九、原生 Node.js 流
原文:
exploringjs.com/nodejs-shell-scripting/ch_nodejs-streams.html译者:飞龙
协议:CC BY-NC-SA 4.0
-
9.1 总结:异步迭代和异步生成器
-
9.2 流
-
9.2.1 管道
-
9.2.2 文本编码
-
9.2.3 辅助函数:
readableToString() -
9.2.4 一些初步说明
-
-
9.3 可读流
-
9.3.1 创建可读流
-
9.3.2 通过
for-await-of从可读流中读取块 -
9.3.3 通过模块
'node:readlines'从可读流中读取行
-
-
9.4 通过异步生成器转换可读流(ch_nodejs-streams.html#transforming-Readable-via-async-generator)
- 9.4.1 从异步可迭代对象中的块转换为编号行
-
9.5 可写流
-
9.5.1 为文件创建可写流
-
9.5.2 写入可写流
-
-
9.6 快速参考:与流相关的功能(ch_nodejs-streams.html#quick-reference-stream-related-functionality)
-
9.7 进一步阅读和本章的来源
本章是对 Node 的原生流的介绍。它们支持异步迭代,这使它们更容易使用,这也是我们在本章中主要使用的。
请注意,跨平台的web 流在§10“在 Node.js 上使用 web 流”中有所涵盖。我们在本书中主要使用这些。因此,如果您愿意,可以跳过当前章节。
9.1 总结:异步迭代和异步生成器
异步迭代是一种异步检索数据容器内容的协议(意味着当前的“任务”在检索项目之前可能会暂停)。
异步生成器有助于异步迭代。例如,这是一个异步生成器函数:
/**
* @returns an asynchronous iterable
*/
async function* asyncGenerator(asyncIterable) {
for await (const item of asyncIterable) { // input
if (···) {
yield '> ' + item; // output
}
}
}
-
for-await-of循环遍历输入的asyncIterable。这个循环也适用于普通的异步函数。 -
yield将值提供给此生成器返回的异步可迭代对象。
在本章的其余部分,请仔细注意函数是异步函数还是异步生成器函数:
/** @returns a Promise */
async function asyncFunction() { /*···*/ }
/** @returns an async iterable */
async function* asyncGeneratorFunction() { /*···*/ }
9.2 流
流是一种模式,其核心思想是“分而治之”大量数据:如果我们将其分割成较小的部分并一次处理一部分,我们就可以处理它。
Node.js 支持几种流,例如:
-
可读流是我们可以从中读取数据的流。换句话说,它们是数据的来源。一个例子是可读文件流,它允许我们读取文件的内容。
-
可写流是我们可以写入数据的流。换句话说,它们是数据的接收端。一个例子是可写文件流,它允许我们向文件写入数据。
-
转换流既可读又可写。作为可写流,它接收数据块,转换(更改或丢弃)它们,然后将它们作为可读流输出。
9.2.1 管道
为了在多个步骤中处理流数据,我们可以管道(连接)流:
-
输入通过可读流接收。
-
每个处理步骤都是通过转换流执行的。
-
对于最后的处理步骤,我们有两个选项:
-
我们可以将最近的可读流中的数据写入可写流。也就是说,可写流是我们管道的最后一个元素。
-
我们可以以其他方式处理最近的可读流中的数据。
-
部分(2)是可选的。
9.2.2 文本编码
创建文本流时,最好始终指定编码:
-
Node.js 文档中有支持的编码及其默认拼写的列表 - 例如:
-
‘utf8’
-
‘utf16le’
-
‘base64’
-
-
也允许一些不同的拼写。您可以使用
Buffer.isEncoding()来检查哪些是:> buffer.Buffer.isEncoding('utf8') true > buffer.Buffer.isEncoding('utf-8') true > buffer.Buffer.isEncoding('UTF-8') true > buffer.Buffer.isEncoding('UTF:8') false
编码的默认值是null,等同于'utf8'。
9.2.3 辅助函数:readableToString()
我们偶尔会使用以下辅助函数。您不需要理解它的工作原理,只需(大致)了解它的作用。
import * as stream from 'stream';
/**
* Reads all the text in a readable stream and returns it as a string,
* via a Promise.
