1 案例1:使用正则表达式
1.1 问题
本案例要求熟悉正则表达式的编写,完成以下任务:
- 利用grep或egrep工具练习正则表达式的基本用法
1.2 方案
表-1 基本正则列表
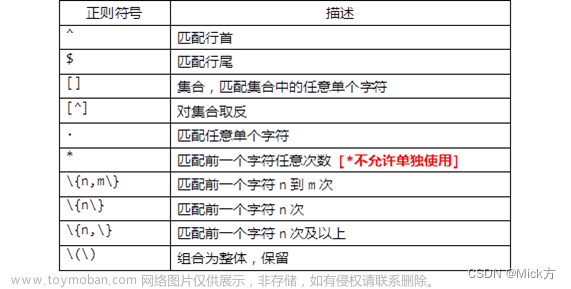
表-2 扩展正则列表

1.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:正则表达式匹配练习
1)基本正则表达式
head -5 /etc/passwd > user #准备素材测试 ^ $ [] [^]
grep ^root user #找以root开头的行
grep bash$ user #找以bash结尾的行
grep ^$ user #找空行
grep -v ^$ user #显示除了空行的内容
grep "[root]" user #找r、o、t任意一个字符
grep "[rot]" user #效果同上
grep "[^rot]" user #显示r或o或t以外的内容
grep "[0123456789]" user #找所有数字
grep "[0-9]" user #效果同上
grep "[^0-9]" user #显示数字以外内容
grep "[a-z]" user #找所有小写字母
grep "[A-Z]" user #找所有大写字母
grep "[a-Z]" user #找所有字母
grep "[^0-9a-Z]" user #找所有符号测试 . *
grep "." user #找任意单个字符,文档中每个字符都可以理解为任意字符
grep "r..t" user #找rt之间有2个任意字符的行
grep "r.t" user #找rt之间有1个任意字符的行,没有匹配内容,就无输出
grep "*" user #错误用法,*号是匹配前一个字符任意次,不能单独使用
grep "ro*t" user #找rt,中间的o有没有都行,有几次都行
grep ".*" user #找任意,包括空行 .与*的组合在正则中相当于通配符的效果测试 \{n\} \{n,\} \{n,m\} \(\)
grep "ro\{1,2\}t" user #找rt,中间的o可以有1~2个
grep "ro\{2,6\}t" user #找rt,中间的o可以有2~6个
grep "ro\{1,\}t" user #找rt,中间的o可以有1个以及1个以上
grep "ro\{3\}t" user #找rt,中间的o必须只有有3个
grep "\(0:\)\{2\}" user #找连续的2个0: 小括号的作用是将字符组合为一个整体扩展正则表达式
以上命令均可以加-E选项并且去掉所有\,改成扩展正则的用法
比如grep "ro\{1,\}t" user可以改成 grep -E "ro{1,}t" user
或者egrep "ro{1,}t" user
grep "ro\{1,\}t" user #使用基本正则找o出现1次以及1次以上
egrep "ro{1,}t" user #使用扩展正则,效果同上,比较精简
egrep "ro+t" user #使用扩展正则,效果同上,最精简
grep "roo\{0,1\}t" user #使用基本正则找第二个o出现0~1次
egrep "roo{0,1}t" user #使用扩展正则,效果同上,比较精简
egrep "roo?t" user #使用扩展正则,效果同上,最精简
egrep "(0:){2}" user #找连续的2个0: 小括号的作用是将字符组合为一个整体
egrep "root|bin" user #找有root或者bin的行
egrep "the\b" abc.txt #找单词the,右边不允许出现数字、字母、下划线
egrep "\bthe\b" abc.txt #the两边都不允许出现数字、字母、下划线
egrep "\<the\>" abc.txt #效果同上思考:如何匹配大范围的数字?比如250-255
2 案例2:sed基本用法
2.1 问题
本案例要求熟悉sed命令的p、d、s等常见操作
2.2 方案
sed文本处理工具的用法:
用法1:前置命令 | sed [选项] '条件指令'
用法2:sed [选项] '条件指令' 文件.. ..2.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:认识sed工具
sed命令的常用选项如下:
-n(屏蔽默认输出,默认sed会输出读取文档的全部内容)
-r(支持扩展正则)
-i(修改源文件)
- 条件可以是行号或者/正则/,没有条件时默认为所有行都执行指令
- 指令可以是p输出、d删除、s替换
步骤二:使用sed
1)行号案例
head -5 /etc/passwd > user #准备素材
sed -n 'p' user #输出所有行
sed -n '1p' user #输出第1行
sed -n '2p' user #输出第2行
sed -n '3p' user #输出第3行
sed -n '2,4p' user #输出2~4行
sed -n '2p;4p' user #输出第2行与第4行
sed -n '3,+1p' user #输出第3行以及后面1行
sed -n '1~2p' /etc/passwd #输出奇数行2)使用正则当条件
sed -n '/^root/p' user #输出以root开头的行
sed -n '/root/p' user #输出包含root的行
sed -nr '/^root|^bin/p' user #输出以root开头的行或bin开头的行,|是扩展正则,需要r选项3)特殊用法
sed -n '1!p' user #输出除了第1行的内容,!是取反
sed -n '$p' user #输出最后一行
sed -n '=' user #输出行号,如果是$=就是最后一行的行号以上操作,如果去掉-n,在将p指令改成d指令就是删除
步骤三:sed工具的p、d、s操作指令案例集合
1)p指令案例集锦(自己提前生成一个a.txt文件)
[root@svr5 ~]# sed -n 'p' a.txt #输出所有行,等同于cat a.txt
[root@svr5 ~]# sed -n '4p' a.txt #输出第4行
[root@svr5 ~]# sed -n '4,7p' a.txt #输出第4~7行
[root@svr5 ~]# sed -n '/^bin/p' a.txt #输出以bin开头的行
[root@svr5 ~]# sed -n '$=' a.txt #输出文件的行数2)d指令案例集锦(自己提前生成一个a.txt文件)
[root@svr5 ~]# sed '3,5d' a.txt #删除第3~5行
[root@svr5 ~]# sed '/xml/d' a.txt #删除所有包含xml的行
[root@svr5 ~]# sed '/xml/!d' a.txt #删除不包含xml的行,!符号表示取反
[root@svr5 ~]# sed '/^install/d' a.txt #删除以install开头的行
[root@svr5 ~]# sed '$d' a.txt #删除文件的最后一行
[root@svr5 ~]# sed '/^$/d' a.txt #删除所有空行3)sed命令的s替换基本功能(s/旧内容/新内容/选项):
[root@svr5 ~]# vim shu.txt #新建素材
2017 2011 2018
2017 2017 2024
2017 2017 2017
sed 's/2017/6666/' shu.txt #把所有行的第1个2017替换成6666
sed 's/2017/6666/2' shu.txt #把所有行的第2个2017替换成6666
sed '1s/2017/6666/' shu.txt #把第1行的第1个2017替换成6666
sed '3s/2017/6666/3' shu.txt #把第3行的第3个2017替换成6666
sed 's/2017/6666/g' shu.txt #所有行的所有个2017都替换
sed '/2024/s/2017/6666/g' shu.txt #找含有2024的行,将里面的所有2017替换成6666思考:如果想把 /bin/bash 替换成 /sbin/sh 怎么操作?
sed -i '1s/bin/sbin/' user #传统方法可以一个一个换,先换一个
sed -i '1s/bash/sh/' user #再换一个如果想一步替换:
sed 's//bin/bash//sbin/sh/' user #直接替换,报错
sed 's/\/bin\/bash/\/sbin\/sh/' user #使用转义符号可以成功,但不方便
sed 's!/bin/bash!/sbin/sh!' user #最佳方案,更改s的替换符
sed 's(/bin/bash(/sbin/sh(' user #替换符号可以用键盘上大部分字符3 案例3:编写脚本,搭建httpd服务,用82号端口开启服务
编写脚本,按下列方法实现
#!/bin/bash
setenforce 0 #关闭selinux
yum -y install httpd &> /dev/null #安装网站
echo "sed-test~~~" > /var/www/html/index.html #定义默认页
sed -i '/^Listen 80/s/0/2/' /etc/httpd/conf/httpd.conf #修改配置文件,将监听端口修改为82
systemctl restart httpd #开服务
systemctl enable httpd #设置开机自启然后运行脚本
curl 192.168.2.5:82 #脚本运行之后,测试82端口看到页面即可
sed-test~~~
ss -ntulp | grep httpd #检查服务的端口是否为824 sed综合脚本应用
4.1 问题
本案例要求编写脚本,实现以下需求,效果如图-1:
- 找到使用bash作登录Shell的本地账户名
- 列出这些账户的shadow密码记录
- 按每行“账户名 --> 密码记录”保存到文件中

