1.背景
1.1 项目背景和遇到的问题
当时在某个公司做tob私有化的后端研发工作,工作中需要给某个媒体公司提供推荐服务。
项目的后端模块使用java+sprintBoot+maven开发,算法模块采用python开发,部署方式分两种:jar包部署(测试环境)和kubernetes+docker的部署(部署在线上环境中)。
客户提供的环境:5台需要vpn连接的虚拟机。每台配置:内存32G(猜测是因为压缩指针技术?),硬盘500G。另外有一个10T的SSD(印象有点模糊了,也有可能是NFS盘)用于存放大量用户点展数据,每天的数据量约3G,周末高峰期有约5G(大致数据)。部署在客户环境的时候,一般是拿单独的测试机器来作为测试环境,每台机器都装有redis和ES,其中四台机器的redis和ES都是集群模式,另外有一台单独测试机器,ES和redis是单点模式。
在项目持续了一段时间后,发现线上经常出现下列问题,导致排查问题起来手忙脚乱。
| 存在问题 | 具体原因 | 影响程度 | 备注 |
| 原始用户数据(点展数据)丢失 | 客户的数据同步有问题 | 大 | 算法需要使用原始数据进行模型训练,缺少原始数据导致算法的训练延时产出 |
| 磁盘占满 | 1. k8s重启之后,之前的pod会有新的pod name,于是日志也会有新的pod后缀,旧的pod的日志无法被及时清理,导致日志积累过多; 2. 算法模型的启动日志很大; |
大 | 1.并不知道为什么算法的启动日志特别大; 2.磁盘被打满会导致服务的pod出故障,会进入pending状态并最终进入Failed状态; |
| 错误日志 | 错误日志有各种问题,整理一下主要有以下问题导致: 1.调用召回模型失败; 2.调用排序模型失败; 3.某个服务宕机(极少); |
中 | 虽然打印了错误日志说明代码逻辑上是有问题的,但是多路召回和排序阶段后端都有做兜底策略,多路召回只要有一路成功即可进入下一环节,排序如果失败会进行混洗,即将结果打乱进行展示 |
| 数据清洗失败 | 使用组内自研的某个框架进行数据清洗,使用linux进行定时任务,但是会有延迟产出或者产出的问题 | 中 | 数据清洗不及时也是会导致算法训练产出的延时,但大部分遇到的场景都是客户的原始数据没有及时发送导致的。 |
| 某阶段耗时过多 | 曾经有算法模型更新,换了个效果更好的但是耗时更多的模型,导致耗时较多 | 小 | 客户对耗时的要求不是很高,影响不大 |
| 内存使用较多 | 工作期间基本没有遇到过 | 小 | 无 |
| GC频繁 | 工作期间基本没有遇到过 | 小 | 无 |
另外研发希望看到后端和算法迭代之后,点展比、点击率、展示数、PV、UV等数据的变化,希望能整合到监控中。
由于以上的问题,leader提出了搭建监控和报警系统的需求。在相关负责的架构师的带领下,组内开始了相关的工作。
1.2 项目整理的监控和报警需求
基于以上的种种问题,在架构师带领下,整理了相关的监控和报警需求。
| 内容 | 报警or监控? | 需求度 | 备注 |
| 原始用户数据丢失 | 报警+监控 | 高 | 报警是为了第一时间知道问题,监控是为了能大概知道客户的每日产出时间; |
| 磁盘占用 | 报警+监控 | 高 | 处理方式:及时报警,接到报警后及时清理磁盘; |
| 后端错误日志 | 报警+监控 | 中 | 方便及时排查问题; |
| 数据清洗失败 | 报警 | 高 | 数据清洗失败不容易抽象成指标,也没有监控的线程方法,设计上有难度 |
| 请求耗时 | 报警+监控 | 监控高,报警低 | 线上请求超时的case其实不多,报警的需求其实不高; |
| 微服务调用失败和微服务健康监控 | 报警+监控 | 高 | 研发希望有服务调用的拓扑图; |
| Java基本参数: 内存使用、JVM分布、 GC次数 |
监控 | 中 | 属于基本需求,但并不是项目中需要及时面对的问题; |
| 点展比、点击率、展示数、PV、UV | 监控 | 中 |
2.监控选型
在选型过程中,架构师整理了前东家其他团队的工作,基于已有的成熟技术,主要着眼于两个技术框架:skywalking和prometheus。
2.1 skywalking
参考文档:SkyWalking 极简入门 | Apache SkyWalking
skywalking是一个分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。
skywalking提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。
skywalking架构图:

架构图比较复杂。重点总结几个skywalking的特点:
1. 提供封装好的重要指标,比如qps、请求耗时、etc,同时自带UI功能,不需要额外接入grafana等UI组件;
下图是查看仪表盘:

参考:Skywalking全链路追踪使用说明_张维鹏的博客-CSDN博客_全链路追踪skywalking

下图是查看网络拓扑:

 下图是查看调用链路
下图是查看调用链路


另外也支持对mysql数据库的信息查询:

2. 与此对应的,skywalking对于自定义指标的metrics的支持很差
也就是说,如果想要实现一些自定义的指标,比如:每日到达网站的VIP用户数和VIP行为数据,skywalking就支持的很不好(注:新版本的skywalking支持接入prometheus的自定义指标,参考:SkyWalking 8.4 provides infrastructure monitoring | Apache SkyWalking);
3. 数据默认存储在ElasticSearch
Skywalking框架没有设计新的数据库,而是把数据默认存放在ES当中,官方也支持将数据存储到Mysql当中。
这种数据存储设计,优点上是:减少了中间件数量;缺点也很明显:如果项目中用到了ES,不利于ES数据的管理;
4. 支持链路追踪
skywalking的链路追踪功能,是基于context实现的,具体实现中,会讲全局唯一ID编译进http的请求head当中。具体实现细节参考:分布式链路追踪原理详解及SkyWalking、Zipkin介绍 - 腾讯云开发者社区-腾讯云
另外当前的链路追踪设计都参考了谷歌的Dapper,参考文章:Dapper,大规模分布式系统的跟踪系统 by bigbully
5. 安装和配置较为方便,适合快速部署
具体安装参考:SkyWalking 极简入门 | Apache SkyWalking
主要是启动java服务、启动skywalking的OAP服务,启动agent、启动skywalking UI,具体不赘述。
6. 使用了java-agent 指标
和prometheus的metric指标有所区别,此处不赘述
7. 告警支持较弱
SkyWalking是不支持直接向邮箱、短信等服务发送告警信息的,SkyWalking只会在发生告警时将告警信息发送至配置好的Webhook接口,因此需要自己实现WebHook来进行告警。具体参考:
SkyWalking - 实现微服务监控告警_51CTO博客_微服务监控告警
2.2 prometheus调研与选型。
时序数据库(TSDB)简介:
时序数据是随时间不断产生的一系列数据,简单来说,就是带时间戳的数据。时序数据库 (Time Series Database,TSDB) 是优化用于摄取、处理和存储时间戳数据的数据库。此类数据可能包括来自服务器和应用程序的指标、来自物联网传感器的读数、网站或应用程序上的用户交互或金融市场上的交易活动。(参考:时序数据库入门系列:什么是时序数据库 - 知乎)


市面上有很多成熟的时序数据库,比如influxDB,实际上某些大厂早期的监控也是基于influxDB实现的。
prometheus时序数据库:
Prometheus作为一个独立地开源监控系统和告警工具,是继Kubernetes之后加入CNCF(Cloud Native Computing Foundation,云原生计算基金会)的第二个项目,算是根正苗红的云原生监控系统
prometheus本身是一个云原生数据框架,但在这个框架下,prometheus是一个时序数据库(是不是有点绕)……
下图是prometheus监控系统的架构图(参考文档:终于有人把Prometheus入门讲明白了 - DockOne.io):

根据以上架构图可以简单整理出一些prometheus的特点:
1. 架构较为复杂,看起来需要启动多个服务;
2. 云原生,支持k8s等CNCF原生组件;
3. 自带PfromQL,具有一套特定的语法;
4. 需要外部UI支持;
5. 支持告警;
具体安装教程参考:
Prometheus监控系统 安装与配置详细教程 - ExplorerMan - 博客园
关于告警规则:
参考官方文档Alerting rules | Prometheus,prometheus的告警规则是写在yml文件中的:

可以通过配置consul或者nacos等配置中心来管理告警规则。
ui选型选型
UI选型上,没有做太多工作,直接选择了grafana,这也是prometheus官方推荐的UI框架。
除了prometheus之外,grafana还支持多种中间件,包括ElasticSearch、MySQL、PoastgreSQL、InfluxDB、OpenTSDB、CloudWath、Zabbix,等等。更多信息参考:
Data sources | Grafana documentation

另外grafana已经提供了多种现成的dashaborad模板,参考:
Dashboards | Grafana Labs
这是一个常用的JVM监控模板(JVM (Micrometer) | Grafana Labs),部分截图如下:

各种眼花缭乱的并且现成的监控模板也是选择Grafana的一大原因
alert-manager
alert-manager是属于prometheus框架的一部分,主要作用是接受promtheus的阈值报警并进行转发。下图是官方aler-manager架构图(参考:Prometheus监控神器-Alertmanager篇(4) - 腾讯云开发者社区-腾讯云)

1. 从左上开始,Prometheus 发送的警报到 Alertmanager;
2. 警报会被存储到 AlertProvider 中,Alertmanager 的内置实现就是包了一个 map,也就是存放在本机内存中,这里可以很容易地扩展其它 Provider;
3. Dispatcher 是一个单独的 goroutine,它会不断到 AlertProvider 拉新的警报,并且根据 YAML 配置的 Routing Tree 将警报路由到一个分组中;
4. 分组会定时进行 flush (间隔为配置参数中的 group_interval), flush 后这组警报会走一个 Notification Pipeline 链式处理;
5. Notification Pipeline 为这组警报确定发送目标,并执行抑制逻辑,静默逻辑,去重逻辑,发送与重试逻辑,实现警报的最终投递;
简单来说,alert-manager主要工作,就是对prometheus数据库发送过来的报警消息进行整理和路由分发,同时还有一些去重、静默(silence,也就是屏蔽)等功能。
以上参考了:搞搞 Prometheus: Alertmanager 解析 - 知乎
技术实现仅供参考,真正部署中不需要太在意技术实现细节。
指标类型
prometheus提供了四种指标类型:counter,gauge,histogram,summary
四种指标类型的简单介绍
| 指标 | 特点 | 备注 | case |
| Counter | 只增不减的计数器(除非发生系统重置) | 基于时间数据进行累加 | 用于统计用户总数、到达总数、网页访问量等; |
| Gauge | 可增可减的仪表盘 | 可使用PromSql进行方差计算 |
用户查询当前磁盘用量、内存消耗等实时数据; |
| Histogram | 直方图,注重区间上的统计分析; | 请求耗时、磁盘用量、GC等的分析(偏区间) | |
| Summary | 摘要,注重概率上的统计分析 | 请求耗时、磁盘用量、GC等的分析(偏概率) |
下图是Histogram的一个实例:

下图是summary的一个实例:

具体参考:Metric types | PrometheusMetrics类型 - prometheus-book
总体而言,Counter和Gauge属于比较好理解的指标,Histogram和Summary属于比较难以理解的两个指标(可能需要一定的概率论知识),某种程度上Histogram和Summary指标可以认为是基于一个基础指标进行一系列统计分析的结果,一般来说实际项目中用到的也少。但是在进行数据分析和性能分析时,Histogram和Summary可以提供很多有效参考信息。
3.监控架构
3.1 架构图

