1. 介绍
差值哈希算法(Difference Hash Algorithm,简称dHash) 是哈希算法的一种,主要可以用来做以图搜索/相似图片的搜索工作。
文章来源:https://www.toymoban.com/news/detail-819490.html
2. 原理
差值哈希算法通过计算相邻像素的差异来生成哈希,即通过缩小图像的每个像素与平均灰度值的比较,生成一组哈希值。最后,利用两组图像的哈希值的汉明距离来评估图像的相似度。
3. 魔法
概括地讲,差值哈希算法一共可细分五步:
- 缩小图像: 调整输入图像的大小为 (hash_size + 1) 宽度和 hash_size 高度,通常为 9x8 像素,总共72个像素。
- 图像灰度化: 将彩色图像转换为灰度图像,以便进行灰度差值计算。
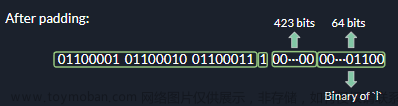
- 计算差异值: 差值算法工作在相邻像素之间,如果左边的像素比右边的更亮,则记录为1,否则为0,这样每行9个像素通过左右像素的两两比较,会产生8个不同的差异值,一共8行,则会产生64个差异值。
- 生成哈希值: 由于64位的二进制值(差异值)太长,所以按每4个字符为1组,由2进制转成16进制。这样就转为一个长度为16的字符串。这个字符串也就是这个图像可识别的哈希值,也叫图像指纹,即这个图像所包含的特征。
- 哈希值比较: 通过比较两个图像的哈希值的汉明距离(Hamming Distance),就可以评估图像的相似度,距离越小表示图像越相似。
4. 实验
4.1 魔法
第一步:缩小图像
调整输入图像的大小为 (hash_size + 1) 宽度和 hash_size 高度,通常为 9x8 像素,总共72个像素,以便进行后续的差值计算。
1)读取原图
# 测试图片路径
img_path = 'img_test/apple-01.jpg'
# 通过OpenCV加载图像
img = cv2.imread(img_path)
plt.imshow(img, cmap='gray')
plt.show()
# 通道重排,从BGR转换为RGB
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb, cmap='gray')
plt.show()
2)缩小原图
# 缩小图像:使用OpenCV的resize函数将图像缩放为9x8像素,采用Cubic插值方法进行图像重采样
img_resize = cv2.resize(img_rgb, (9, 8), cv2.INTER_CUBIC)
# 打印 img.shape 可以获取图像的形状信息,即 (行数, 列数, 通道数)
# 通道数:灰度图像通道数为 1,彩色图像通道数为 3
print(img_resize.shape)
plt.imshow(img_resize, cmap='gray')
plt.show()
输出打印:
(8, 9, 3)

将图像 img 调整大小为 (9, 8) 的尺寸,并使用 cv2.INTER_CUBIC 插值方法进行图像的缩放。在这里,原始图像 img 将被调整为 9 像素宽和 8 像素高。
打印 img.shape 可以获取图像的形状信息,即(行数, 列数, 通道数)。通道数取决于原始图像的通道数(如灰度图像通道数为 1,彩色图像通道数为 3)。
第二步:图像灰度化
将彩色图像转换为灰度图像,以便进行灰度差值计算。
# 图像灰度化:将彩色图像转换为灰度图像。
img_gray = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
# 打印出了灰度图像的行数和列数,因为灰度图像只有一个通道,所以不会显示通道数
print(img_gray.shape)
plt.imshow(img_gray, cmap='gray')
plt.show()
输出打印:
(8, 9)
使用 OpenCV 的 cvtColor 函数将彩色图像 img 转换为灰度图像。cv2.COLOR_BGR2GRAY 是颜色空间转换标志,它指示将图像从 BGR(彩色)颜色空间转换为灰度颜色空间。
打印 img_gray.shape 包含图像的维度信息,通常是(行数, 列数)或(行数, 列数, 通道数)。这里只有灰度图像的行数和列数,因为灰度图像只有一个通道,所以不会显示通道数。
第三步:计算差异值
差值算法工作在相邻像素之间,如果左边的像素比右边的更亮,则记录为1,否则为0,这样每行9个像素通过左右像素的两两比较,会产生8个不同的差异值,一共8行,则会产生64个差异值。
# 计算差异值:获得图像二进制字符串
img_hash_str = ''
# img_hash_arr = []
# 遍历图像的像素,比较相邻像素之间的灰度值,根据强弱增减差异情况生成一个二进制哈希值
# 外层循环,遍历图像的行(垂直方向),范围是从0到7
for i in range(8):
# 内层循环,遍历图像的列(水平方向),范围也是从0到7
for j in range(8):
# 比较当前像素 img[i, j] 与下一个像素 img[i, j + 1] 的灰度值
if img_gray[i, j] > img_gray[i, j + 1]:
# 如果当前像素的灰度值大于下一个像素的灰度值(灰度值增加),将1添加到名为 hash 的列表中
# img_hash_arr.append(1)
img_hash_str += '1'
else:
# 否则灰度值弱减,将0添加到名为 hash 的列表中
# img_hash_arr.append(0)
img_hash_str += '0'
print(f"图像的二进制哈希值={img_hash_str}")
输出打印:
图像的二进制哈希值=0000000000110000001100000010000001110000001000000011000001110000