4.2 方案
基本思路如下:
- 先用sed工具取出登录Shell为/bin/bash的账户
- 再结合循环取得的账户记录,逐行进行处理
- 针对每一行账户记录,采用掐头去尾的方式获得名称、密码
- 按照指定格式追加到文件
4.3 步骤
实现此案例需要按照如下步骤进行。
#!/bin/bash
u=$(sed -n '/bash$/s/:.*//p' /etc/passwd) #找到passwd文档中以bash结尾的行,然后将行中冒号以及冒号后面内容都删除,此处的p代表仅仅显示s替换成功的行,最后赋值给u
for i in $u #将那些用bash的账户名交给for循环
do
pass=$(grep $i /etc/shadow) #用每个账户名去shadow中找对应信息
pass=${pass#*:} #掐头,从左往右删除到第1个冒号
pass=${pass%%:*} #去尾,从右往左删除到最后一个冒号,经过上述步骤,pass就是最终要的密码了
echo "$i --> $pass" #按格式喊出,如果要存到文件中就用追加重定向
done5 准备新环境
后续课程需要4台Rocky-8.6 版本的虚拟机,不要用其他版本
创建虚拟机,用最小方式安装
CPU 1个,内存 1G ,硬盘空间默认大小即可,如图-2所示。

按要求配置好ip,同网段之间要能互通,配置好yum,修改主机名
真机能与所有虚拟机互通
主机名 网卡1 网卡2
proxy 192.168.99.5 192.168.88.5
web1 192.168.99.100
web2 192.168.99.200文章来源:https://www.toymoban.com/news/detail-820060.html
client 192.168.88.10文章来源地址https://www.toymoban.com/news/detail-820060.html
到了这里,关于正则表达式、grep过滤工具、sed基本用法、sed基本操作指令、sed应用案例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