* @param {stream.Readable} readable
*/
function readableToString(readable) {
return new Promise((resolve, reject) => {
let data = '';
readable.on('data', function (chunk) {
data += chunk;
});
readable.on('end', function () {
resolve(data);
});
readable.on('error', function (err) {
reject(err);
});
});
}
此函数是通过基于事件的 API 实现的。稍后我们将看到一个更简单的方法 - 通过异步迭代。
9.2.4 一些初步说明
-
在本章中,我们只会使用文本流。
-
在示例中,我们偶尔会遇到
await被用于顶层。在这种情况下,我们假设我们在模块内或在异步函数的主体内。 -
每当有换行符时,我们都支持:
-
Unix:
'\n'(LF) -
Windows:
'\r\n'(CR LF)当前平台的换行符可以通过模块os中的常量EOL访问。
-
9.3 可读流
9.3.1 创建可读流
9.3.1.1 从文件创建可读流
我们可以使用fs.createReadStream()来创建可读流:
import * as fs from 'fs';
const readableStream = fs.createReadStream(
'tmp/test.txt', {encoding: 'utf8'});
assert.equal(
await readableToString(readableStream),
'This is a test!\n');
9.3.1.2 Readable.from(): 从可迭代对象创建可读流
静态方法Readable.from(iterable, options?)创建一个可读流,其中包含iterable中包含的数据。iterable可以是同步可迭代对象或异步可迭代对象。参数options是可选的,可以用于指定文本编码等其他内容。
import * as stream from 'stream';
function* gen() {
yield 'One line\n';
yield 'Another line\n';
}
const readableStream = stream.Readable.from(gen(), {encoding: 'utf8'});
assert.equal(
await readableToString(readableStream),
'One line\nAnother line\n');
9.3.1.2.1 从字符串创建可读流
Readable.from()接受任何可迭代对象,因此也可以用于将字符串转换为流:
import {Readable} from 'stream';
const str = 'Some text!';
const readable = Readable.from(str, {encoding: 'utf8'});
assert.equal(
await readableToString(readable),
'Some text!');
目前,Readable.from()将字符串视为任何其他可迭代对象,因此会迭代其代码点。从性能上讲,这并不理想,但对于大多数用例来说应该是可以的。我期望Readable.from()经常与字符串一起使用,所以也许将来会有优化。
9.3.2 通过for-await-of从可读流中读取块
每个可读流都是异步可迭代的,这意味着我们可以使用for-await-of循环来读取其内容:
import * as fs from 'fs';
async function logChunks(readable) {
for await (const chunk of readable) {
console.log(chunk);
}
}
const readable = fs.createReadStream(
'tmp/test.txt', {encoding: 'utf8'});
logChunks(readable);
// Output:
// 'This is a test!\n'
9.3.2.1 在字符串中收集可读流的内容
以下函数是本章开头所见函数的简化重新实现。
import {Readable} from 'stream';
async function readableToString2(readable) {
let result = '';
for await (const chunk of readable) {
result += chunk;
}
return result;
}
const readable = Readable.from('Good morning!', {encoding: 'utf8'});
assert.equal(await readableToString2(readable), 'Good morning!');
请注意,在这种情况下,我们必须使用异步函数,因为我们想要返回一个 Promise。
9.3.3 通过模块'node:readlines'从可读流中读取行
内置模块'node:readline'让我们可以从可读流中读取行:
import * as fs from 'node:fs';
import * as readline from 'node:readline/promises';
const filePath = process.argv[2]; // first command line argument
const rl = readline.createInterface({
input: fs.createReadStream(filePath, {encoding: 'utf-8'}),
});
for await (const line of rl) {
console.log('>', line);
}
rl.close();
9.4 通过异步生成器转换可读流
异步迭代提供了一个优雅的替代方案,用于在多个步骤中处理流式数据的转换流:
-
输入是一个可读流。
-
第一个转换是通过一个异步生成器执行的,该生成器遍历可读流并在适当时产生。
