一、ML机器学习(Machine Learning)
1、应用领域:数据挖掘、自然语言处理 NLP、计算机视觉 CV等。
2、发展的三要素:数据、算法、算力
3、相关术语
机器学习模型 = 数据 + 算法
数据:用于训练模型
样本(sample):一行数据
特征(feature):一列数据(必须和目标相关)
标签(label)/目标(target):要预测的值,即答案列
数据集:训练集、测试集
x_train:训练集的特征值
y_train:训练集的目标值
x_test:测试集的特征值
y_test:测试集的目标值
二、算法分类(根据数据是否有标签)
1、有监督:监督学习的算法,要求数据一定要有目标值
回归问题:目标值是连续取值(房价、薪水)
分类问题:目标值是类别型(二分类、三分类、多分类)
2、无监督:没有目标值,无反馈
典型场景聚类,获得标签的成本太高,可以采用无监督的方式(反欺诈)
3、半监督:一部分数据有标签、一部分数据没有标签
三、建模流程
1、获取数据
2、数据基本处理:空值、异常、重复
3、特征工程
特征提取:原始数据中提取与任务相关的特征,构成特征向量
预处理、降维、选择、组合
4、模型训练(调参):线性回归、逻辑回归、决策树、GBDT
5、模型评估:回归评测指标、分类评测指标、聚类评测指标
四、模型拟合
1、分类
欠拟合:模型在 训练集和测试集 表现都很差
产生原因:模型过于简单,特征过少
解决办法:添加其他特征;添加多项式特征项
过拟合:训练集表现很好,测试集表现很差
产生原因:模型过于复杂、数据不纯、训练数据太少
解决方法:重新清洗数据,增大训练数据的样本量,正则化,减少特征维度
Early stopping:当模型训练到某个固定的验证错误率阈值时,及时停止模型训练
2、正则化
异常点数据造成权重系数过大、过小,尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化。
为了减少 过拟合的影响,控制模型的参数。尤其是高次项的权重参数
L1正则化:使得权重趋向于 0,甚至等于 0,使得某些特征失效,达到特征筛选的目的

导包:from sklearn.linear_model import Lasso
正则化:estimator = Lasso ( alpha = 0.005,normalize = True )
a:惩罚系数,该值越大则权重调整的幅度就越大
L2正则化:使得权重趋向于 0,一般不等于 0,对高次方项系数影响较大
tips:工程开发常用,产生一些平滑的权重系数

