文章来源地址https://www.toymoban.com/news/detail-819828.html
文章来源地址https://www.toymoban.com/news/detail-819828.html
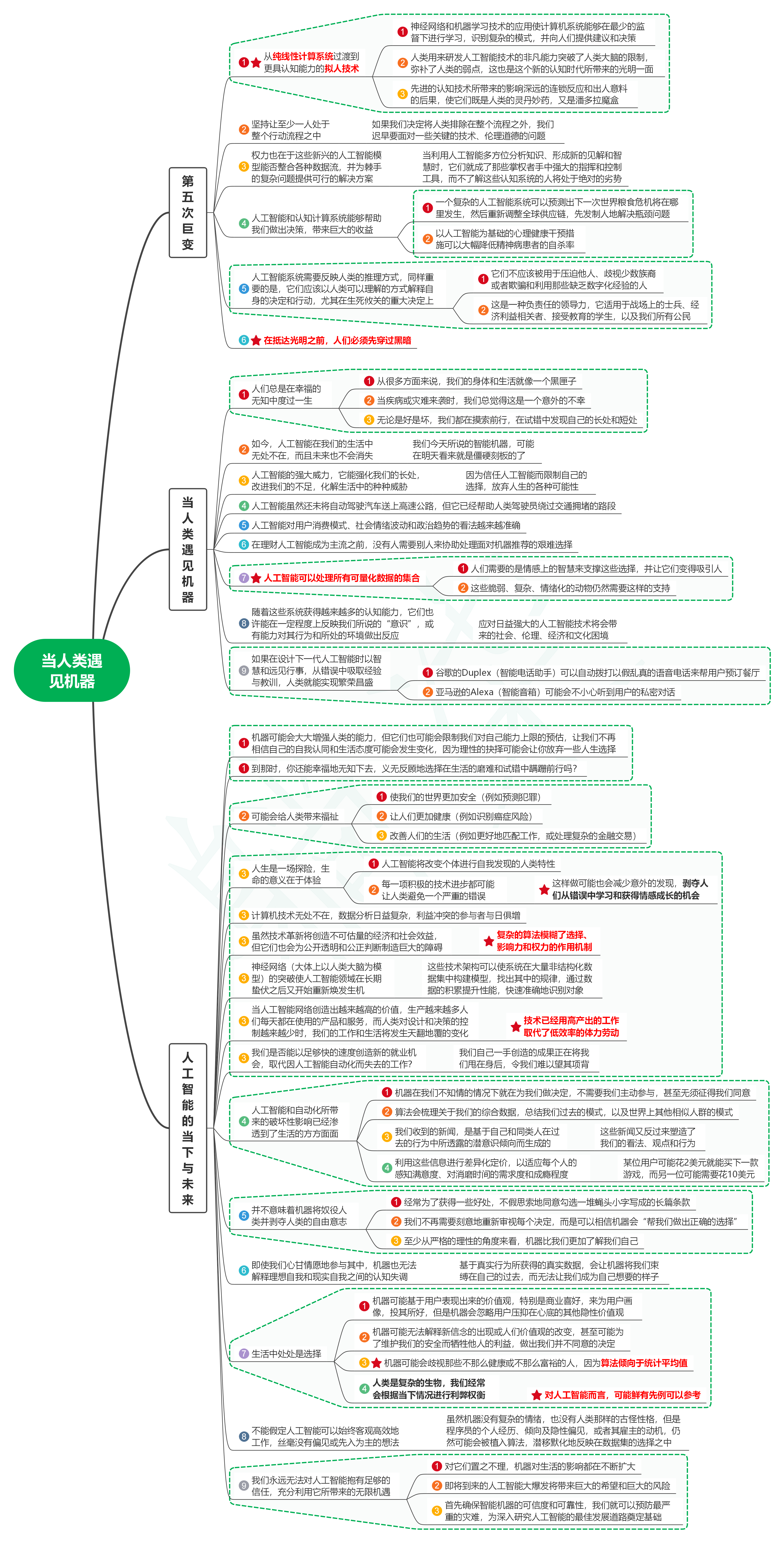
1. 人类与机器学习的关键差距
1.1. 老式人工智能使用的是人类程序员对智能行为构建的显性规则
1.2. DNN这种“从数据中学习”的方法已被逐渐证实比“普通的老式人工智能”策略更成功
1.3. ConvNets的学习过程与人类的学习过程并不是很相似
1.3.1. ConvNets在多个周期中一遍又一遍地在训练样本上处理图像示例并逐步调整自身权重,来学会将每个输入划分为一个固定类别集合中的某个类别
1.3.2. 为了让ConvNets学会执行一项任务,需要大量的人力来完成收集、挑选和标注数据,以及设计ConvNets架构等多方面的工作
1.4. ConvNets使用反向传播算法从训练样本中获取参数(即权重)
1.4.1. 学习是通过所谓的超参数(hyperparameters)集合来实现的
1.4.2. 超参数是一个涵盖性术语,指的是网络的所有方面都需要由人类设定好以允许它开始,甚至“开始学习”这样的指令也需要人类设定好
1.4.3. 超参数包括:网络中的层数、每层中单元感受野的大小、学习时每个权重变化的多少(被称为“学习率”),以及训练过程中的许多其他技术细节
1.4.4. 目前神经网络还无法自学超参数调节
1.5. 孩童不是被动地学习,而是主动提出问题,他们想要了解自己感兴趣的事物的信息,他们会推断抽象概念的含义及其联系,并且最重要的是,他们积极地探索这个世界
1.6. 机器学习领域的学生通常会从他们追随的专家那里,以及自己来之不易的经验中获取它
1.7. 随着深度学习系统在物理世界实际应用的激增,很多公司发现需要大规模的新标记的数据集来训练DNN
1.7.1. 网络学会的是将具有模糊背景的图像分到“包含动物”这一类别,无论该图像是否真的包含一只动物
1.7.2. 机器学到的是它在数据中观察到的东西,而非我们人类可能观察到的东西
1.8. 依赖于收集到的大量已标注的数据来进行训练是深度学习不同于人类学习的另一个特点
1.9. 人类具有一种当前所有的人工智能系统都缺乏的基本能力:运用常识
1.9.1. 我们拥有关于这个世界的体量庞大的背景知识,包括物质层面及社会层面
1.9.2. 背景知识都被注入我们人类的能力中,支持我们稳定地识别给定目标,即便是当今最成功的人工智能视觉系统,也尚且缺乏这种理解能力及在目标识别方面的稳定性
1.9.3. 我们对现实世界中的事物会如何行动或变化有充分的了解,无论它是无生命的还是有生命的
1.9.4. 我们广泛地运用这些常识来决定如何在特定情况下采取行动
1.9.5. 人类通常在生活的方方面面都会本能地运用常识
1.10. 通过监督学习训练的DNN,在计算机视觉、语音识别、文本翻译等领域的许多任务上都表现得非常出色,尽管还远不够完美