-
可选地,我们可以通过使用更多的异步生成器来进一步转换。
-
最后,我们有几种处理最后一个生成器返回的异步可迭代对象的选项:
-
我们可以通过
Readable.from()将其转换为可读流(稍后可以传输到可写流)。 -
我们可以使用异步函数来处理它。
-
等等。
-
总之,这些是这样的处理管道的组成部分:
可读的
→ 第一个异步生成器 [→ … → 最后一个异步生成器]
→ 可读或异步函数
9.4.1 从块到异步可迭代对象中的编号行
在下一个示例中,我们将看到一个刚刚解释过的处理管道的示例。
import {Readable} from 'stream';
/**
* @param chunkIterable An asynchronous or synchronous iterable
* over “chunks” (arbitrary strings)
* @returns An asynchronous iterable over “lines”
* (strings with at most one newline that always appears at the end)
*/
async function* chunksToLines(chunkIterable) {
let previous = '';
for await (const chunk of chunkIterable) {
let startSearch = previous.length;
previous += chunk;
while (true) {
// Works for EOL === '\n' and EOL === '\r\n'
const eolIndex = previous.indexOf('\n', startSearch);
if (eolIndex < 0) break;
// Line includes the EOL
const line = previous.slice(0, eolIndex+1);
yield line;
previous = previous.slice(eolIndex+1);
startSearch = 0;
}
}
if (previous.length > 0) {
yield previous;
}
}
async function* numberLines(lineIterable) {
let lineNumber = 1;
for await (const line of lineIterable) {
yield lineNumber + ' ' + line;
lineNumber++;
}
}
async function logLines(lineIterable) {
for await (const line of lineIterable) {
console.log(line);
}
}
const chunks = Readable.from(
'Text with\nmultiple\nlines.\n',
{encoding: 'utf8'});
await logLines(numberLines(chunksToLines(chunks))); // (A)
// Output:
// '1 Text with\n'
// '2 multiple\n'
// '3 lines.\n'
处理管道在 A 行设置。步骤是:
-
chunksToLines(): 从具有块的异步可迭代对象转换为具有行的异步可迭代对象。 -
numberLines(): 从具有行的异步可迭代对象转换为具有编号行的异步可迭代对象。 -
logLines(): 记录异步可迭代对象中的项目。
观察:
-
chunksToLines()和numberLines()的输入和输出都是异步可迭代对象。这就是为什么它们是异步生成器(由async和*指示)。 -
logLines()的输入是异步可迭代对象。这就是为什么它是一个异步函数(由async指示)。
9.5 可写流
9.5.1 创建文件的可写流
我们可以使用fs.createWriteStream()来创建可写流:
const writableStream = fs.createWriteStream(
'tmp/log.txt', {encoding: 'utf8'});
9.5.2 向可写流写入数据
在本节中,我们将探讨向可写流写入数据的方法:
-
通过其方法
.write()直接向可写流写入数据。 -
使用模块
stream中的函数pipeline()将可读流传输到可写流。
为了演示这些方法,我们使用它们来实现相同的函数writeIterableToFile()。
可读流的.pipe()方法也支持管道传输,但它有一个缺点,最好避免使用它。
9.5.2.1 writable.write(chunk)
在向流中写入数据时,有两种基于回调的机制可以帮助我们:
-
事件
'drain'表示背压已经解除。 -
函数
finished()在流:-
不再可读或可写
-
已经遇到错误或过早关闭事件
-
在下一个示例中,我们将这些机制转换为 Promise,以便我们可以通过异步函数使用它们:
import * as util from 'util';
import * as stream from 'stream';
import * as fs from 'fs';
import {once} from 'events';
const finished = util.promisify(stream.finished); // (A)
async function writeIterableToFile(iterable, filePath) {
const writable = fs.createWriteStream(filePath, {encoding: 'utf8'});
for await (const chunk of iterable) {
if (!writable.write(chunk)) { // (B)
// Handle backpressure
await once(writable, 'drain');
}
}
writable.end(); // (C)
// Wait until done. Throws if there are errors.
