说明
因为我也刚接触知识图谱,就是小白,本篇博客相当于一些入门级的Cypher语句的举例,然后具体说明一下NEO4J Desktop导入CSV文件是怎么实现的,以及他的一些基本操作,适合刚接触的小伙伴。如果大家对于NEO4J的配置有疑问的话可以参考文章NEO4J桌面版的配置和连接Pycharm_neo4j 桌面版-CSDN博客
基本使用方法
1.清空数据,删除之前已有的节点、关系和属性等。
match (n) detach delete n2.展示知识图谱中所有的节点、关系和属性等。
match(n) return n3.创建
创建节点
创建没有属性的节点
创建一个节点,其标签为学生,没有属性。
create (n:学生) 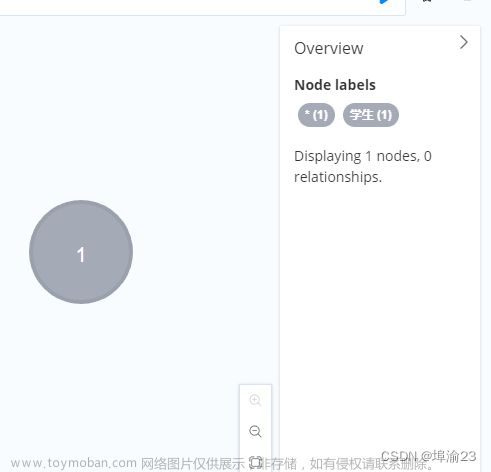
创建包含属性的节点
n代表节点名 学生是节点的标签(label)名 姓名、年龄、性别都是属性名 ,
标签名和属性名不用引号修饰,但是属性值如果是字符串需要加引号
create (n:学生 {姓名:'周杰伦',年龄:40,性别:'男'})
创建多标签的节点
创建一个既是学生又是父亲的节点
CREATE (n:学生:父亲)
我们也可以为周杰伦参加上一个歌手的节点标签
MATCH(学生 {姓名:'周杰伦'}) set 学生:歌手 
创建关系
创建新关系
CREATE (n:埠渝)-[r:LIKES]->(m:周杰伦)
RETURN r如下图所示,会创建出两个新的节点 ,一个新的关系,即新节点+新关系+无属性关系

创建有属性的关系
CREATE (n:学生{姓名:"李四"})-[relation:LIKES{程度:"十分喜爱"}]->(m:老师{姓名:"唐老师"})
下图可以看到,我们新建了一条带属性的关系边。

为现有的节点添加关系
MATCH (n:学生 {姓名:'埠渝'}), (m:歌手 {姓名:'周杰伦'})
CREATE (n)-[r:likes]->(m)
RETURN n, r, m;

当然也可以增加一定的限制条件,比如说ID。这里的id要注意是自己电脑上的。
MATCH (n:学生 ), (m:歌手)
where id(m)=11 and id(n)=12
CREATE (n)-[r:DIS]->(m)
RETURN n, r, m;

4.查询
查找节点相关信息
查找节点
其中这个学生是我们要查询的节点的标签(label),where里的事节点的属性,可以用来筛选节点标签是学生中,我们要去查询的是哪一个。
match (n:学生) where n.姓名='埠渝' return n

查询节点的标签
也就是说像前面所说的,我们为周杰伦创建了两个节点标签学生和歌手,意思就是把周杰伦这个节点对应的所有标签都查询出来。
MATCH (a:学生) where a.姓名='周杰伦' RETURN labels(a)
查询节点的属性值
MATCH (a:学生) where a.姓名='埠渝' RETURN properties(a)
查询节点的属性键
MATCH (a:学生) where a.姓名='埠渝' RETURN keys(a)这里我们可以和上边的图对应一下,就很容易理解是什么意思了。

查找与当前节点有关系的的节点
查找李四所有有关系的老师的姓名
MATCH (n:学生 { 姓名 : '李四' })-->(m:老师)
RETURN m.姓名
查找李四所有喜欢的老师的姓名
MATCH (n:学生 { 姓名 : '李四' })-[r:LIKES]->(m:老师)
RETURN m.姓名
查找关系
查询节点间的关系
查询埠渝和周杰伦间的关系类型
match(a) where a.姓名='埠渝' match(b) where b.姓名='周杰伦' match p=(a)-[r]->(b) return type(r)
查询关系的所有属性
查询李四和唐老师之间的关系的所有属性