1.10.1. 研究人员正在努力使DNN变得更加可靠和透明
1.11. 列出推导过程是DNN这一现代人工智能系统的基石所无法轻易做到的事情
1.11.1. 对于一个一般大小的网络,其运算可能会达到数十亿次
1.11.2. 1个10亿次运算的列表不是一个普通人能接受的解释
1.11.2.1. 即使是训练深度网络的人通常也无法理解其背后隐藏的原理,并为网络做出的决策提供解释
1.11.3. 如果我们不理解DNN如何解答问题,我们就无法真正相信它们,或预测它们会在哪种情况下出错
1.12. 当考虑其他人时,你具有心理学家所说的一种心智理论:理解他人在特定情况下所运用的知识和可能会选择的目标
1.12.1. 对于像DNN这样的人工智能系统,我们并没有类似的心智理论作为支撑,这就使得我们更难信任它们
1.13. 扰动不影响人类对其中对象的识别,却可能导致ConvNets出现严重错误
1.13.1. ConvNets和其他那些在目标识别方面“超越”人类的网络的这种意想不到的脆弱性,表明它们在其训练数据上出现了过拟合,而且学到了一些与我们试图教给它们的不同的东西
1.14. 研究人员发现,人类若要秘密地诱导神经网络犯错,那简直是意想不到地容易
1.14.1. 对于任意一幅由AlexNet正确分类的来自ImageNet的图片,都能够找到特定的变化点来创建一个新的对抗样本图片,使得新图片对人类来说看起来没有变化,却会导致AlexNet以极高的置信度给出一个错误答案
1.14.2. AlexNet对于对抗样本的这种低敏感性并不特殊
1.14.3. 如果漏洞未得到修补,DNN这艘“船”早晚会沉下去
1.14.4. 能够设计出具有特定图案的眼镜框的程序,愚弄了一个人脸识别系统,使其自信地将眼镜框的佩戴者错误地识别为另外一个人
1.14.5. 可放置于交通标志上的不显眼的小贴纸,导致一个基于ConvNets的视觉系统(类似于自动驾驶汽车中使用的视觉系统)对交通标志进行了错误的分类
1.14.6. 将一个停车标志识别为限速标志
1.14.7. 从以99%置信度显示目标图像分类为无癌症,到以99%置信度显示存在癌症
1.14.8. 用于制造欺诈性诊断,以便向保险公司索取额外的诊断测试费用
1.14.9. 一些能够愚弄用于语言处理(包括语音识别和文本分析)的DNN的攻击手段
1.15. 如果在计算机视觉和其他任务上表现得如此成功的深度学习系统,很容易被人类难以察觉的操作所欺骗,我们怎么能说这些网络能够像人类一样学习,或在能力上可以与人类媲美甚至超过人类呢
1.15.1. 目前在计算机视觉应用中使用的ConvNets通常是完全前馈的,而人类视觉系统则具有更多的反馈连接
1.16. 对抗式学习是指:制定策略来防御潜在的人类对手攻击机器学习系统
1.16.1. 以一种人类难以察觉但却会引发网络改变对图像的分类的方式来改变X射线或显微镜图像,是不难做到的
