随着互联网技术的快速发展,分布式系统在各个领域得到了广泛的应用。分布式 ID 是分布式系统中的一种重要概念,用于唯一标识系统中生成的各种数据。在分布式环境下,如何高效、可靠地生成分布式 ID 是一个具有挑战性的问题。本文将介绍几种常见的分布式 ID 实现方式。文章来源:https://www.toymoban.com/news/detail-818303.html
- 数据库自增主键
数据库自增主键是一种常见的分布式 ID 生成方式。在这种方式中,每个数据库表都有一个自增的主键字段,当插入一条新记录时,数据库会自动为该字段生成一个唯一的 ID。这种方式简单易用,但存在一些问题。首先,数据库自增主键的生成过程与数据库紧密耦合,不利于系统的扩展和迁移。其次,在高并发环境下,数据库可能会成为系统的性能瓶颈。 - UUID
UUID(Universally Unique Identifier)是另一种常见的分布式 ID 生成方式。UUID 是一个长度为 128 位的数字,通常由时间戳、机器地址和随机数等组成。UUID 具有全球唯一性,可以保证在不同的系统和网络中生成的 ID 不会发生冲突。但 UUID 的长度较长,不易于阅读和存储,且生成的过程中涉及到随机数的生成,可能会导致一定的性能开销。 - Redis
Redis 是一种基于内存的键值对存储系统,具有高性能和丰富的数据结构。Redis 提供了 INCR 和 INCRBY 命令,可以用于生成自增的分布式 ID。在这种方式中,可以将 Redis 作为分布式 ID 的生成器,将生成的 ID 存储在 Redis 中。Redis 的性能很高,可以满足高并发环境下的需求。但 Redis 是一种内存数据库,数据可能会丢失,因此需要定期将数据持久化到磁盘或其他存储介质中。 - Snowflake
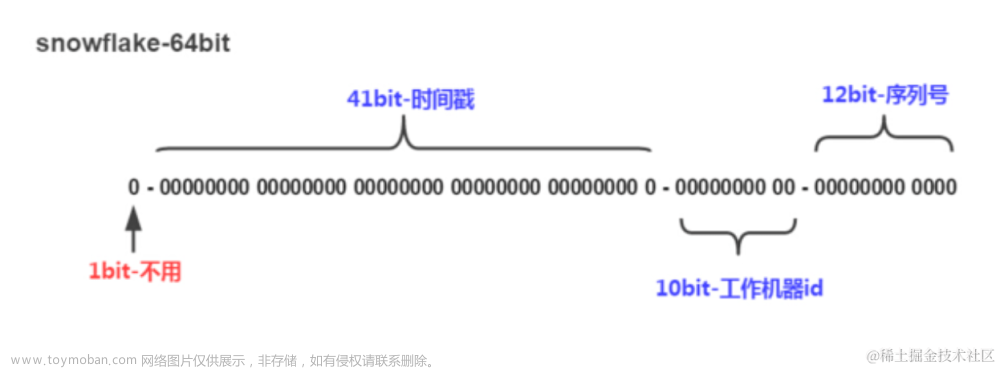
Snowflake 是 Twitter 开源的一种分布式 ID 生成算法。Snowflake 算法将 64 位的 ID 分为时间戳、数据中心标识、机器标识和序列号四个部分。其中,时间戳用于保证 ID 的递增性,数据中心标识和机器标识用于区分不同的数据中心和机器,序列号用于在同一毫秒内生成不同的 ID。Snowflake 算法具有良好的性能和扩展性,可以满足大多数分布式系统的需求。
总结
分布式 ID 的实现方式有很多种,不同的方式适用于不同的场景和需求。在选择分布式 ID 实现方式时,需要考虑系统的性能、可靠性、可扩展性等因素。数据库自增主键、UUID、Redis 和 Snowflake 是几种常见的分布式 ID 实现方式,可以根据实际情况选择适合的方式。文章来源地址https://www.toymoban.com/news/detail-818303.html
到了这里,关于分布式 ID 的几种实现方式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!