await finished(writable);
}
await writeIterableToFile(
['One', ' line of text.\n'], 'tmp/log.txt');
assert.equal(
fs.readFileSync('tmp/log.txt', {encoding: 'utf8'}),
'One line of text.\n');
stream.finished()的默认版本是基于回调的,但可以通过util.promisify()(A 行)转换为基于 Promise 的版本。
我们使用了以下两种模式:
-
在处理背压的情况下向可写流写入数据(B 行):
if (!writable.write(chunk)) { await once(writable, 'drain'); } -
关闭可写流并等待写入完成(C 行):
writable.end(); await finished(writable);
9.5.2.2 通过stream.pipeline()将可读流传输到可写流
在 A 行,我们使用stream.pipeline()的 Promise 版本将可读流readable传输到可写流writable:
import * as stream from 'stream';
import * as fs from 'fs';
const pipeline = util.promisify(stream.pipeline);
async function writeIterableToFile(iterable, filePath) {
const readable = stream.Readable.from(
iterable, {encoding: 'utf8'});
const writable = fs.createWriteStream(filePath);
await pipeline(readable, writable); // (A)
}
await writeIterableToFile(
['One', ' line of text.\n'], 'tmp/log.txt');
// ···
9.5.2.3 不推荐:readable.pipe(destination)
可读的.pipe()方法也支持管道传输,但有一个警告:如果可读流发出错误,则可写流不会自动关闭。pipeline()没有这个警告。
9.6 快速参考:与流相关的功能
模块os:
-
const EOL: string(自 0.7.8 起)(https://nodejs.org/api/os.html#os_os_eol)包含当前平台使用的行尾字符序列。
模块buffer:
-
Buffer.isEncoding(encoding: string): boolean(自 0.9.1 起)(https://nodejs.org/api/buffer.html#buffer_class_method_buffer_isencoding_encoding)如果
encoding正确命名了受支持的 Node.js 文本编码之一,则返回true。支持的编码包括:-
'utf8' -
'utf16le' -
'ascii' -
'latin1 -
'base64' -
'hex'(每个字节表示为两个十六进制字符)
-
模块stream:
-
Readable.prototype[Symbol.asyncIterator](): AsyncIterableIterator<any>(自 10.0.0 起)(https://nodejs.org/api/stream.html#stream_readable_symbol_asynciterator)可读流是异步可迭代的。例如,您可以在异步函数或异步生成器中使用
for-await-of循环来迭代它们。 -
finished(stream: ReadableStream | WritableStream | ReadWriteStream, callback: (err?: ErrnoException | null) => void): () => Promise<void>(自 10.0.0 起)当读取/写入完成或出现错误时,返回的 Promise 将被解决。
此 promisified 版本的创建方式如下:
const finished = util.promisify(stream.finished); -
pipeline(...streams: Array<ReadableStream|ReadWriteStream|WritableStream>): Promise<void>(自 10.0.0 起)流之间的管道。当管道完成或出现错误时,返回的 Promise 将被解决。
此 promisified 版本的创建方式如下:
const pipeline = util.promisify(stream.pipeline); -
Readable.from(iterable: Iterable<any> | AsyncIterable<any>, options?: ReadableOptions): Readable(自 12.3.0 起)将可迭代对象转换为可读流。
interface ReadableOptions { highWaterMark?: number; encoding?: string; objectMode?: boolean; read?(this: Readable, size: number): void; destroy?(this: Readable, error: Error | null, callback: (error: Error | null) => void): void; autoDestroy?: boolean; }这些选项与
Readable构造函数的选项相同,并在此处有文档记录。
模块fs:
-
createReadStream(path: string | Buffer | URL, options?: string | {encoding?: string; start?: number}): ReadStream(自 2.3.0 起)创建可读流。还有更多选项可用。
-
createWriteStream(path: PathLike, options?: string | {encoding?: string; flags?: string; mode?: number; start?: number}): WriteStream(自 2.3.0 起)使用
.flags选项,您可以指定是要写入还是追加,以及文件存在或不存在时会发生什么。还有更多选项可用。
本节中的静态类型信息基于Definitely Typed。
9.7 进一步阅读和本章的来源
-
Node.js 文档中的“流与异步生成器和异步迭代器兼容性”章节
-
“JavaScript for impatient programmers”中的“异步函数”章节
-
“JavaScript for impatient programmers”中的“异步迭代”章节
评论
十、在 Node.js 上使用 web 流
原文:
exploringjs.com/nodejs-shell-scripting/ch_web-streams.html译者:飞龙
协议:CC BY-NC-SA 4.0
-
10.1 什么是 web 流?
