在Java环境中处理海量字符串去重的问题时,布隆过滤器(BloomFilter)是一种非常高效的数据结构,尽管它有一定的误报率。布隆过滤器适用于那些可以接受一定误报率,并且希望节省空间和时间成本的场景。

布隆过滤器应用
使用Google Guava库来实现基于布隆过滤器的海量字符串去重是一个很好的选择。布隆过滤器是一种空间效率极高的概率型数据结构,它利用位数组表示集合,并使用哈希函数将元素映射到位数组的某些位置。布隆过滤器可以高效地检查一个元素是否可能属于某个集合,但有一定的误报率。
首先,确保你的项目中包含了Guava库。如果你使用Maven,可以在pom.xml文件中添加以下依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version> <!-- 使用你需要的版本 -->
</dependency>
然后,你可以使用下面代码创建布隆过滤器进行字符串去重:
import com.google.common.hash.Funnels;
import com.google.common.primitives.Ints;
import com.google.common.util.concurrent.BloomFilter;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class BloomFilterDeduplication {
public static void main(String[] args) {
// 预计的字符串数量(根据实际情况进行调整)
long expectedInsertions = 1000000L;
// 可接受的误报率(根据实际情况进行调整)
double fpp = 0.01; // 1%的误报率
// 创建一个布隆过滤器实例
BloomFilter<String> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(StandardCharsets.UTF_8),
expectedInsertions,
fpp
);
// 模拟海量字符串
List<String> strings = new ArrayList<>();
// 假设这里有很多重复的字符串...
strings.add("hello");
strings.add("world");
strings.add("hello"); // 重复字符串
strings.add("guava");
strings.add("bloom");
strings.add("filter");
strings.add("world"); // 重复字符串
// 去重过程
List<String> deduplicatedStrings = new ArrayList<>();
for (String str : strings) {
if (!bloomFilter.mightContain(str)) {
// 如果布隆过滤器中可能不包含该字符串,则将其添加到过滤器和结果列表中
bloomFilter.put(str);
deduplicatedStrings.add(str);
}
}
// 输出结果
System.out.println("Deduplicated strings:");
for (String uniqueStr : deduplicatedStrings) {
System.out.println(uniqueStr);
}
}
}
在这个示例中,我们首先创建了一个布隆过滤器实例,指定了预计的字符串数量和可接受的误报率。然后,我们模拟了一个包含重复字符串的列表,并使用布隆过滤器进行去重。对于每个字符串,如果布隆过滤器可能不包含它(mightContain返回false),我们就将其添加到过滤器和去重后的字符串列表中。
布隆过滤器原理详解