这段代码的目的是遍历图像的每一行和每一列,逐个比较相邻像素之间的灰度值,根据比较结果生成一个二进制哈希值。如果像素之间的灰度值增加,就将1添加到哈希值中,如果减少或保持不变,就将0添加。这个生成的哈希值可用于图像相似性比较,用于检测图像中的局部特征。
第四步:生成哈希值
由于64位二进制值太长,所以按每4个字符为1组,由2进制转成16进制。这样就转为一个长度为16的字符串。这个字符串也就是这个图像可识别的哈希值,也叫图像指纹,即这个图像所包含的特征。
# 生成哈希值:生成图像可识别哈希值
img_hash = ''
for i in range(0, 64, 4):
img_hash += ''.join('%x' % int(img_hash_str[i: i + 4], 2))
print(f"图像可识别的哈希值={img_hash}")
输出打印:
图像可识别的哈希值=0030302070203070
同样的,将目标素材图像进行上述计算,亦可得到一个图像可识别的哈希值。
第五步:哈希值比较
通过两个等长字符串在相同位置上不同字符的数量,计算两个等长字符串之间的汉明距离(Hamming Distance),就可以评估图像的相似度,距离越小表示图像越相似。
# 汉明距离:通过两个等长字符串在相同位置上不同字符的数量,计算两个等长字符串之间的汉明距离
def hamming_distance(s1, s2):
# 检查这两个字符串的长度是否相同。如果长度不同,它会引发 ValueError 异常,因为汉明距离只适用于等长的字符串
if len(s1) != len(s2):
raise ValueError("Input strings must have the same length")
distance = 0
for i in range(len(s1)):
# 遍历两个字符串的每个字符,比较它们在相同位置上的值。如果发现不同的字符,将 distance 的值增加 1
if s1[i] != s2[i]:
distance += 1
return distance
汉明距离: 两个等长字符串在相同位置上不同字符的数量。即一组二进制数据变成另一组数据所需要的步骤数。汉明距离越小,则相似度越高。汉明距离为0,即两张图片完全一样。

4.2 测试
实验场景
通过 opencv,使用差值哈希算法查找目标图像素材库中所有相似图像,并列出相似值。
实验素材
这里,我准备了10张图片,其中9张是苹果,但形态不一;1张梨子。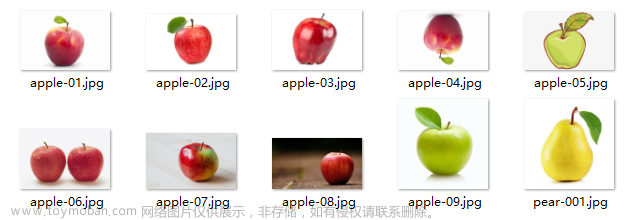
实验代码
"""
以图搜图:差值哈希算法(Difference Hash Algorithm,简称dHash)的原理与实现
测试环境:win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1
实验场景:通过 opencv,使用差值哈希算法查找目标图像素材库中所有相似图像
实验时间:2023-10-31
实验名称:dhash_v5_all.py
"""
import os
import cv2
import time
def get_dHash(img_path):
# 读取图像:通过OpenCV的imread加载RGB图像
img_rgb = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)
# 缩小图像:使用OpenCV的resize函数将图像缩放为9x8像素,采用Cubic插值方法进行图像重采样
img_resize = cv2.resize(img_rgb, (9, 8), cv2.INTER_CUBIC)
# 图像灰度化:将彩色图像转换为灰度图像
img_gray = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
# 计算差异值:获得图像二进制字符串
img_hash_str = ''
# 遍历图像的像素,比较相邻像素之间的灰度值,根据强弱增减差异情况生成一个二进制哈希值
# 外层循环,遍历图像的行(垂直方向),范围是从0到7
for i in range(8):
# 内层循环,遍历图像的列(水平方向),范围也是从0到7
for j in range(8):
# 比较当前像素 img[i, j] 与下一个像素 img[i, j + 1] 的灰度值
if img_gray[i, j] > img_gray[i, j + 1]:
# 如果当前像素的灰度值大于下一个像素的灰度值(灰度值增加),将1添加到名为 hash 的列表中
img_hash_str += '1'
else:
# 否则灰度值弱减,将0添加到名为 hash 的列表中
img_hash_str += '0'
# print(f"图像的二进制哈希值={img_hash_str}")
# 生成哈希值:生成图像可识别哈希值
img_hash = ''.join(map(lambda x:'%x' % int(img_hash_str[x : x + 4], 2), range(0, 64, 4)))
return img_hash
# 汉明距离:通过两个等长字符串在相同位置上不同字符的数量,计算两个等长字符串之间的汉明距离
def hamming_distance(str1, str2):
# 检查这两个字符串的长度是否相同。如果长度不同,它会引发 ValueError 异常,因为汉明距离只适用于等长的字符串
if len(str1) != len(str2):
raise ValueError("Input strings must have the same length")
distance = 0
for i in range(len(str1)):
