一、DeepFloyd IF 简介
- DeepFloyd IF:能够绘制文字的 AI 图像工具
之前的 Stable Diffusion 和 Midjourney 都无法生成带有文字的图片,而文字都是乱码。 DeepFloyd IF,这个文本到图像的级联像素扩散模型功能强大,能巧妙地将文本集成到图像中。 - DeepFloyd IF的优点是它能够生成高度真实的图像,并且具有很强的语言理解能力。它使用大规模数据集进行训练,这使得它能够生成高质量的图像。
- DeepFloyd IF支持文本到图像的生成和图像到图像的翻译,这使得它在文本到图像的生成领域具有很大的潜力。
二、DeepFloyd IF模型架构
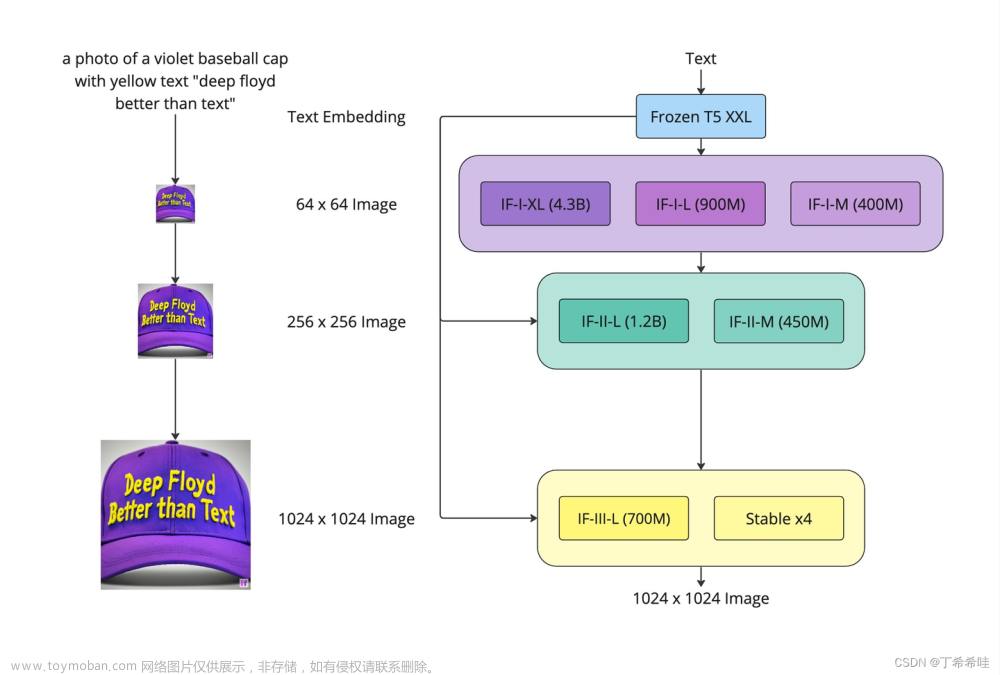
DeepFloyd IF 采用模块化设计,由一个固定的文本编码器和三个级联的像素扩散模块组成:
- 冻结文本编码器: 将文本提示转换为图像。它使用预训练的语言模型将文本提示转化为嵌入,然后通过像素扩散模型将这些嵌入解码为图像。
- 基本模型: 基于文本提示生成64x64px图像。使用预训练的语言模型和像素扩散模型来生成图像。
-
超分辨率模型: 包括两个超分辨率模型,每个模型都旨在生成分辨率递增的图像。
- 第一个超分辨率模型生成256x256px的图像,
- 第二个超分辨率模型生成1024x1024px的图像。
三、DeepFloyd IF模型生成流程
DeepFloyd IF模型的所有阶段都使用基于 T5 变换器的固定文本编码器提取文本嵌入,然后将其输入到增强了跨注意力和注意力池化的 UNet 架构中。
- 第一阶段: 基本扩散模型将定性文本转换为64x64图像。DeepFloyd团队已训练三个版本的基本模型,每个模型的参数都不同:IF-I 400M、IF-I 900M和IF-I 4.3B。
- 第二阶段: 为了“放大”图像,应用两个文本条件超分辨率模型(Efficient U-Net)对基本模型的输出。第一个模型将64x64图像放大到256x256图像。同样,该模型也有几个版本可用:IF-II 400M和IF-II 1.2B。
-
第三阶段: 应用第二个超分辨率扩散模型产生生动的1024x1024图像。
四、DeepFloyd IF 模型定义
DeepFloyd IF是一个模块化的、级联的、像素扩散模型。
-
模块化:
DeepFloyd IF由几个神经模块组成(可以独立解决任务的神经网络,如从文本提示生成图像和超分辨率),这些模块在一个体系结构中相互作用,产生协同效应。 -
级联:
DeepFloyd IF以级联方式对高分辨率数据进行建模,使用不同分辨率下单独训练的一系列模型。该过程从生成唯一低分辨率样本的基本模型(“player”)开始,然后由连续的超分辨率模型(“amplifiers”)上采样以产生高分辨率图像。 -
扩散:
DeepFloyd IF的基本模型和超分辨率模型是扩散模型,其中使用一系列步骤的马尔科夫链向数据中注入随机噪声,然后反转该过程以从噪声中生成新数据样本。和stable diffusion最大的区别是deep-floyd是在像素空间做扩散,而不是在latents空间做扩散。文章来源:https://www.toymoban.com/news/detail-817711.html
-
像素:
DeepFloyd IF在像素空间工作。与使用潜在表示的潜在扩散模型(如Stable Diffusion)不同,扩散是在像素级实现的。
参考:
新的生图模型DeepFloyd IF来了,可以拳打Stable Diffusion,脚踢Dall-E?
一款由文本生成图像的强大模型,可以智能地将文本集成到图像中文章来源地址https://www.toymoban.com/news/detail-817711.html
到了这里,关于DeepFloyd IF:由文本生成图像的强大模型,能够绘制文字的 AI 图像工具的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!