自然语言处理附加作业--概率最大中文分词
一、理论描述
中文分词是指将中文句子或文本按照语义和语法规则进行切分成词语的过程。在中文语言中,词语之间没有明显的空格或标点符号来分隔,因此需要通过分词工具或算法来实现对中文文本的分词处理。分词的准确性和效率对于中文自然语言处理和信息检索等领域具有重要意义。常用的中文分词工具包括jieba、HanLP等。
二、算法描述
本文实现概率最大中文分词算法,具体算法描述如下:
思路是使用动态规划的方法,通过计算每个子串的最大概率来得到整个句子的最大概率。具体的实现步骤如下:
- 首先,根据给定的词频文件,获取词频字典word_prob,其中键为词,概率值为取自然对数后的结果。
- 初始化max_len为最大词长度,max_sentence和prev_word数组长度为句子长度,每项均为0
- 遍历句子中的每个字符,以当前字符为起点,向后最多遍历max_len个字符,获取子串,并在词频字典中查找是否存在该子串如果当前位置不是句子的起始位置,则将前面子串的最大概率加上当前子串的概率
- 如果子串在词频字典中存在,则计算其累计概率。累计概率的计算方式为将当前子串的概率加上前面子串的最大概率,即P'(word) = P(word) * P'(prev_word)。如果计算出来的累计概率小于当前位置的最大概率,则更新最大概率和起始下标
- 循环结束后,根据max_sentence数组记录的起始下标,从后往前依次获取每个词,并将其添加到结果列表中。最后将结果列表反转,得到最终的分词结果
该算法核心思想是通过动态规划来计算每个子串的最大概率,并根据最大概率和起始下标来获取分词结果
三、详例描述
以句子“结合成分子时”为例,详细描述算法如下:
- 根据词频文件,获取词频字典word_prob,其中键为词,值为词频
- 初始化,max_sentence用于存储每个子串的最大概率,prev_word用于记录每个子串的起始下标
- 循环遍历句子中的每个位置和每个子串:
- 当i=0,j=0时,当前位置为句子的第一个字符word = ‘对’,查找词典中‘对’的概率temp_prob为0.003388, max_sentence[0]=0.003388说明sentence[0, 0]当前的最大概率,prev_word[0]=0表示sentence[0]的词起始下标为0
- 当i=0,j=1时,word = ‘对外’,查找词典中‘对’的概率为7.5e-05;
max_sentence[1] = 7.5e-05,表示sentence[0, 1]当前的最大概率;prev_word[1] = 0,表示“对外”的起始下标为0,说明“对外”此时为累计概率最大的词
-
- 当i=0,j=2、3时,在词典中不存在,直接跳出循环
- 当i=1,j=0时,word = ‘外’,概率为0.00025,需要计算其累计概率P’(外) = P(外) * P’(对) = 0.00025 * max_sentence [0],判断其是否大于max_sentence[1],即是否大于P’(对外),若是,则替换max_sentence[1],并将prev_word[1]改为1。当前是小于,故不会替换,以此类推
- 循环结束后,max_sentence中的最后一个元素即为整个句子的最大概率。
- 根据prev_word中记录的起始下标,从后往前依次获取每个词,并将其添加到结果列表中,将结果列表反转,得到最终的分词结果为`['结合', '成', '分子', '时',‘。’]`。
四、软件演示
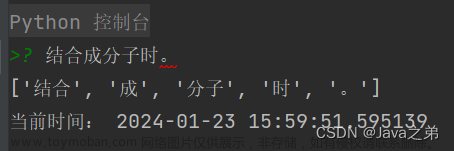
输入‘结合成分子时。’
输出‘['结合', '成', '分子', '时', '。']’
 文章来源:https://www.toymoban.com/news/detail-819981.html
文章来源:https://www.toymoban.com/news/detail-819981.html
五、问题和总结
该算法是一种基于概率的最大中文分词算法,通过计算词的累计概率来寻找最优的切分结果。尽管该算法简单易实现,但存在一些问题,如未登录词处理、位置信息考虑、语言模型应用和歧义问题等。因此,在实际应用中,可能需要结合其他技术或算法来改进分词的准确性和效果文章来源地址https://www.toymoban.com/news/detail-819981.html
到了这里,关于自然语言处理--概率最大中文分词的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[自然语言处理] 自然语言处理库spaCy使用指北](https://imgs.yssmx.com/Uploads/2024/02/611542-1.png)