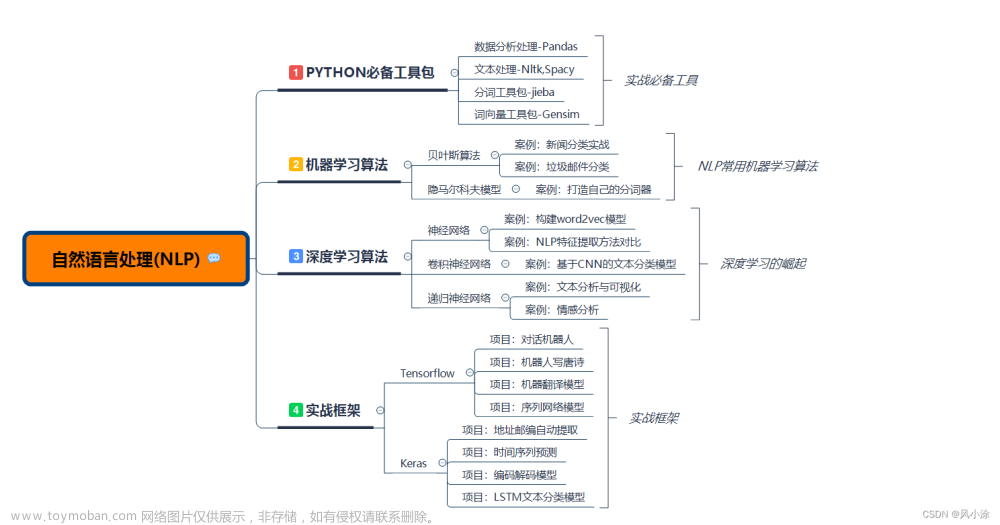
中文NLP的NER任务中的数据集序列标注方法,主要有以下几种常用的标注方案:
-
BIO标注法(Begin-Inside-Outside):
- B(Begin)表示实体的开始部分。
- I(Inside)表示实体的中间部分。
- O(Outside)表示非实体部分。
- 例如,“北京是中国的首都”,如果要标注“北京”为地名,会标为“B-地名 I-地名 O O O O O”。
-
BIOES标注法(Begin-Inside-Outside-End-Single):
- B(Begin)表示实体的开始部分。
- I(Inside)表示实体的中间部分。
- O(Outside)表示非实体部分。
- E(End)表示实体的结束部分。
- S(Single)表示单独成词的实体。
- 例如,“北京 是 中国 的 首都”,对于“北京”,标注为“S-地名”。
-
BMES标注法(Begin-Middle-End-Single):
- B(Begin)表示实体的开始部分。
- M(Middle)表示实体的中间部分。
- E(End)表示实体的结束部分。
- S(Single)表示单独成词的实体。
- 例如,“北京市长”中的“北京市”,如果标注为地名,则“北京”标为“B-地名”,“市”标为“E-地名”。
-
BMEWO标注法(Begin-Middle-End-Whole-Outside):
- 类似于BMES,但增加了表示整体实体的标签。
- W(Whole)表示整个实体。
- 适用于一些特定的实体识别任务,其中实体通常是单个词。
这些方法的选择取决于具体的任务需求和数据集特性,不同的标注方法会对模型的训练和最终的实体识别效果产生影响。
例如,BIOES和BMES方法通过增加实体结束和单独成词的实体标签,有助于提高实体边界的识别精度。文章来源:https://www.toymoban.com/news/detail-818123.html
在实际应用中,应根据任务的具体要求和数据集的特点选择合适的标注方案。文章来源地址https://www.toymoban.com/news/detail-818123.html
到了这里,关于中文自然语言处理(NLP)的命名实体识别(NER)任务常见序列标注方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!