1、写作动机:
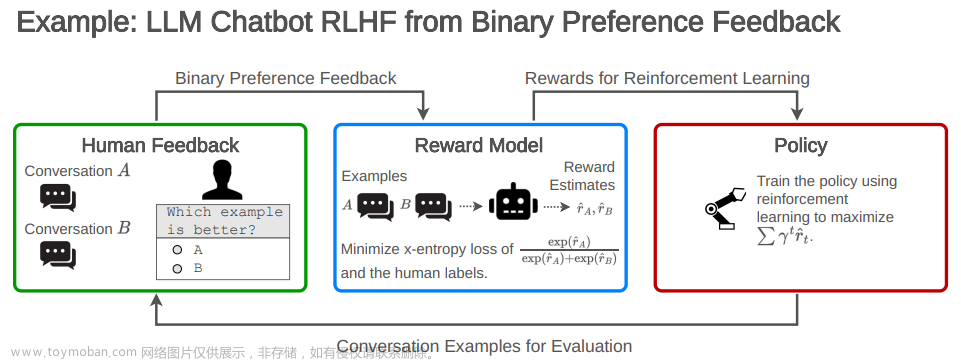
强化学习表现出相当复杂度、对超参数的敏感性、在训练过程中的不稳定性,并需要在奖励模型和价值网络中进行额外的训练,导致了较大的计算成本。为了解决RL方法带来的上述挑战,提出了几种计算上轻量级的替代方案,在这些替代方案中,两个突出的范例包括对比学习和Hindsight指令重新标记(HIR),然而,无奖励微调容易受到训练集中包含的偏好注释响应对的嘈杂数据或不正确标签的影响。
几种方法的比较如下图:

2、主要贡献:
本研究从新兴的表示工程(RepE)领域汲取灵感,旨在识别嵌入在LLM活动模式中的高级人类偏好的相关表示,并通过转换其表示实现对模型行为的精确控制。这种新颖的方法,称为从人类反馈中的表示对齐(RAHF),被证明是有效的、计算高效的,并且易于实施。
3、方法:
通过一组偏好标注的响应对对LLMs进行人类偏好的指导。其次,我们收集LLMs在接收到偏好或不偏好的刺激时的活动模式。使用了两种新方法,用于对LLMs进行人类偏好的指导和提取它们的活动模式:一种涉及单个LLM(训练其区分响应相对质量的能力),另一种采用双LLMs("好人"和"坏人")。最后,通过训练一个低秩适配器来适应活动模式的差异,构建最终模型。
3.1单模型指导:
单LLM方法侧重于通过对比指令微调单个大型语言模型(SCIT)。其主要目标是有效地训练模型区分首选和不首选的响应,从而优化其与人类偏好的一致性。在这种方法中,培训数据集被精心策划,包括首选和不首选指令的配对,以及相关的查询和相应。受HIR的启发,对于与正面偏好相关的指令,目标是提高生成首选响应的概率,同时降低生成不首选响应的概率。相反,对于与负面偏好相关的指令,目标是提高生成不首选响应的概率,并降低生成首选响应的概率。形式上,让D表示训练数据集,其中qi表示查询,ri表示响应,pi表示指令(正面或负面)。LLM的微调涉及最大化以下目标:


3.2双模型中的偏好指令:
训练两个具有不同倾向的LLMs:一个模型倾向于生成首选响应,而另一个倾向于生成不首选响应。形式上,考虑数据集D,其中包含输入查询q和首选响应对的配对:首选响应rh和不首选响应rl。现在,我们将D分为首选数据集Dh={(q,rh)}i和不首选数据集Dl={(q,rl)}i。利用这些数据,采用监督学习方法(最大似然)对LLMs进行微调,从而获得表示首选的两个模型,分别表示为πh和πl。这两个LLMs的微调旨在最大化以下目标:

3.3收集活动模式和构建最终模型:
在提取活动模式的过程中,利用刺激对<p+,q,r>和<p−,q,r>从模型的中间层中引出表示。对于通过对比指令微调的单个大型语言模型(SCIT),这些对分别输入到同一模型中,以捕捉首选和不首选响应的不同激活模式。对于双LLMs方法,输入被馈送到相应的“好”模型和“坏”模型中,使其能够独立地提取每个模型的激活模式。对于这两种方法计算刺激对激活模式的差异,产生一个指示首选活动模式方向的差异向量。具体而言,对于首选和不首选的指令,计算响应中相应位置的每个token的隐藏状态的差异。随后,通过合并差异向量来扰动模型的原始表示。最后利用收集到的激活模式来训练一个目标模型,期望它与人类偏好一致。

其中,α 是一个超参数,控制差异向量vl在模型整合过程中的干预程度。vl 是提取的差异向量。
4、实验:
数据集:2H数据集。
模型:用alpaca数据集微调llama-7b模型,成为alpaca模型,在实验中,所有模型都是使用Alpaca初始化的。

 文章来源:https://www.toymoban.com/news/detail-819990.html
文章来源:https://www.toymoban.com/news/detail-819990.html
 文章来源地址https://www.toymoban.com/news/detail-819990.html
文章来源地址https://www.toymoban.com/news/detail-819990.html
到了这里,关于对齐大型语言模型与人类偏好:通过表示工程实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!