-
10.1.1 流的种类
-
10.1.2 管道链
-
10.1.3 背压
-
10.1.4 Node.js 中对 web 流的支持
-
-
10.2 从 ReadableStreams 读取
-
10.2.1 通过 Readers 消费 ReadableStreams
-
10.2.2 通过异步迭代消费 ReadableStreams
-
10.2.3 将 ReadableStreams 管道到 WritableStreams
-
-
10.3 通过包装将数据源转换为 ReadableStreams
-
10.3.1 实现底层源的第一个示例
-
10.3.2 使用 ReadableStream 包装推送源或拉取源
-
-
10.4 写入 WritableStreams
-
10.4.1 通过 Writers 写入 WritableStreams
-
10.4.2 管道到 WritableStreams
-
-
10.5 通过包装将数据汇转换为 WritableStreams
-
10.5.1 示例:跟踪 ReadableStream
-
10.5.2 示例:收集写入字符串的 WriteStream 块
-
-
10.6 使用 TransformStreams
- 10.6.1 标准 TransformStreams
-
10.7 实现自定义 TransformStreams
-
10.7.1 示例:将任意块的流转换为行流
-
10.7.2 提示:异步生成器也非常适合转换流
-
-
10.8 更深入地了解背压
-
10.8.1 信号背压
-
10.8.2 对背压的反应
-
-
10.9 字节流
-
10.9.1 可读字节流
-
10.9.2 示例:填充随机数据的无限可读字节流
-
10.9.3 示例:压缩可读字节流
-
10.9.4 示例:通过
fetch()读取网页
-
-
10.10 Node.js 特定的辅助函数
-
10.11 进一步阅读
Web 流 是一种标准的 流,现在在所有主要的 web 平台上都得到支持:web 浏览器、Node.js 和 Deno。(流是一种从各种来源顺序读取和写入数据的抽象,例如文件、托管在服务器上的数据等。)
例如,全局函数 fetch()(用于下载在线资源)异步返回一个具有 web 流属性 .body 的 Response。
本章涵盖了 Node.js 上的 web 流,但我们所学的大部分内容都适用于支持它们的所有 web 平台。
10.1 什么是网络流?
让我们首先概述一下网络流的一些基本知识。之后,我们将快速转移到示例。
流是一种用于访问数据的数据结构,例如:
-
文件
-
托管在 Web 服务器上的数据
-
等等。
它们的两个好处是:
-
我们可以处理大量数据,因为流允许我们将它们分割成较小的片段(所谓的chunks),我们可以一次处理一个。
-
我们可以在处理不同数据时使用相同的数据结构,流。这样可以更容易地重用代码。
Web streams(“web”通常被省略)是一个相对较新的标准,起源于 Web 浏览器,但现在也受到 Node.js 和 Deno 的支持(如此MDN 兼容性表所示)。
在网络流中,chunks 通常是:
-
文本流:字符串
-
二进制流:Uint8Arrays(一种 TypedArray)
10.1.1 流的种类
有三种主要类型的网络流:
-
一个 ReadableStream 用于从source读取数据。执行此操作的代码称为consumer。
-
一个 WritableStream 用于向sink写入数据。执行此操作的代码称为producer。
-
TransformStream 由两个流组成:
-
它从其writable side接收输入,即 WritableStream。
-
它将输出发送到其readable side,即 ReadableStream。
这个想法是通过“管道传输”TransformStream 来转换数据。也就是说,我们将数据写入可写端,并从可读端读取转换后的数据。以下 TransformStreams 内置在大多数 JavaScript 平台中(稍后会详细介绍):
-
因为 JavaScript 字符串是 UTF-16 编码的,所以在 JavaScript 中,UTF-8 编码的数据被视为二进制数据。
TextDecoderStream将这样的数据转换为字符串。 -
TextEncoderStream将 JavaScript 字符串转换为 UTF-8 数据。 -
CompressionStream将二进制数据压缩为 GZIP 和其他压缩格式。 -
DecompressionStream从 GZIP 和其他压缩格式中解压缩二进制数据。
-
ReadableStreams,WritableStreams 和 TransformStreams 可用于传输文本或二进制数据。在本章中,我们将主要进行前者。 字节流用于二进制数据,在最后简要提到。
10.1.2 管道链路
Piping是一种操作,它让我们将一个 ReadableStream 连接到一个 WritableStream:只要 ReadableStream 产生数据,此操作就会读取该数据并将其写入 WritableStream。如果我们连接了两个流,我们就可以方便地将数据从一个位置传输到另一个位置(例如复制文件)。但是,我们也可以连接多于两个流,并获得可以以各种方式处理数据的管道链路。这是一个管道链路的例子:
-
它以一个 ReadableStream 开始。
-
接下来是一个或多个 TransformStreams。
-
链路以 WritableStream 结束。
通过将前者连接到后者的可写端,将一个 ReadableStream 连接到 TransformStream。类似地,通过将前者的可读端连接到后者的可写端,将一个 TransformStream 连接到另一个 TransformStream。并且通过将前者的可读端连接到后者的可写端,将一个 TransformStream 连接到一个 WritableStream。
