个人阅读笔记,如有错误欢迎指出!
会议:2021 S&P Detecting AI Trojans Using Meta Neural Analysis | IEEE Conference Publication | IEEE Xplore
问题:
当前防御方法存在一些难以实现的假设,或者要求直接访问训练模型,难以在实践中应用。
创新:
通过元分类器来预测给定目标模型是否被后门攻击。该方法不对攻击策略进行假设,仅为黑盒访问。
为了在不了解攻击策略的情况下训练元模型,提出了jumbo learning,按照一般分布对一组特洛伊模型进行采样。然后将查询集与元分类器一起动态优化,以区分木马和良性模型。
方法:
构建多个影子模型,将影子模型和影子模型的标签一同输入到元分类器中对影子模型进行分类。
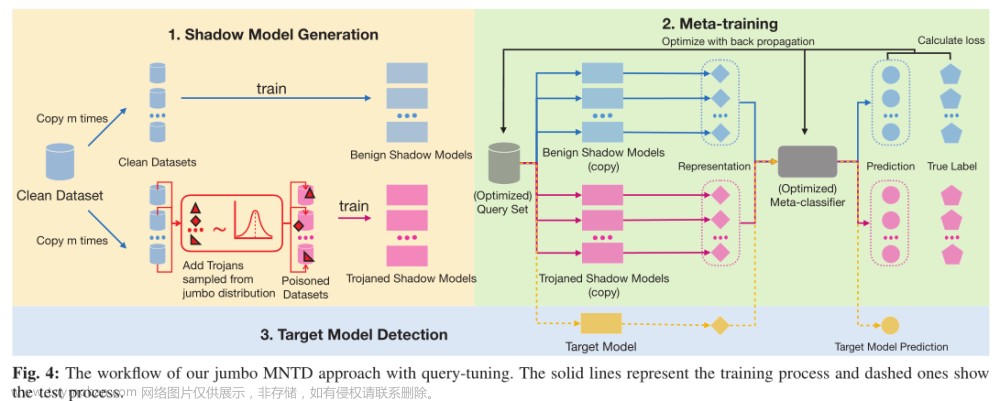
1、影子模型生成。生成了一组良性和木马影子模型。使用相同的干净数据集和不同的模型初始化来训练良性模型。对于木马模型提出了一个通用的木马分布,并从中采样了各种木马设置,并应用到中毒攻击生成不同的木马影子模型中。
2、元训练。设计特征提取函数来获得影子模型的表示向量,并训练元分类器来检测后门模型。通过查询得到一组结果向量作为标签,并把该结果向量和影子模型的表示向量一同输入到元分类器中进行训练。在训练迭代中优化分类器和查询集。
3、目标模型检测。给定一个目标模型,利用优化的查询集来提取模型的表示。然后,我们将表示提供给元分类器,预测是否是后门模型。
1、影子模型的生成
jumbo learning:
对不同后门设置进行建模并生成不同后门模型。是有毒样本和中毒标签,是trigger的shape和位置,是图案,是透明度。

通过随机采样来获得不同的后门设置,下图是采样的后门示例。

对每种中毒设置都训练其相应的影子模型,伪代码如下。首先随机采样木马攻击设置(第3行)。然后根据设置毒害数据集(第4-8行),并训练木马阴影模型(第9行)。多次重复这个过程以生成一组不同的木马模型。采样算法(第3行)和模型训练算法(第9行)对于不同的任务将是不同的。

2、元训练:基于上述生成的后门影子模型训练元分类器。
特征提取函数:将一组查询提供给阴影模型,并使用输出向量作为其表示特征。对于影子模型有二进制标签表示该影子模型是良性or中毒。输入查询影子模型得到个向量。通过串联所有的输出向量,可以得到表示向量作为影子模型的特征

元分类器:两层全连接网络
元训练:希望同时优化查询集和元分类器的参数。随机选择查询集,预先计算所有表示向量,并且仅优化元分类器。对于具有和相应的标签,元训练只是通过基于梯度的优化来最小化二元分类器的损失:

用损失函数同时优化查询集和元分类器的参数

仅在良性影子模型上训练的元分类器
训练模型以确定输入是否与其训练样本相似。如SVM将训练超平面,该超平面将所有训练数据与原点分离,同时最大化从原点到超平面的距离ρ
本文使用了一类神经网络,优化目标如下:

3、目标模型检测
将模型表示向量输入到元分类器中,预测其标签
实验:





 文章来源:https://www.toymoban.com/news/detail-819386.html
文章来源:https://www.toymoban.com/news/detail-819386.html
 文章来源地址https://www.toymoban.com/news/detail-819386.html
文章来源地址https://www.toymoban.com/news/detail-819386.html
到了这里,关于【论文阅读笔记】Detecting AI Trojans Using Meta Neural Analysis的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[论文阅读笔记25]A Comprehensive Survey on Graph Neural Networks](https://imgs.yssmx.com/Uploads/2024/02/674898-1.png)








