原文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Huang_Tri-Perspective_View_for_Vision-Based_3D_Semantic_Occupancy_Prediction_CVPR_2023_paper.pdf
1. 引言
体素表达需要较大的计算量和特别的技巧(如稀疏卷积),BEV表达难以使用平面特征编码所有3D结构。
本文提出三视图(TPV)表达3D场景。为得到空间中一个点的特征,首先将其投影到三视图平面上,使用双线性插值获取各投影点的特征。然后对3个投影点特征进行求和,得到3D点的综合特征。这样,可以以任意分辨率描述3D场景,并对不同的3D点产生不同的特征。此外,本文还提出基于Transformer的编码器(TPVFormer),以从2D图像获取TPV特征。首先,在TPV网格查询与2D图像特征之间使用图像交叉注意力,将2D信息提升到3D。然后,在TPV特征之间使用跨视图混合注意力进行TPV跨平面交互。
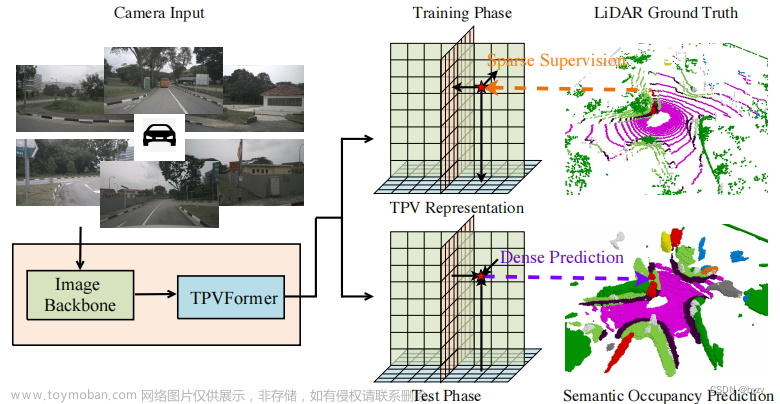
本文进行的任务为3D语义占用估计,其中训练时只有稀疏激光雷达语义标签,但测试时需要所有体素的语义预测,如上图所示。但由于没有基准,只能进行定性分析,或在两个代理任务上进行定量分析:激光雷达分割(稀疏训练、稀疏测试)和3D语义场景补全(密集训练、密集测试)。两任务均仅使用图像数据;对激光雷达分割任务,仅使用激光雷达点云进行点查询以计算评估指标。
3. 提出的方法
3.1 将BEV推广到TPV

本文提出三视图(TPV)表达,不需像BEV表达一样压缩某轴,且可以避免体素表达的立方复杂度,如上图所示。具体来说,学习3个轴对齐的正交平面:
T
=
[
T
H
W
,
T
D
H
,
T
W
D
]
,
T
H
W
∈
R
H
×
W
×
C
,
T
D
H
∈
R
D
×
H
×
C
,
T
W
D
∈
R
W
×
D
×
C
T=[T^{HW},T^{DH},T^{WD}],T^{HW}\in\mathbb{R}^{H\times W\times C},T^{DH}\in\mathbb{R}^{D\times H\times C},T^{WD}\in\mathbb{R}^{W\times D\times C}
T=[THW,TDH,TWD],THW∈RH×W×C,TDH∈RD×H×C,TWD∈RW×D×C
分别表达俯视图、侧视图和前视图。
点查询的形式:给定世界坐标系下的查询点
(
x
,
y
,
z
)
(x,y,z)
(x,y,z),TPV表达首先聚合其在三视图平面上的投影,以得到点的综合描述。设投影到TPV平面的坐标为
[
(
h
,
w
)
,
(
d
,
h
)
,
(
w
,
d
)
]
[(h,w),(d,h),(w,d)]
[(h,w),(d,h),(w,d)],采样的特征为
[
t
h
w
,
t
d
h
,
t
w
d
]
[t_{hw},t_{dh},t_{wd}]
[thw,tdh,twd],则聚合特征为:
t
i
j
=
S
(
T
,
(
i
,
j
)
)
=
S
(
T
,
P
I
J
(
x
,
y
,
z
)
)
,
(
i
,
j
)
∈
{
(
h
,
w
)
,
(
d
,
h
)
,
(
w
,
d
)
}
f
x
y
z
=
A
(
t
h
w
,
t
d
h
,
t
w
d
)
t_{ij}=\mathcal{S}(T,(i,j))=\mathcal{S}(T,\mathcal{P}_{IJ}(x,y,z)),(i,j)\in\{(h,w),(d,h),(w,d)\}\\ f_{xyz}=\mathcal{A}(t_{hw},t_{dh},t_{wd})
tij=S(T,(i,j))=S(T,PIJ(x,y,z)),(i,j)∈{(h,w),(d,h),(w,d)}fxyz=A(thw,tdh,twd)
其中 S \mathcal{S} S为采样函数, A \mathcal{A} A为聚合函数, P \mathcal{P} P为投影函数(由于TPV平面与世界坐标系对齐,实际仅进行缩放)。