查询节点间关系的属性键
match(a) where a.姓名='李四' match(b) where b.姓名='唐老师' match p=(a)-[r]->(b) return keys(r)
5.删除
删除节点的所有相关关系
注意这里是没有箭头的
MATCH (n:学生{姓名:'埠渝'})-[r]-()
DELETE r删除节点的所有外向关系
这里就是有剪头的了
MATCH ()-[r]->(n:老师{姓名:'唐老师'})
DELETE r删除某个检点的某类关系
MATCH (n:学生{姓名:'埠渝'})-[r:LIKES]-()
DELETE r删除实体的属性
MATCH (n:学生{姓名:'埠渝'})
REMOVE n.性别删除所有节点和关系
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n,r6.修改
修改节点属性
create(n:学生{姓名:'埠渝',年龄:23})
MATCH (n:学生{姓名:'埠渝'})
SET n.姓名='王哥'修改节点标签
MATCH (n:学生{姓名:'王哥'})
REMOVE n:学生
SET n:青年修改关系的类型
MATCH (n:学生)-[r:LIKES]-(m:歌手)
WHERE n.姓名='埠渝' and m.姓名='周杰伦'
CREATE (n)-[r2:HATES]->(m)
DELETE rNEO4J Desktop导入CSV文件
数据准备
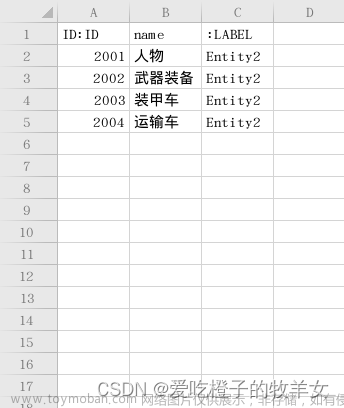
将数据另存为下边的这个文件格式。

放入NEO4J中
这里像这样点击找到这个import ,会打开这个文件夹,这时候我们把上边的CSV文件保存到文件夹里就可以了。


代码
打开Neo4j Browser,输入下列代码
load csv with headers from "file:///PersonD.csv" as PersonD return PersonD输出结果如下方所示,得到文件对应的结构化信息

创建节点
通过下列代码可以将文件里的人都抽出来创建节点,节点的标签为人,节点有一个属性姓名
load csv with headers from "file:///PersonD.csv" as PersonD
merge (A:人{姓名:PersonD.人})
return count(A)
当然,我们不用上边的代码,用下边的代码就可以把文件里所有的属性都给节点带上了。
load csv with headers from "file:///PersonD.csv" as PersonD
merge (A:人{姓名:PersonD.人,三种人:PersonD.三种人,党员:PersonD.党员,身份证号:PersonD.身份证号码,年龄:PersonD.年龄})
return count(A)
依据CSV数据创建关系
准备数据
保存在上述所说的import文件夹里。

创建节点
分别输入下列两段代码,创建节点
load csv with headers from "file:///PersonD1.csv" as PersonD1
merge (f:公民{公民:PersonD1.公民})
return count(f)load csv with headers from "file:///PersonD1.csv" as PersonD1
merge (B:身份{身份:PersonD1.身份})
return count(B)结果如下图所示。

建立关系
输入下列代码,可以将身份和公民之间建立关系。
load csv with headers from "file:///PersonD1.csv" as PersonD1
MATCH (f:公民{公民:PersonD1.公民})
MATCH (B:身份{身份:PersonD1.身份})
MERGE (f)-[r:身份是]->(B)
效果图,如下。

Create和Merge的区别
Create:
-
CREATE用于创建节点、关系或者属性,如果给定的模式已经存在,CREATE会强制性地创建新的节点、关系或属性,即使相同的模式已经存在于数据库中。 - 它总是创建新的模式,不管之前是否存在相同的模式。
Merge:
-
MERGE也用于创建节点、关系或者属性,但它会首先尝试在数据库中查找给定的模式。如果找到了匹配的模式,则不会创建新的,而是将现有的模式返回。 - 如果没有找到匹配的模式,则会创建新的模式。
总的来说:
CREATE 总是创建新的模式,而 MERGE 会先查找是否已经存在相同的模式,存在则返回,不存在则创建。在需要确保模式的唯一性时,MERGE 是一个很有用的工具,可以避免重复创建相同的节点、关系或属性。
报错
如果出现这个报错,他的原因就是你的表格里的数据他不同列的个数不一样,比如说第一列20个,第二列19个,这样的话,你去读第一列(最长的这列)时不会出错,但是去读第二列的时候就会出错,就是因为你列表里的数据不一样长。文章来源:https://www.toymoban.com/news/detail-819358.html
Neo.ClientError.Statement.SemanticError Cannot merge the following node because of null property value for 文章来源地址https://www.toymoban.com/news/detail-819358.html
欢迎大家有问题在评论区打出来,或者博客有什么问题,欢迎指正。
到了这里,关于NEO4J的基本使用以及桌面版NEO4J Desktop导入CSV文件的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!