1. 哈希函数和运用
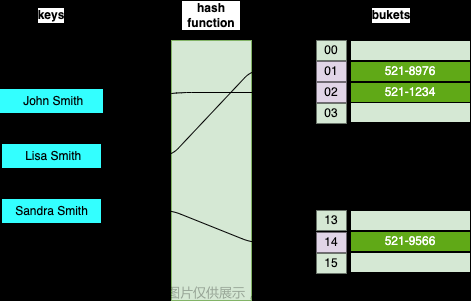
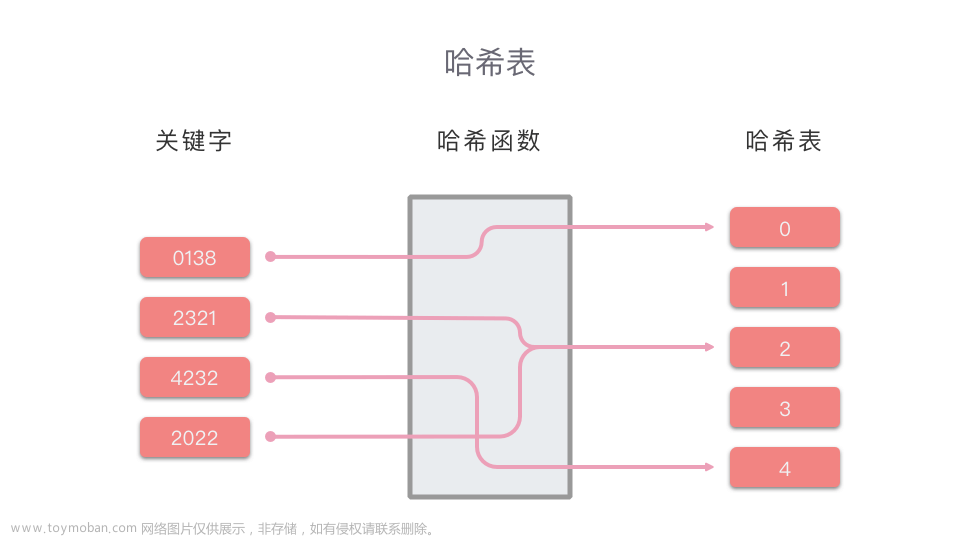
哈希函数指将哈希表中元素的关键键值映射为元素存储位置的函数。
哈希函数有有一些性质,是可以运用的,元素经过哈希函数映射到一个有限的集合中,这些数在集合中的分布是均匀的,就像沙子均匀散落在盘中一样。
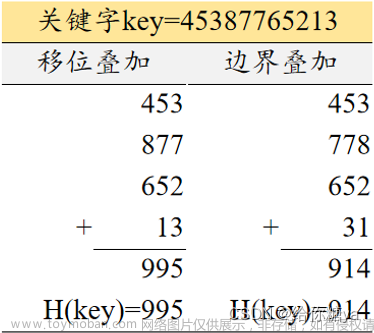
常见的哈希函数有MD5和Shal两种。MD5它哈希值的范围是0~264-1,Shal它的哈希值的范围是
0~2128-1。
现在我们来看下面这样一个实际的问题:假如给你一个40亿数据,给你1GB的内存,让你找到出现次数最多的数据。
大家的第一思路可能是我们用一个哈希表,存储这个数据和它出现的次数,然后求出最多出现的次数。但是我们用最坏的情况取估计,假设这40亿的数据都是不一样的,现在我们看看要花费多大的空间。 那么内存一定是不够的,我们注意到哈希函数的性质,我们可以通过哈希函数来进行分组。
那么内存一定是不够的,我们注意到哈希函数的性质,我们可以通过哈希函数来进行分组。 然后我们用这1GB内存依次从每个组中进行哈希,把这些组的出现最多的数据和次数保存下来,最后取Max,求出出现最多的数据。
然后我们用这1GB内存依次从每个组中进行哈希,把这些组的出现最多的数据和次数保存下来,最后取Max,求出出现最多的数据。
2.哈希表的时间复杂度
我们知道哈希表解决哈希冲突的一种常用的方法是拉链法,假如和我们现在有N个字符串,我们对它们进行哈希处理,对哈希值%17,得到了这样一个哈希表。 我们发现,这样得到的哈希表实际上是不行的,我们如何去得到一个时间复杂度更优的哈希表呢?
我们发现,这样得到的哈希表实际上是不行的,我们如何去得到一个时间复杂度更优的哈希表呢?
我们在链表长度大于一个特定的数的时候进行扩容,现在对上面的哈希过程优化。 这只是一种优化,JVM还有忧化,用户用哈希表当链过长时,后台会给你生成一个新的更大的哈希表,生成好后让你使用,这个扩容过程不占用用户的资源的。
这只是一种优化,JVM还有忧化,用户用哈希表当链过长时,后台会给你生成一个新的更大的哈希表,生成好后让你使用,这个扩容过程不占用用户的资源的。
3.布隆过滤器
现在我们给出一个场景题,现在有个黑名单有100亿个url,我们不希望用户去访问这些url,假设这每个url是64字节,也就是判断这个url是否属于这个集合,我们可能想用hash表来实现,但是这样哈希表要用6400亿万字节,也就是596G的内存。这样内存太多了。
现在布隆过滤器就是来优化这个问题,如果这个集合只有插入数据,判断这个数据是否在这个集合中这两种操作,没有删除这种操作的话,就可以使用。但是布隆过滤器是有失误率的,会出现误判的行为。但是这个误判只是将不在黑名单的数据,误判它在黑名单中,其实这个情况是可以接受的,因为并没有出现,在黑名单的数据误判不在黑名单内,这个误判不影响我们黑名单的本来的功能,而且这个失误率是我们是可以把它降到很低的。
下面看看原理:
现在我们看看位图,位图可以认为就是每个格子为1bit的连续数组,假如我们有个int,一个int等于32bit。
我们可以通过这样的方式我们就可以把一个int类型的数组变成一个位图,如何操作呢?
 现在我们就有位图的所有操作了,那么我们来看看布隆过滤器的原理吧。假如我们现在有一个m比特的一个位图。
现在我们就有位图的所有操作了,那么我们来看看布隆过滤器的原理吧。假如我们现在有一个m比特的一个位图。
插入操作: 判断操作:
判断操作:
我们通过这k个哈希函数得到所对应的k个key,检查这k个key在位图的位置,如果这k个key所在的位置都被标记上了1,那么这个url就在这个黑名单中。
那么为啥可以这样判断呢,为啥判断会有失误率呢?
(1)我们是通过这个方式来把数据加入黑名单的,再用这个操作来判断它是否在黑名单中,肯定是没有问题的。
(2)加入我们的数据量很大,位图很小呢,最极端的情况下会出现,位图的所有格子全被标记为1,无论是否为黑名单的数据,都会被判断为出现在黑名单中,这样就会出现误判。
我们发现错误率p,与k和m都是有关系的,首先如果哈希函数数量k增大的话,p是会减小的;但是k不断增大,那么m会被k消耗的很快,那么m会很快被全覆盖为1,p会趋近100%。那么如何确定k和m呢,是有公式的。
n表示数据量,m表示内存,k表示哈希函数的数量,p表示期望的错误率。
知道了n和p,就可以把最合适的k和m算出来(k和m上取整),最后可以把实际错误率p的算出来
有了这些我们就可把上述题进行求解了,下面是网上看到的题目和题解:

4.一致性哈希和负载均衡
接下来看看一致性哈希和负载均衡,这就涉及到逻辑端如何分配服务器了,假如我们有3个服务器,现在我们看看经典的方式。 但是我们回收服务器呢?这个时候如何去回收一台机器或者加入一台机器4呢,我们就要把所有的机器数据全部再重新进行哈希,再去分配,这样很费时间,数据迁移的代价太高了。
但是我们回收服务器呢?这个时候如何去回收一台机器或者加入一台机器4呢,我们就要把所有的机器数据全部再重新进行哈希,再去分配,这样很费时间,数据迁移的代价太高了。
如何解决呢,我们就不用%的方式来哈希分配。假如我们用MD5算法来进行哈希,我们得到的key就会在0~264-1的范围之内,看下面的图 这样就可以3个服务器负载均衡了,如何找到key对应顺时针最近的服务机器呢,我们在逻辑端可以用一个数值保存每个服务器对应的区间值,然后对这个值进行排序,求出大于key且最左边的数,这个我们可以用二分解决。比如现在数组就是[t2,t1,t3],我们的key最左边大于它的数如果是t1,那么就把它分到服务器1上。
这样就可以3个服务器负载均衡了,如何找到key对应顺时针最近的服务机器呢,我们在逻辑端可以用一个数值保存每个服务器对应的区间值,然后对这个值进行排序,求出大于key且最左边的数,这个我们可以用二分解决。比如现在数组就是[t2,t1,t3],我们的key最左边大于它的数如果是t1,那么就把它分到服务器1上。
那么加入服务器和下线服务器呢?
加入服务器: 下线服务器:
下线服务器:

可是我们发现加入机器和删除机械,还是会有负载不均衡的情况
下面就用到了虚拟节点进行优化

其实也就是我们不再以单一的节点表示一个机械了,而是把机械分成了很多个节点,它们去进行上序的操作。就像是一个机械由很多的小弟,小弟们在环中分别占领的不同的区域,但是最后这些区域都归属与大哥一样。文章来源:https://www.toymoban.com/news/detail-818522.html
这样我们也可以控制机器的负载,如果一个机器的负载能力较差,我们就可以少给它一些虚拟节点,这样它的负载也就可以变小。文章来源地址https://www.toymoban.com/news/detail-818522.html
到了这里,关于哈希函数和哈希表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!