体素特征的形式:TPV平面会沿其正交方向复制自身并与来自其余视图的特征求和,得到3D特征空间。其存储与计算复杂度为 O ( H W + D H + W D ) O(HW+DH+WD) O(HW+DH+WD)。
总的来说,TPV可以通过多视图的相互补充提供更细粒度的3D场景理解,同时保持高效性。
3.2 TPVFormer
本文使用TPV编码器(TPVFormer),通过注意力机制将图像特征提升到TPV平面。
总体结构:本文引入TPV查询、图像交叉注意力(ICA)与跨视图混合注意力(CVHA)以保证有效生成TPV平面,如下图所示。TPV查询就是TPV平面上的网格特征,
t
∈
T
t\in T
t∈T,用于编码视图特定的信息。跨视图混合注意力在同一平面或不同平面上各TPV查询之间交互,以获取上下文信息。图像交叉注意力则使用可变形注意力聚合图像特征。
本文还进一步建立了两种Transformer块:混合-交叉注意力块(HCAB,由CVHA与ICA组成,位于TPVFormer的前半部分,查询图像特征中的视觉信息)与混合注意力块(HAB,仅含CVHA,位于HCAB之后,专门进行上下文信息编码)。
TPV查询:每个TPV查询对应相应视图中 s × s m 2 s\times s \ \text{m}^2 s×s m2的2D单元格区域或沿正交方向延伸的3D柱状区域。TPV查询首先会使用原始视觉信息增强(HCAB),再通过来自其余查询的上下文信息细化(HAB)。TPV查询被初始化为可学习参数。
图像交叉注意力:使用可变形注意力以节省计算。对于
(
h
,
w
)
(h,w)
(h,w)处的查询
t
h
w
t_{hw}
thw,首先通过逆投影函数
P
H
W
−
1
\mathcal{P}^{-1}_{HW}
PHW−1计算其世界坐标系下的坐标
(
x
,
y
)
(x,y)
(x,y),然后沿平面的正交方向均匀采样
N
H
W
r
e
f
N_{HW}^{ref}
NHWref个参考点:
(
x
,
y
)
=
P
H
W
−
1
(
h
,
w
)
=
(
(
h
−
H
2
)
×
s
,
(
w
−
W
2
)
×
s
)
Ref
h
w
w
=
{
(
x
,
y
,
z
i
)
}
i
=
1
N
H
W
r
e
f
(x,y)=\mathcal{P}^{-1}_{HW}(h,w)=((h-\frac H 2)\times s,(w-\frac W 2)\times s)\\ \text{Ref}_{hw}^w=\{(x,y,z_i)\}^{N_{HW}^{ref}}_{i=1}
(x,y)=PHW−1(h,w)=((h−2H)×s,(w−2W)×s)Refhww={(x,y,zi)}i=1NHWref
其中
Ref
h
w
w
\text{Ref}_{hw}^w
Refhww表示查询
t
h
w
t_{hw}
thw在世界坐标系下的参考点集。其余平面的查询类似,需要注意不同平面的
N
r
e
f
N^{ref}
Nref不同,因为不同轴的范围不同。然后,将参考点投影到像素坐标系,以采样图像特征:
Ref
h
w
p
=
P
p
i
x
(
Ref
h
w
w
)
\text{Ref}_{hw}^p=\mathcal{P}_{pix}(\text{Ref}_{hw}^w)
Refhwp=Ppix(Refhww)
其中
Ref
h
w
p
\text{Ref}_{hw}^p
Refhwp为查询
t
h
w
t_{hw}
thw在像素坐标系下的参考点集,
P
p
i
x
\mathcal{P}_{pix}
Ppix为由相机内外参确定的透视投影函数。若存在
N
c
N_c
Nc个相机,则生成的参考点集为
{
Ref
h
w
p
,
j
}
j
=
1
N
c
\{\text{Ref}_{hw}^{p,j}\}_{j=1}^{N_c}
{Refhwp,j}j=1Nc。此外,可以剔除为落在图像范围外的参考点以节省计算。最后,将
t
h
w
t_{hw}
thw通过两个线性层生成偏移量与注意力权重,并通过加权求和采样图像特征产生更新的TPV查询:
ICA
(
t
h
w
,
I
)
=
1
∣
N
h
w
v
a
l
∣
∑
j
∈
N
h
w
v
a
l
DA
(
t
h
w
,
Ref
h
w
p
.