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器可以告诉我们 “某样东西一定不存在或者可能存在”,也就是说布隆过滤器说这个数不存在则一定不存,布隆过滤器说这个数存在可能不存在(误判,后续会讲)。
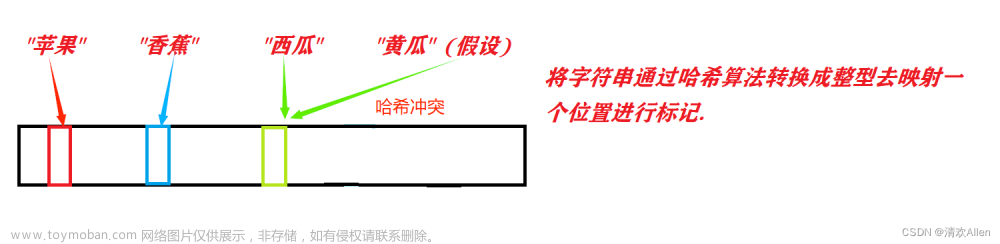
布隆过滤器是一种空间效率极高的概率型数据结构,它利用位数组表示集合,并使用哈希函数将元素映射到位数组的某些位置。布隆过滤器并不直接存储数据本身,而是通过位数组中的特定位来表示数据是否存在。
布隆过滤器的数据结构主要由两部分组成:
-
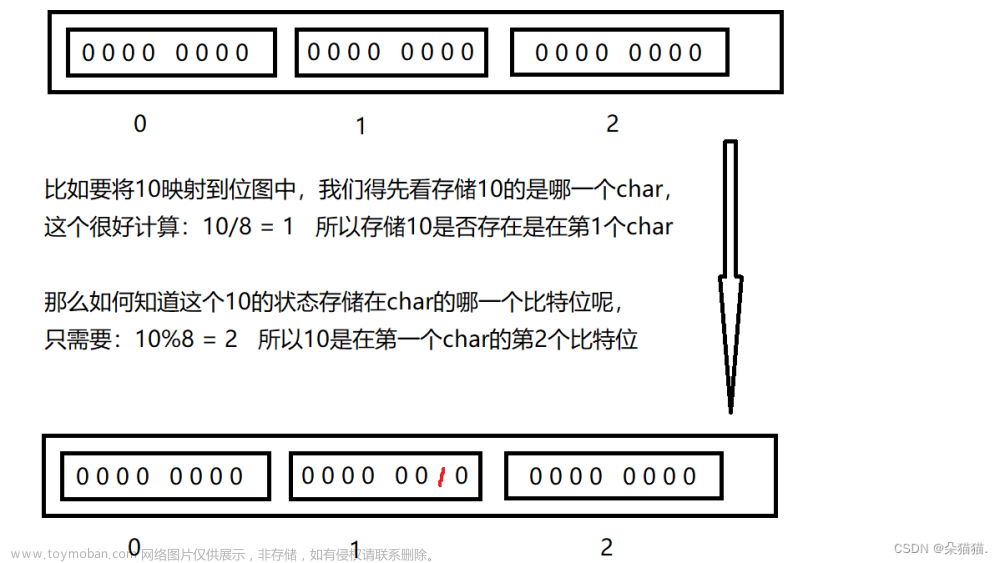
位数组(Bit Array):布隆过滤器使用一个长度固定的位数组来存储数据。每个位置只占用一个比特(0或1),初始时所有位都设置为0。位数组的长度和哈希函数的数量决定了过滤器的误报率和容量。
-
哈希函数集合:布隆过滤器使用多个哈希函数,每个函数都会将输入数据映射到位数组的一个不同位置。哈希函数的选择对过滤器的性能有很大影响,理想的哈希函数应该具有良好的散列性,使得不同的输入尽可能均匀地映射到位数组的不同位置。
如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。
布隆过滤器的操作主要包括:
- 添加元素:当向布隆过滤器中添加一个新元素时,会使用所有的哈希函数对该元素进行哈希,并将位数组中对应位置设置为1。注意,同一个位可能会被多个元素哈希到,因此可能会被多次设置为1,但实际上只需要第一次设置。
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1
-
查询元素:当需要查询一个元素是否可能存在于布隆过滤器中时,同样会使用所有的哈希函数对该元素进行哈希,并检查位数组中对应位置是否都为1。如果有任何一个位置为0,则可以确定该元素一定不在过滤器中。如果所有位置都为1,则元素可能存在于过滤器中,但存在一定的误报率。
-
删除元素:布隆过滤器不支持直接删除元素。这是因为删除一个元素需要将位数组中对应位置重置为0,但这样可能会影响到其他也被哈希到该位置的元素。因此,布隆过滤器是一种“添加容易,删除困难”的数据结构。文章来源:https://www.toymoban.com/news/detail-819974.html
布隆过滤器的好处
- 空间效率:布隆过滤器不需要存储实际数据,只需要一个位数组和一些哈希函数,因此空间效率非常高。
- 查询速度:布隆过滤器的查询操作只需要进行哈希和位操作,因此速度非常快。
- 添加速度:添加元素到布隆过滤器中同样只需要进行哈希和位操作,速度也很快。
- 安全性:布隆过滤器不存储实际数据,因此在某些对安全性要求较高的场景中很有用。
需要注意的是,布隆过滤器有一定的误报率。这是因为不同的元素可能会哈希到相同的位置,导致位数组中对应位置被错误地设置为1。此外,布隆过滤器不支持删除操作,因为删除一个元素可能会影响到其他元素。
布隆过滤器的缺点
- 误报率:布隆过滤器有一定的误报率,即可能会错误地认为某个不在集合中的元素在集合中。误报率与二进制向量的长度和哈希函数的数量有关,可以通过调整这两个参数来控制误报率。
- 无法删除元素:由于布隆过滤器的特性,一旦一个元素被添加到过滤器中,就无法从过滤器中删除。这是因为删除元素可能会导致其他元素被误删。
总的来说,布隆过滤器是一种非常适合处理海量数据去重问题的数据结构,尤其是在空间和时间成本都非常敏感的场景下。虽然它有一定的误报率,但在很多应用中,这个缺点是可以接受的。在使用布隆过滤器时,需要根据具体的应用场景和需求来调整参数,以达到最佳的效果。文章来源地址https://www.toymoban.com/news/detail-819974.html
到了这里,关于基于Guava布隆过滤器的海量字符串高效去重实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!