt.Println(num)
}
}
func SingleChannel() {
c := make(chan int) //读写
go counter(c) //生产者
printer(c) //消费者
fmt.Println("finished")
}
 文章来源地址https://www.toymoban.com/news/detail-817488.html
文章来源地址https://www.toymoban.com/news/detail-817488.html
- 上述实例中,定义了一个双向channel c,一个参数为单向输入型channel的函数counter,一个参数为单向输出型channel的函数printer
- 子go程执行counter,传入c,向c中写入数据
- 主go程执行printer,传入c,读取c中的数据
到了这里,关于Go后端开发 -- goroutine && channel的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!