j
,
I
j
)
\text{ICA}(t_{hw},I)=\frac 1{|N_{hw}^{val}|}\sum_{j\in N_{hw}^{val}}\text{DA}(t_{hw},\text{Ref}_{hw}^{p.j},I_j)
ICA(thw,I)=∣Nhwval∣1j∈Nhwval∑DA(thw,Refhwp.j,Ij)
其中 N h w v a l N_{hw}^{val} Nhwval为有效视图的集合, I j I_j Ij为视图 j j j的图像特征, DA \text{DA} DA为可变形注意力函数。
跨视图混合注意力:该步骤使不同视图能交换信息,以提取上下文。同样使用可变形注意力,其中TPV平面作为键与值。首先将参考点分为3个不相交的子集,分属俯视图、侧视图和前视图:
R
h
w
=
R
h
w
t
o
p
∪
R
h
w
s
i
d
e
∪
R
h
w
f
r
o
n
t
R_{hw}=R^{top}_{hw}\cup R_{hw}^{side}\cup R_{hw}^{front}
Rhw=Rhwtop∪Rhwside∪Rhwfront
为收集俯视图平面的参考点,进行查询
t
h
w
t_{hw}
thw所在邻域内的随机采样。对侧视图与前视图,沿正交方向均匀采样并投影到侧视平面与前视平面:
R
h
w
s
i
d
e
=
{
(
d
i
,
h
)
}
i
,
R
h
w
f
r
o
n
t
=
{
(
w
,
d
i
)
}
i
R_{hw}^{side}=\{(d_i,h)\}_i,R_{hw}^{front}=\{(w,d_i)\}_i
Rhwside={(di,h)}i,Rhwfront={(w,di)}i
然后进行可变形注意力:
C
V
H
A
(
t
h
w
)
=
DA
(
t
h
w
,
R
h
w
,
T
)
CVHA(t_{hw})=\text{DA}(t_{hw},R_{hw},T)
CVHA(thw)=DA(thw,Rhw,T)
3.3 TPV的应用
需要将TPV平面 T T T转化为点或体素特征以输入任务头。
点特征:给定世界坐标系下的点坐标,与点查询相同,将点投影到TPV平面上检索特征并求和。
体素特征:将TPV平面沿正交方向广播得到3个大小相同的特征张量,并求和。
为进行分割任务,本文在点或体素特征上添加2层MLP以预测语义标签。
4. 实验
4.1 任务描述
3D语义占用预测:使用稀疏语义标签(激光雷达点)训练,但测试时需要生成所有体素的语义占用。
激光雷达分割:对应点查询形式,预测给定点的语义标签。注意仍使用RGB图像输入。
语义场景补全(SSC):使用体素标签监督训练。该任务对应体素查询形式。评估时,场景补全使用IoU(忽略类别),SSC使用mIoU。
4.2 实施细节
3D语义占用预测和激光雷达分割:训练时使用交叉熵损失和lovasz-softmax损失。其中3D语义占用预测会从稀疏点云生成逐体素的伪标签(不含点的体素标记为空),损失函数均使用体素预测;激光雷达分割任务使用点预测计算lovasz-softmax损失,体素预测计算交叉熵损失以提高点分类精度并避免语义模糊。
语义场景补全:使用MonoScene的损失。
4.3 3D语义占用预测结果
主要结果:可视化表明,预测结果比激光雷达更加密集,表明了TPV表达对建模3D场景和语义占用预测的有效性。
测试时的任意分辨率:可以在测试时随意调整TPV平面的分辨率,而无需重新训练网络。
4.4 激光雷达分割结果
作为第一个基于视觉的激光雷达分割任务,本文与其余基于激光雷达的任务比较。实验表明,本文方法能达到相当的性能水平。
4.5 语义场景补全结果
实验表明,本文的方法在性能和速度上均能超过MonoScene,且参数量更低。
4.6 分析
激光雷达分割中的损失函数:当损失函数的两项分别使用点预测和体素预测时,体素预测和点预测的mIoU均很高且相近。当仅使用点预测(体素预测)时,体素预测(点预测)的性能会比点预测(体素预测)明显更低。这表明连续与离散的监督对学习鲁棒表达的重要性。
TPV分辨率和特征维度:提高分辨率带来的性能提升更为显著,因为能增强细粒度结构的建模。
BEV、体素与TPV的比较:各表达使用相似的方法将图像特征提升到3D。结果表明,在相近的模型大小下,TPV的性能与速度均更高。
HCAB与HAB块的数量:当HCAB的数量增加时,IoU增大,这说明直接视觉线索对几何理解的重要性。但上下文信息也很重要,因为最高的mIoU是在适当数量的HCAB与HAB下得到的。文章来源:https://www.toymoban.com/news/detail-818085.html
局限性:基于图像的方法的优势是做出3D空间密集预测的能力;但在激光雷达分割任务上,仍不如激光雷达方法。文章来源地址https://www.toymoban.com/news/detail-818085.html
到了这里,关于【原文链接】Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!