10.1.3 背压
管道链路中的一个问题是,成员可能会收到比它目前能处理的更多数据。 背压是解决这个问题的一种技术:它使数据的接收者能够告诉发送者应该暂时停止发送数据,以便接收者不会被压倒。
另一种看待背压的方式是作为一个信号,通过管道链路向后传播,从被压倒的成员到链路的开始。例如,考虑以下管道链路:
ReadableStream -pipeTo-> TransformStream -pipeTo-> WriteableStream
这是背压通过这个链路传播的方式:
-
最初,WriteableStream 发出信号,表明它暂时无法处理更多数据。
-
管道停止从 TransformStream 中读取。
-
输入在 TransformStream 中积累(被缓冲)。
-
TransformStream 发出满的信号。
-
管道停止从 ReadableStream 中读取。
我们已经到达管道链的开头。因此,在 ReadableStream 中没有数据积累(也被缓冲),WritableStream 有时间恢复。一旦它恢复,它会发出信号表明它已准备好再次接收数据。该信号也会通过链返回,直到它到达 ReadableStream,数据处理恢复。
在这第一次对背压的探讨中,为了让事情更容易理解,省略了一些细节。这些将在以后进行讨论。
10.1.4 Node.js 中对 web 流的支持
在 Node.js 中,Web 流可以从两个来源获得:
-
来自模块
'node:stream/web' -
通过全局变量(就像在 Web 浏览器中)
目前,只有一个 API 在 Node.js 中直接支持 web 流 – Fetch API:
const response = await fetch('https://example.com');
const readableStream = response.body;
对于其他事情,我们需要使用模块'node:stream'中以下静态方法之一,将 Node.js 流转换为 Web 流,反之亦然:
-
Node.js 的 Readable 可以转换为 WritableStreams,反之亦然:
-
Readable.toWeb(nodeReadable) -
Readable.fromWeb(webReadableStream, options?)
-
-
Node.js 的 Writable 可以转换为 ReadableStreams,反之亦然:
-
Writable.toWeb(nodeWritable) -
Writable.fromWeb(webWritableStream, options?)
-
-
Node.js 的 Duplex 可以转换为 TransformStreams,反之亦然:
-
Duplex.toWeb(nodeDuplex) -
Duplex.fromWeb(webTransformStream, options?)
-
还有一个 API 部分支持 web 流:FileHandles 有方法.readableWebStream()。
10.2 从 ReadableStreams 中读取
ReadableStreams 让我们从各种来源读取数据块。它们具有以下类型(随意浏览此类型及其属性的解释;当我们在示例中遇到它们时,它们将再次被解释):
interface ReadableStream<TChunk> {
getReader(): ReadableStreamDefaultReader<TChunk>;
readonly locked: boolean;
[Symbol.asyncIterator](): AsyncIterator<TChunk>;
cancel(reason?: any): Promise<void>;
pipeTo(
destination: WritableStream<TChunk>,
options?: StreamPipeOptions
): Promise<void>;
pipeThrough<TChunk2>(
transform: ReadableWritablePair<TChunk2, TChunk>,
options?: StreamPipeOptions
): ReadableStream<TChunk2>;
// Not used in this chapter:
tee(): [ReadableStream<TChunk>, ReadableStream<TChunk>];
}
interface StreamPipeOptions {
signal?: AbortSignal;
preventClose?: boolean;
preventAbort?: boolean;
preventCancel?: boolean;
}
这些属性的解释:
-
.getReader()返回一个 Reader – 通过它我们可以从 ReadableStream 中读取。ReadableStreams 返回 Readers 类似于可迭代对象返回迭代器。 -
.locked: 一次只能有一个活动的 Reader 读取 ReadableStream。当一个 Reader 正在使用时,ReadableStream 被锁定,无法调用.getReader()。 -
[Symbol.asyncIterator](https://exploringjs.com/impatient-js/ch_async-iteration.html): 这个方法使得 ReadableStreams 可以异步迭代。目前只在一些平台上实现。 -
.cancel(reason)取消流,因为消费者对它不再感兴趣。reason被传递给 ReadableStream 的底层源的.cancel()方法(稍后会详细介绍)。返回的 Promise 在此操作完成时实现。 -
