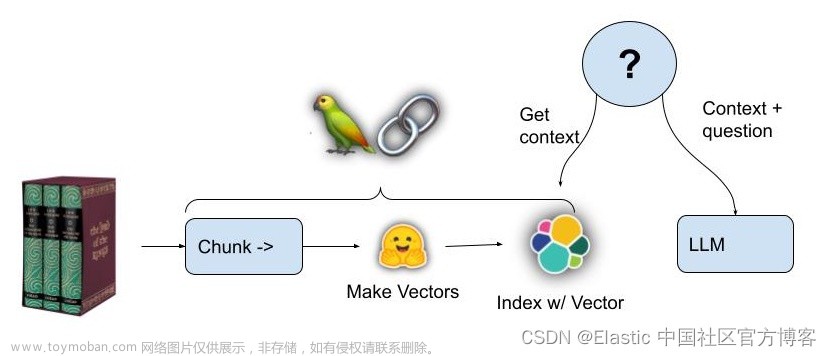
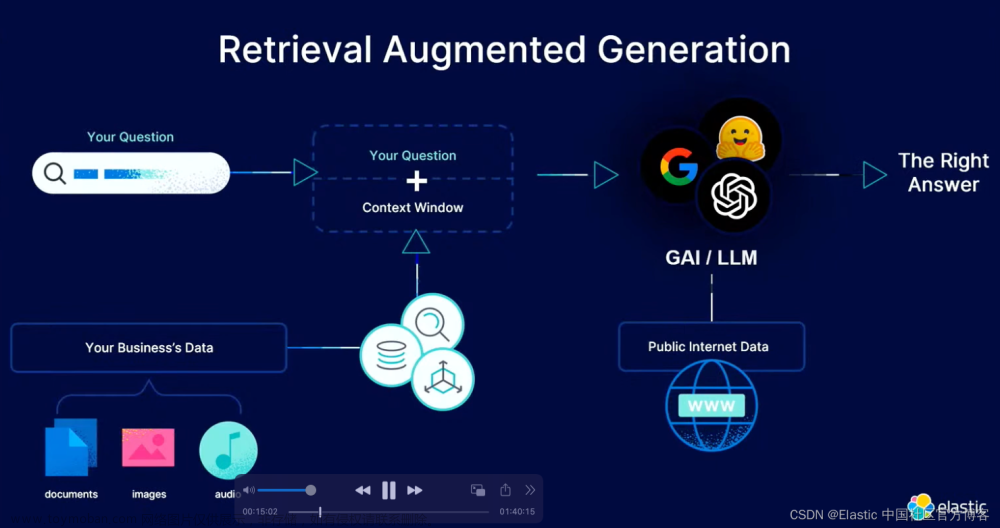
本教程演示如何使用 Gemini API创建 embeddings 并将其存储在 Elasticsearch 中。 我们将学习如何将 Gemini 连接到 Elasticsearch 中存储的私有数据,并使用 Langchian 构建问答功能。

准备
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana 的话,请参阅如下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请参照 Elastic Stack 8.x 的文章来进行安装。
Gemini 开发者 key
你可以参考文章 来申请一个免费的 key 供下面的开发。你也可以直接去地址进行申请。
设置环境变量
我们在 termnial 中打入如下的命令来设置环境变量:
export ES_USER=elastic
export ES_PASSWORD=-M3aD_m3MHCZNYyJi_V2
export GOOGLE_API_KEY=YourGoogleAPIkey拷贝 Elasticsearch 证书
我们把 Elasticsearch 的证书拷贝到当前的目录下:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .安装 Python 依赖包
pip3 install -q -U google-generativeai elasticsearch langchain langchain_google_genai应用设计
我们在当前的工作目录下打入命令:
jupyter notebook导入包
import google.generativeai as genai
import google.ai.generativelanguage as glm
from elasticsearch import Elasticsearch, helpers
from langchain.vectorstores import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.runnable import RunnableLambda
from langchain.schema import HumanMessage
from urllib.request import urlopen
from dotenv import load_dotenv
import json, os读取环境变量
load_dotenv()
GOOGLE_API_KEY = os.getenv("GOOGLE_API_KEY")
ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
elastic_index_name='gemini-qa'写入文档
让我们下载示例数据集并反序列化文档
我们首先在地址下载示例数据集:
wget https://raw.githubusercontent.com/liu-xiao-guo/semantic_search_es/main/datasets/data.json其中的一个文档的内容如下:

$ pwd
/Users/liuxg/python/elser
$ ls datasets/
data.json# Load data into a JSON object
with open('./datasets/data.json') as f:
workplace_docs = json.load(f)
print(f"Successfully loaded {len(workplace_docs)} documents")
将文档拆分为段落
metadata = []
content = []
for doc in workplace_docs:
content.append(doc["content"])
metadata.append({
"name": doc["name"],
"summary": doc["summary"],