1.16.2. 许多可能的攻击已经被证实具有惊人的鲁棒性:它们对很多网络都能起作用,即便这些网络是在不同的数据集上训练的
1.17. 了解和防御此类潜在的攻击是目前人工智能的一个主要研究领域
1.17.1. 目前为止的研究具有一种“打地鼠”的特点,即一个安全漏洞被检测出来并被成功防御后,总是会发现新的需要防御的漏洞
1.18. 我理解自己在做什么,我掌握了正确的抽象概念并且以正确的推理得到了答案
1.18.1. 人类也并不总是能够解释自己的思维过程
1.18.2. 你无法通过观察别人的大脑内部或者他们的直觉来弄清楚他们是如何做出特定决策的
1.18.3. 人类倾向于相信其他人已经正确地掌握了基本的感知能力,例如目标识别和语言理解能力
2. 大型科技公司
2.1. 免费服务:网络搜索、视频通话、电子邮件、社交网络、智能助理
2.2. 他们真正的客户则是那些获取我们在使用这些免费服务时的注意力和信息的广告商
2.3. 我们会以图像、视频、文字或语音等形式直接为这些公司提供样本
2.3.1. 这些样本可供公司更好地训练其人工智能程序,这些改进的程序能够吸引更多用户来贡献更多数据,进而帮助广告商更有效地定位其广告投放的对象
2.4. 我们提供的训练样本也可被公司用于训练程序来提供企业服务,并进行商业收费,例如计算机视觉和自然语言处理方面的服务
3. 自动驾驶汽车
3.1. 汽车需要复杂的计算机视觉功能,以识别车道、交通信号灯、停车标志等,以及辨别和追踪不同类型的潜在障碍物
3.1.1. 其他汽车、行人、骑自行车的人、动物、交通锥、翻倒的垃圾桶、风滚草,以及其他任何你可能不希望汽车会撞到的对象
3.2. 深度学习将有助于这项任务的实现,至少在某种程度上是如此,但这同样需要大量的训练样本
3.3. 对特斯拉而言,这些汽车就是由客户驾驶的汽车,在客户购买特斯拉汽车时,需要接受该公司的数据共享条款
4. 长尾效应
4.1. 长尾效应常常会让机器犯错
4.1.1. 长尾就是指人工智能系统可能要面临各种可能的意外情况
4.1.1.1. 这一长串可能性低,但却可能发生的情况被称为该分布的“尾巴”,尾巴上的情况有时被称为“边缘情况”
4.1.2. 不太常见的情况是自动驾驶汽车遇到了被水淹没的道路或被雪遮挡住的车道标志
4.1.2.1. 在高速公路的中央遇到一个雪人,则是更加不常见的情况了
4.1.3. 面对如此多数不清的可能场景以及巨大的车流量,总会有某辆自动驾驶汽车会在某个时间、某个地点遭遇其中的一种情况
4.2. 现实世界中的大部分事件通常是可预测的,但仍有一长串低概率的意外事件发生
4.2.1. 尾部的情况并不经常出现在训练数据中,所以当遇到这些意外情况时,系统就会更容易出错
4.3. 许多公司也正在探索利用类似于视频游戏的模拟驾驶程序来强化有监督的训练
4.4. 监督学习方法并不是一条通往通用人工智能的可行途径
4.5. 对大量数据的需要是目前限制深度学习发展的主要因素
4.5.1. 我们不可能对世界上的所有事物都进行标注,并一丝不苟地把每一个细节都解释给计算机听
