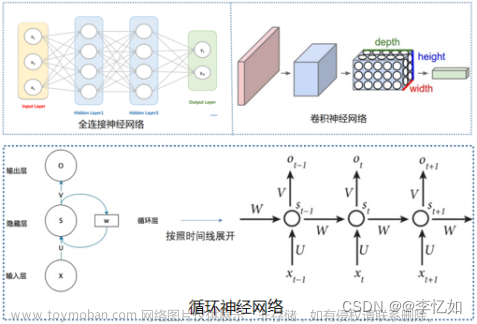
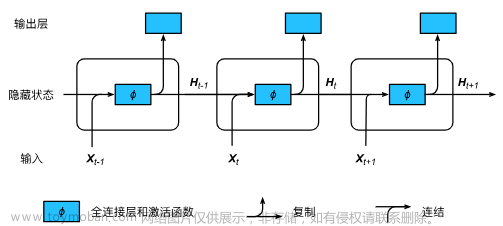
五、应用-语音识别
5.1 语音识别问题


详述语音识别的经典方法GMM+HMM框架

5.2 深度模型
详述DNN-HMM结构


循环神经网络与CTC技术结构用于语音识别问题


六、自然语言处理

RNN-LM建模方法

6.1 中文分词


6.2 词性标注


6.3 命名实体识别


详述LSTM+CRF进行命名实体识别的方法

6.4 文本分类

6.5 自动摘要

6.6 机器翻译

seq2seq技术解决机器翻译问题
seq2seq技术解决机器翻译问题是指利用序列到序列(Sequence to Sequence, Seq2Seq)技术来进行机器翻译的方法,它的基本思想是用一个神经网络作为编码器,将输入的源语言文本编码成一个固定长度的向量,然后用另一个神经网络作为解码器,将编码向量解码成输出的目标语言文本。seq2seq技术是一种通用的序列生成技术,它可以应用于多种自然语言处理任务,如文本摘要、对话系统、图像描述等。seq2seq技术的优点是它可以自动地从大量的平行语料中学习语言的转换规律,提高机器翻译的精度和流畅性。seq2seq技术的缺点是它需要大量的训练数据和计算资源,难以处理复杂的语言结构和语义信息。

双向循环神经网络的机器翻译算法
双向循环神经网络(Bidirectional Recurrent Neural Network,BRNN)的机器翻译算法是一种利用双向循环神经网络对源语言和目标语言进行编码和解码的方法。双向循环神经网络可以同时考虑输入序列的前向和后向信息,从而提高对上下文的理解和捕捉。双向循环神经网络的机器翻译算法的基本结构如下:文章来源:https://www.toymoban.com/news/detail-818535.html
# 假设输入序列为x = (x1, x2, ..., xn),输出序列为y = (y1, y2, ..., ym)
# 定义双向循环神经网络的参数
Wf = # 前向循环神经网络的权重矩阵
bf = # 前向循环神经网络的偏置向量
Wr = # 后向循环神经网络的权重矩阵
br = # 后向循环神经网络的偏置向量
U = # 编码器和解码器之间的权重矩阵
V = # 解码器的权重矩阵
c = # 解码器的偏置向量
# 定义双向循环神经网络的编码器
def encoder(x):
# 初始化前向和后向的隐藏状态
hf = np.zeros((n, d)) # d是隐藏层的维度
hr = np.zeros((n, d))
# 前向传播
for i in range(n):
hf[i] = np.tanh(Wf @ x[i] + bf + Wr @ hf[i-1]) # @表示矩阵乘法
# 后向传播
for i in range(n-1, -1, -1):
hr[i] = np.tanh(Wf @ x[i] + bf + Wr @ hr[i+1])
# 合并前向和后向的隐藏状态
h = np.concatenate((hf, hr), axis=1) # 按列拼接
# 返回编码器的输出
return h
# 定义双向循环神经网络的解码器
def decoder(h, y):
# 初始化解码器的隐藏状态
s = np.zeros((m, 2*d)) # 2*d是双向循环神经网络的输出维度
# 初始化解码器的输出
o = np.zeros((m, k)) # k是输出序列的词汇表大小
# 解码过程
for i in range(m):
s[i] = np.tanh(U @ h[i] + V @ s[i-1]) # 使用编码器的输出作为输入
o[i] = softmax(c + W @ s[i]) # 使用softmax函数计算输出的概率分布
# 返回解码器的输出
return o双向循环神经网络的机器翻译算法的优点是能够更好地捕捉输入序列的双向依赖关系,从而提高翻译的准确性和流畅性。双向循环神经网络的机器翻译算法的缺点是计算复杂度较高,需要更多的参数和训练时间。双向循环神经网络的机器翻译算法的一个改进方案是使用注意力机制(Attention Mechanism),可以动态地选择编码器输出的最相关部分,从而提高翻译的质量和效率.文章来源地址https://www.toymoban.com/news/detail-818535.html
到了这里,关于【机器学习】循环神经网络(四)-应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!