"rolePermissions":doc["rolePermissions"]
})
text_splitter = CharacterTextSplitter(chunk_size=50, chunk_overlap=0)
docs = text_splitter.create_documents(content, metadatas=metadata)
使用 Gemini Embeddings 将文档索引到 Elasticsearch
url = f"https://{ES_USER}:{ES_PASSWORD}@192.168.0.3:9200"
connection = Elasticsearch(
hosts=[url],
ca_certs = "./http_ca.crt",
verify_certs = True
)
print(connection.info())
embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001", task_type="retrieval_document"
)
es = ElasticsearchStore.from_documents(
docs,
embedding = embeddings,
es_url = url,
es_connection = connection,
index_name = elastic_index_name,
es_user = ES_USER,
es_password = ES_PASSWORD)
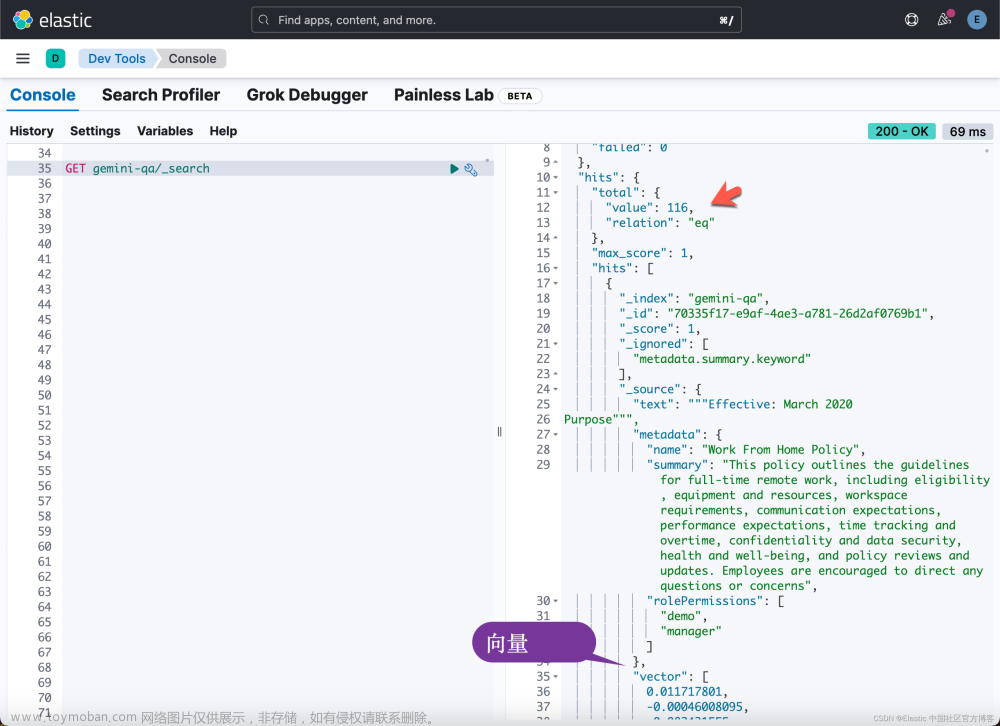
运行完上面的代码后,我们可以去 Kibana 中进行查看:
创建 retriever
更多搜索的方法可以参考 “Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (四)”。
embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001", task_type="retrieval_query"
)
retriever = es.as_retriever(search_kwargs={"k": 3})如果你不用去写入文档(没有上一步的 es),那么你可以使用如下的方法创建 es:
es = ElasticsearchStore(
es_connection=connection,
embedding=embedding,
index_name=elastic_index_name
)格式化文档
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)使用 Prompt Template+gemini-pro 模型创建一条链
template = """Answer the question based only on the following context:\n
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| ChatGoogleGenerativeAI(model="gemini-pro", temperature=0.7)
| StrOutputParser()
)
chain.invoke("what is our sales goals?")
最终的的 notebook 可以在地址找到:https://github.com/liu-xiao-guo/semantic_search_es/blob/main/QA_using_Gemini_Langchain_Elasticsearch.ipynb文章来源:https://www.toymoban.com/news/detail-819909.html
跟多阅读: 快速入门:使用 Gemini Embeddings 和 Elasticsearch 进行向量搜索文章来源地址https://www.toymoban.com/news/detail-819909.html
到了这里,关于Elasticsearch:使用 Gemini、Langchain 和 Elasticsearch 进行问答的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!