3.2 架构图解释与说明
1. 根据上图的架构图可以看出,实际上监控架构的核心还是Exporter(包括微服务本身暴露的指标)+prometheus+Grafana实现的,其他部分都可以认为是比较可插拔的模块。
2. 图中可见涉及到的监控服务包括:nacos, skywalking,exporter,Grafana, alert-manager, flask,skywalking,服务文件较多,管理起来也比较复杂,其实最好是有一个微服务编排管理的工具,比如service mesh或者spring cloud,但是最后时间问题没有调研和实现。
注:其中的flask应该是参考了此类文档:prometheus中使用python手写webhook完成告警 - 腾讯云开发者社区-腾讯云
目前看到的消息,alert-manager已经支持对企业微信的报警了:Prometheus + Alertmanager 实现企业微信告警_mb5fdb1365b75a0的技术博客_51CTO博客
也就说架构图中的flask服务可以移除。
3. 在最后的实际使用中,skywalking实际上并没有发挥报警功能,我们也主要是将skywalking作为一个看板,这主要是因为业务场景导致的,个人认为skywalking更适合作为项目初期的一个通用监控模块,对网络、数据库、磁盘等进行监控即可。
4. 报警方式上,最后只使用了企业微信报警(拉了专门的报警群)和邮件报警。另外也可以实现前东家内部沟通IM软件的报警,但最后因为没啥意义就pass了。
4.实战与部署
4.1 如何实现需要的指标
在编程中,发现需要实现的报警指标主要分为以下几种:
1. GC数据,JVM,QPS,响应耗时等基本数据,这些网上有较多教程。其中GC、JVM、磁盘占有率等数据通过spring暴露的metric指标,配合grafana的一些模板就能实现;QPS和响应耗时(P99,P95,,P90等)通过配置skywalking也可以可视化
2. 原始用户数据丢失(传输不及时):用go语言开发Exporter实现即可。由于客户提供的点展数据文件前缀保持不变,后缀是天级别时间戳,所以使用正则,每天生成的指标定时扫描指定的文件大小,然后发送到prometheus生成相应的指标即可;
springboot接入skywalking教程参考,可见skywalking对springboot的接入几乎是无侵入的,连依赖都不需要添加:
Springboot接入SkyWalking分布式链路追踪 - 掘金
springboot接入prometheus参考:
SpringBoot应用接入Prometheus的全过程解析 - 知乎
接入prometheus的步骤相比于接入skywalking就复杂了许多,还需要SpringBoot暴露Actuator接口,有兴趣的同学可以自行学习actuator。
接入primetheus+grafana的效果参考:

文章来源地址https://www.toymoban.com/news/detail-819723.html
3. 点展比、点击率、展示数、PV、UV。这些数据的计算逻辑比较定制化,只能每日跑python脚本实现。
一开始,研发侧想要通过在Exporter中扩展不同的函数来实现,即把计算点展比、点击率、展示数等统计指标的逻辑写在Exporeter中。但是,架构师负责编写的Exporter是go编写的,算法同学精通python,却并不会编写go和java。后端同学也对使用python重构Exporter并不感冒。
与此同时,定制化编写Exporter也存在下述问题:如果后续要增加新的统计指标,例如推荐商品的去重后展示数,还需要更新Exporter,对于迭代而言也不友好。
最后,组内后端同学设计了以下指标文件格式:
{"metric_name":"xxx","value":1111111,"metric_type":"gauge"}其中,metrci_name表示指标名,value表示指标的值,metric表示指标的类型。在本项目中我们只使用gauge,因为暂时不需要counter, histogram, summary等指标类型。
( 具体的prometheus的四种指标含义参考prometheus的官方文档:第2节:指标类型 - Prometheus 中文文档)
指标文件放在一个规定的路径下,该路径在Exporter的配置文件中指定。
假设2020年11月26日要产出2020年11月25号的点击率指标文件和展示数目指标文件,则两个指标文件的路径为:
/xxxx/xxxx/metric/20201125/click_rate.json
/xxxx/xxxx/metric/20201125/show_num.json其中/xxxx/xxxx/metric为指定的指标产出文件夹。
至于为什么要把指标文件放在同一个日期的文件夹下,而不是使用日期作为后缀,是为了让Exporter读取时候直接到某个文件夹下获取所有的指标文件,而不是采用正则去匹配文件名。
4.2 Exporter具体代码
原始Exporter代码无法提供,这里只能参考链接:Instrumenting a Go application | Prometheus
package main
import (
"net/http"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func recordMetrics() {
go func() {
for {
opsProcessed.Inc()
time.Sleep(2 * time.Second)
}
}()
}
var (
opsProcessed = promauto.NewCounter(prometheus.CounterOpts{
Name: "myapp_processed_ops_total",
Help: "The total number of processed events",
})
)
func main() {
recordMetrics()
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":2112", nil)
}代码解析:
主要是实现了一个counter计数器,同时将数据发送到prometheus数据库,
Prometheus 监控服务 自定义监控-接入指南-文档中心-腾讯云
Summary的编写可以参考:
动手写prometheus的exporter-04-Summary(摘要)_开发运维玄德公的博客-CSDN博客
4.3 部署步骤
详细部署步骤忽略。
大致上部署步骤是:
1. 在单机环境单独新起了一个ES数据库,以支持Skywalking;
2. 部署skywalking的各个模块,配置过程中配置到具体服务的k8s节点和服务;
3. 部署promtheus的各个模块和Exporter;
4. 部署flask服务,将alert-manager发送过来的信息发送到企业微信,打通告警链路;
5. 和客户联调测试;
5. 踩坑经历
5.1 指标没有显示在grafana
原因在于Exporter中更新了逻辑,但是没有重启prometheus-client。
这一块具体逻辑有点忘记了,但是大概好像是没有配置prometheus的热加载机制导致的。
好像是因为更改了配置文件,具体有点忘记了。
5.2 报警配置达到了阈值,但是没有报警
这个问题发生时候,很难排查,因为日志中没有看到有效的信息。
最后是经过架构师排查后发现,由于后期算法加了很多监控指标,导致Exporter的处理流程变长。整个流程需要处理:读取磁盘文件,生成指标;发送到prometheus时序数据库;alertManager扫描prometheus的指标,并发送给用户。但是由于指标文件越来越多,读取磁盘文件生成指标的耗时过久,过了alertManager的扫描窗口,导致报警不生效。(大致逻辑)
总结:如果能够并发读文件,在go编写的Exporter中还是尽量并发操作;
5.3 服务全部部署在一个机器上,导致机器负载较大
部署过程中,我们将所有的服务都部署在唯一一台虚拟机上,剩余四台虚拟机都是被监控的对象,这就导致该台虚拟机承担的功能过多,磁盘占用较大。
后续优化中进行了docker+k8s封装的迭代规划,但最后没有部署,只是每天定期检查一下机器状态(注:部署监控服务的机器也会对机器本身进行监控)。
6.prometheus架构和某大公司组内架构选型对比
这一块由于保密原因不方便写太多,大致写写。
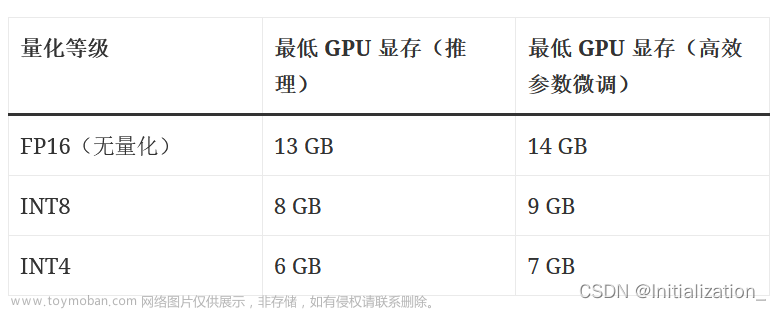
6.1 为什么不选择prometheus时序数据库而选用了场内自研的时序数据库?
主要是历史原因,之前某大厂的选型是influxDB,并且有专门的的告警服务,选择了prometheus,就需要从零开始搭建prometheus生态,成本太高了。
6.2 bosun和prometheus原生态自带的alert-manager区别,为什么选择bosun?