# 遍历两个字符串的每个字符,比较它们在相同位置上的值。如果发现不同的字符,将 distance 的值增加 1
if str1[i] != str2[i]:
distance += 1
return distance
# ------------------------------------------------- 测试 -------------------------------------------------
if __name__ == "__main__":
time_start = time.time()
# 指定测试图像库目录
img_dir = 'img_test'
# 指定测试图像文件扩展名
img_suffix = ['.jpg', '.jpeg', '.png', '.bmp', '.gif']
# 获取当前执行脚本所在目录
script_dir = os.path.dirname(__file__)
# 获取目标测试图像的全路径
img_org_path = os.path.join(script_dir, img_dir, 'apple-01.jpg')
# 获取目标图像可识别哈希值(图像指纹)
org_img_hash = get_dHash(img_org_path)
print(f"目标图像:{os.path.relpath(img_org_path)},图像HASH:{org_img_hash}")
# 获取测试图像库中所有文件
all_files = os.listdir(os.path.join(script_dir, img_dir))
# 筛选出指定后缀的图像文件
img_files = [file for file in all_files if any(file.endswith(suffix) for suffix in img_suffix)]
img_hash_all = []
# 遍历测试图像库中的每张图像
for img_file in img_files:
# 获取相似图像文件路径
img_path = os.path.join(script_dir, img_dir, img_file)
# 获取相似图像可识别哈希值(图像指纹)
img_hash = get_dHash(img_path)
# 获取相似图像与目标图像的汉明距离
distance = hamming_distance(org_img_hash, img_hash)
# 存储相似图像的相对路径、哈希值、汉明距离
img_hash_all.append((os.path.relpath(img_path), img_hash, distance))
for img in img_hash_all:
print(f"图像名称:{os.path.basename(img[0])},图像HASH:{img[1]},与目标图像的近似值(汉明距离):{img[2]}")
time_end = time.time()
print(f"耗时:{time_end - time_start}")
输出打印:
目标图像:..\..\P1_Hash\03_dHash\img_test\apple-01.jpg,图像HASH:0030302070203070
图像名称:apple-01.jpg,图像HASH:0030302070203070,与目标图像的近似值(汉明距离):0
图像名称:apple-02.jpg,图像HASH:2048502430301000,与目标图像的近似值(汉明距离):9
图像名称:apple-03.jpg,图像HASH:0030705070506020,与目标图像的近似值(汉明距离):5
图像名称:apple-04.jpg,图像HASH:3030303038301000,与目标图像的近似值(汉明距离):7
图像名称:apple-05.jpg,图像HASH:0818206840602830,与目标图像的近似值(汉明距离):11
图像名称:apple-06.jpg,图像HASH:00004cccd0c8eeec,与目标图像的近似值(汉明距离):12
图像名称:apple-07.jpg,图像HASH:5af53928b158dc1e,与目标图像的近似值(汉明距离):14
图像名称:apple-08.jpg,图像HASH:87868a060c081e2c,与目标图像的近似值(汉明距离):16
图像名称:apple-09.jpg,图像HASH:0040285060602070,与目标图像的近似值(汉明距离):7
图像名称:pear-001.jpg,图像HASH:0204367274f07060,与目标图像的近似值(汉明距离):10
耗时:0.09773826599121094
5. 总结
经过实验和测试,差值哈希算法(dHash)是一种非常简单的算法,易于实现和理解,且计算速度快,适用于大规模图像数据相似性处理。
特点: 传统,属于一种外观相似哈希算法。
优点: 简单、相对准确、计算效率高;在同等测试样本下,相比pHash,dHash的速度要更快;适用于快速图像相似性搜索。
缺点: 对于图像的旋转和缩放敏感,不适用于检测嵌入式水印或复杂的变换,即使是微小的旋转或缩放也会导致哈希值大幅度改变,因为它主要用于检测左右局部像素级别的变化。
6. 系列书签
OpenCV书签 #均值哈希算法的原理与相似图片搜索实验
OpenCV书签 #感知哈希算法的原理与相似图片搜索实验
OpenCV书签 #差值哈希算法的原理与相似图片搜索实验文章来源地址https://www.toymoban.com/news/detail-819490.html
到了这里,关于OpenCV书签 #差值哈希算法的原理与相似图片搜索实验的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!