岭回归导包:from sklearn.linear_model import Ridge
正则化:estimator = Ridge( alpha = 0.005,normalize = True )
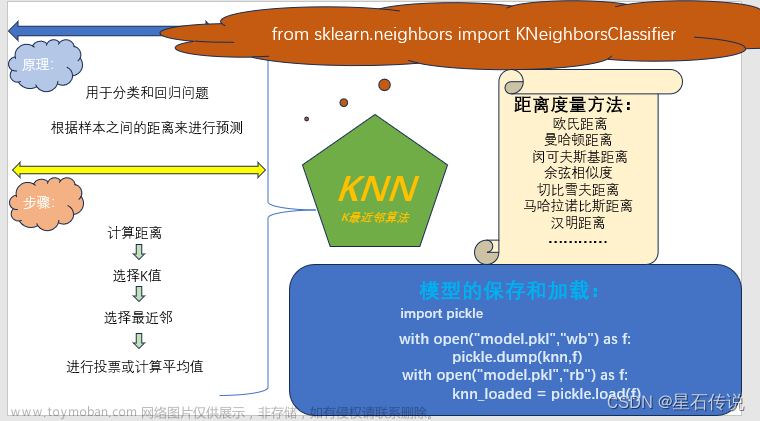
五、KNN(K-近邻算法)
1、概述
通过计算距离来判断样本之间的相似程度,距离越近两个样本就越相似, 就可以划归到一个类别中
2、算法思想
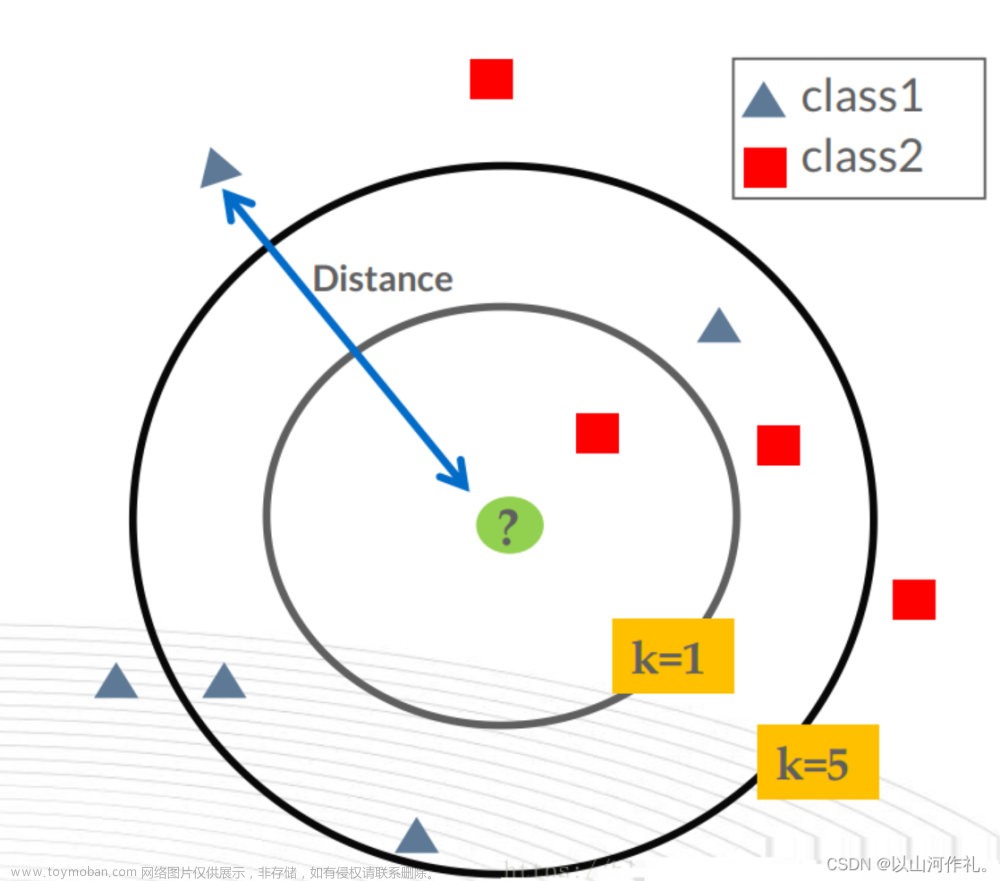
如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别
3、样本相似性
样本都属于一个任务数据集,样本距离越近越相似
4、基本流程
1. 使用KNN算法对一个样本进行分类
2. 计算当前样本和其它样本, 特征取值之间的距离,按距离 从小到大 进行排序
3. 确定K值 : 离该样本最近的K个样本
4. 通过这K个样本的类别 确定当前样本的类别
5、K(超参数)可调
K越小 模型越复杂 容易受到 异常点 的影响,过拟合
K越大 模型越简单 受到数据分布的影响,欠拟合
当K = 样本数量的时候, 模型结果是确定的结果
6、API
1. K-近邻导包
from sklearn.neighbors import KNeighborsClassifier,KNeighborsRegressor
KNeighborsClassifier k-近邻(分类)
KNeighborsRegressor k-近邻(回归)
2. 创建 K近邻的分类器 / 回归器
knn = KNeighborsClassifier(n_neighbors = 1)
n_neighbors:即K值,样本个数
3. 调用fit 模型训练
knn.fit(x, y) x 训练集特征值
y 训练集目标值
4. 使用训练好的模型进行预测
knn.predict ( [[4,4,5]] )
tips:训练时的维度 与 预测时传入的维度 要相同
7、距离 的度量方式
欧氏距离:两点之间的直线距离

曼哈顿距离:

切比雪夫距离:

闵可夫斯基距离:多种距离的总的表示公式

p = 1 曼哈顿,p = 2 欧氏距离,p = ∞ 切比雪夫距离
六、特征工程
1、归一化 / 标准化:可以把量纲不统一的特征,缩放到同一取值范围内
2、归一化(受异常值影响)
1. 归一化导包:from sklearn.preprocessing import MinMaxScaler
2. 创建一个 Scaler 对象:scaler = MinMaxScaler ( )
3. 调用fit 模型训练:scaler.fit(x)
fit 就是在计算每一列 特征 的最大值和最小值, 并保存到 scaler 对象中
4. Transform 得到缩放之后的结果:scaler.transform(x)
Transform 变化,利用上一步计算出来的 最大最小值, 作用到原始数据上,得到缩放之后的结果
3、标准化

1. 标准化导包:from sklearn.preprocessing import StandardScaler
2. 创建一个 Scaler 对象:scaler = StandardScaler ( )
3. 调用fit 模型训练:scaler.fit(x)
fit 就是在计算每一列 特征 的均值和方差, 并保存到 scaler 对象中
4. Transform 得到缩放之后的结果:scaler.transform(x)文章来源:https://www.toymoban.com/news/detail-818514.html
Transform 变化,利用上一步计算出来的 均值和方差, 作用到原始数据上,得到缩放之后的结果文章来源地址https://www.toymoban.com/news/detail-818514.html
到了这里,关于快速了解—机器学习、K-近邻算法及其API的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!