4.6. 针对他们能想到的所有不太可能的场景编写了相应的应对策略
4.6.1. 他们显然无法穷尽系统可能遇到的所有场景
5. 无监督学习
5.1. unsupervised learning
5.2. 让人工智能系统在少量标注数据上进行监督学习,并通过“无监督学习”(unsupervised learning)来学习其他所有的内容
5.3. 无监督学习是指在没有标记数据的情况下学习样本所属类别的一系列方法
5.4. 基于相似度来对样本进行分类的方法,或者通过与已知类别进行对比来学习新类别的方法
5.5. 对抽象事物的感知以及类比是人类擅长的,但到目前为止,还没有特别成功的人工智能算法来实现这种无监督学习
5.6. 无监督学习是人工智能的暗物质
5.6.1. 杨立昆
5.6.2. 对于通用人工智能,几乎所有学习都应该在无监督方式下进行,然而,还没人提出过成功进行无监督学习所需的各种算法
6. 有偏见的人工智能
6.1. ConvNets的不可靠性有时会导致尴尬的错误,甚至有害的错误
6.2. 用“大猩猩”标注了一张两名非裔美国人的自拍照
6.2.1. 在由深度学习驱动的视觉系统中,这种由种族或性别歧视导致的错误虽然不易察觉,却经常被观测到
6.3. 商业人脸识别系统识别男性白人的脸要比识别女性或非白人的脸更加准确
6.3.1. 网上出现的人脸照片更偏向于那些知名的或有权势的人,他们主要是白人和男性
6.4. 有偏见的数据集上训练的人工智能系统,如果在真实世界的应用中传播开来,就能够放大这些偏见并造成真正的危害
6.5. 在种族群体上识别准确率的细微差异,也会对公民权利和获得关键服务的机会产生破坏性影响
6.6. 会偶尔错误地将一个站在厨房里的男士归类为“女士”,这是因为在数据集中厨房多是一种包含女性样本的场景
6.6.1. 这种细微的偏见在事后会很明显,但却很难被提前发现
6.7. 用于训练人工智能的数据集是否应该准确地反映我们本来就存有偏见的社会?
文章来源:https://www.toymoban.com/news/detail-819828.html
到了这里,关于读AI3.0笔记05_人类与机器学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[足式机器人]Part2 Dr. CAN学习笔记- Kalman Filter卡尔曼滤波器Ch05](https://imgs.yssmx.com/Uploads/2024/01/805885-1.png)

![[足式机器人]Part2 Dr. CAN学习笔记- Kalman Filter卡尔曼滤波器Ch05-5+6](https://imgs.yssmx.com/Uploads/2024/01/809496-1.png)
![[足式机器人]Part2 Dr. CAN学习笔记- Kalman Filter卡尔曼滤波器Ch05-3+4](https://imgs.yssmx.com/Uploads/2024/01/808512-1.png)