1. bosun支持LogStash-ElasticSearch,对日志的处理更好,prometheus与alert-manager对日志的支持较差;
2. bosun能支持更多的数据库,比如Open-TSDB,ES,prometheus,InfluxDB等,而alert-manager主要还是在prometheus框架下支持prometheus;
3. bosun有一套原生的bosun语法,与prometheus的PromSql是独立的;
4. bosun对调用链路(trace)的支持比prometheus更好,prometheus不太适合用于链路追踪;
5. 选型bosun有着较多的大厂历史原因,用prometheus替换成本太高。
7. 总结
写到此处,发现监控系统的撰写工作量远远超出了自己的估计。
在前东家不长的工作时间中,能深入接触到监控系统的选型与建设,对个人的成长帮助也是很大的。
个人总结了prometheus、skywalking与监控系统的一些个人感悟。
1. 监控系统是一个"高级"的架构,因为监控的需求是随着用户量增长而提出来的,或者说监控本身就是一个需要有了一定的用户量,才有实现意义的架构;
2. 监控系统的架构复杂度远超想象;
3. skywalking或许是一个很天才的个人监控项目,但是随着时间推移,我个人认为越来越多的用户会选择prometheus类型的架构;
4. 相比于skywalking,prometheus不仅提供了更灵活的指标配置,更形成了监控系统的高级抽象,将监控系统划分为时序数据库、报警模块、UI展示模块等部分,并抽象出了metric(指标),PromSql(我理解为指标查询语句),告警规则等概念,从这个方面来说对自研监控系统有着更好的参考意义;
5. 在新团队中,如果想要快速搭建监控系统,skywalking也是不错的选择,提供了很多通用的监控功能;如果想要搭建扩展性更好的监控和报警系统,选用prometheus是不错的选择;如果已经有了现成的监控和报警系统,基于bosun改造也是不不错的选择;
6. 大厂环境中对监控和报警的要求更好,尤其是B(字节)A(阿里)T(腾讯)级别的共is,每日的指标文件会达到PB级别,这时候就有很多定制化的需求,比如:报警规则太多了,不能再用yml文件配置,应该存放到数据库中;对各个服务的报警经常要跨机房,需要设计一些好的路由算法;需要设计统一的报警方案,以提供给厂内同事使用,对基础架构部门的设计研发能力有极高的要求。
8. 参考文档
SkyWalking 极简入门 | Apache SkyWalking
时序数据库入门系列:什么是时序数据库 - 知乎
使用 Go 开发 Prometheus Exporter - 腾讯云开发者社区-腾讯云
5 個適合系統管理員使用的告警視覺化工具 - tw511教學網
Prometheus基于bosun框架进行告警 | xigang's home
Bosun vs Prometheus | What are the differences?
初识时序数据库 | MySQL 技术论坛
时序数据库系列1-综述 - 墨天轮(写的很详细,可以重点参考,里面提到prometheus等几个时序数据库的优劣)
Alertmanager | Prometheus
SkyWalking--使用/教程/实例_51CTO博客_skywalking使用教程
Skywalking全链路追踪使用说明_张维鹏的博客-CSDN博客_全链路追踪skywalking
分布式链路追踪原理详解及SkyWalking、Zipkin介绍 - 腾讯云开发者社区-腾讯云
Dapper,大规模分布式系统的跟踪系统 by bigbully
揭秘Prometheus时序数据库设计 - 知乎
Prometheus时序数据库 - HelloWorld开发者社区
Prometheus时序数据库-报警的计算Prometheus时序数据库-报警的计算 - 腾讯云开发者社区-腾讯云
功能和优势
终于有人把Prometheus入门讲明白了 - DockOne.io
SkyWalking - 实现微服务监控告警_51CTO博客_微服务监控告警
https://doc.cncf.vip/prometheus-handbook/parti-prometheus-ji-chu/quickstart/prometheus-quick-start/use-grafana-create-dashboard
Grafana · ELKstack 中文指南Data sources | Grafana documentation
万字谈监控:解答Zabbix与Prometheus选型疑难_运维_dbaplus社群_InfoQ精选文章
Prometheus监控神器-Alertmanager篇(4) - 腾讯云开发者社区-腾讯云
prometheus中使用python手写webhook完成告警 - 腾讯云开发者社区-腾讯云
Prometheus + Alertmanager 实现企业微信告警_mb5fdb1365b75a0的技术博客_51CTO博客
Instrumenting a Go application | Prometheus
Metrics类型 - prometheus-book
Metric types | Prometheus
Prometheus 编写自己的 exporter - Go语言中文网 - Golang中文社区
动手写prometheus的exporter-04-Summary(摘要)_开发运维玄德公的博客-CSDN博客
Springboot接入SkyWalking分布式链路追踪 - 掘金
SpringBoot应用接入Prometheus的全过程解析 - 知乎
书籍:
Prometheus 云原生监控(朱政科 著)
Apache Skywalking 实战 (吴晟 著)文章来源:https://www.toymoban.com/news/detail-819723.html
到了这里,关于prometheus与skywalking在私有化交付项目中的应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!