.pipeTo()将其 ReadableStream 的内容传送到 WritableStream。返回的 Promise 在此操作完成时实现。.pipeTo()确保背压、关闭、错误等都正确地通过管道链传播。我们可以通过它的第二个参数指定选项:-
.signal让我们向这个方法传递一个 AbortSignal,这使我们能够通过 AbortController 中止管道传输。 -
.preventClose: 如果为true,它会阻止在 ReadableStream 关闭时关闭 WritableStream。当我们想要将多个 ReadableStream 管道到同一个 WritableStream 时,这是有用的。 -
其余选项超出了本章的范围。它们在web 流规范中有文档记录。
-
-
.pipeThrough()将其 ReadableStream 连接到一个 ReadableWritablePair(大致是一个 TransformStream,稍后会详细介绍)。它返回生成的 ReadableStream(即 ReadableWritablePair 的可读端)。
以下小节涵盖了三种消费 ReadableStreams 的方式:
-
通过 Readers 进行读取
-
通过异步迭代进行读取
-
将 ReadableStreams 连接到 WritableStreams
10.2.1 通过 Reader 消费 ReadableStreams
我们可以使用Readers从 ReadableStreams 中读取数据。它们具有以下类型(随意浏览此类型及其属性的解释;当我们在示例中遇到它们时,它们将再次被解释):
interface ReadableStreamGenericReader {
readonly closed: Promise<undefined>;
cancel(reason?: any): Promise<void>;
}
interface ReadableStreamDefaultReader<TChunk>
extends ReadableStreamGenericReader
{
releaseLock(): void;
read(): Promise<ReadableStreamReadResult<TChunk>>;
}
interface ReadableStreamReadResult<TChunk> {
done: boolean;
value: TChunk | undefined;
}
这些属性的解释:
-
.closed:此 Promise 在流关闭后被满足。如果流出现错误或者在流关闭之前 Reader 的锁被释放,它将被拒绝。 -
.cancel():在活动的 Reader 中,此方法取消关联的 ReadableStream。 -
.releaseLock()停用 Reader 并解锁其流。 -
.read()返回一个 Promise,用于 ReadableStreamReadResult(一个包装的块),它有两个属性:-
.done是一个布尔值,只要可以读取块,就为false,在最后一个块之后为true。 -
.value是块(或在最后一个块之后是undefined)。
-
如果您了解迭代的工作原理,ReadableStreamReadResult 可能会很熟悉:ReadableStreams 类似于可迭代对象,Readers 类似于迭代器,而 ReadableStreamReadResults 类似于迭代器方法.next()返回的对象。
以下代码演示了使用 Readers 的协议:
const reader = readableStream.getReader(); // (A)
assert.equal(readableStream.locked, true); // (B)
try {
while (true) {
const {done, value: chunk} = await reader.read(); // (C)
if (done) break;
// Use `chunk`
}
} finally {
reader.releaseLock(); // (D)
}
**获取 Reader。**我们不能直接从readableStream中读取,我们首先需要获取一个Reader(行 A)。每个 ReadableStream 最多可以有一个 Reader。获取 Reader 后,readableStream被锁定(行 B)。在我们可以再次调用.getReader()之前,我们必须调用.releaseLock()(行 D)。
读取块。.read()返回一个带有属性.done和.value的对象的 Promise(行 C)。在读取最后一个块之后,.done为true。这种方法类似于 JavaScript 中异步迭代的工作方式。
10.2.1.1 示例:通过 ReadableStream 读取文件
在下面的示例中,我们从文本文件data.txt中读取块(字符串):
import * as fs from 'node:fs';
import {Readable} from 'node:stream';
const nodeReadable = fs.createReadStream(
'data.txt', {encoding: 'utf-8'});
const webReadableStream = Readable.toWeb(nodeReadable); // (A)
const reader = webReadableStream.getReader();
try {
while (true) {
const {done, value} = await reader.read();
if (done) break;
console.log(value);
}
} finally {
reader.releaseLock();
}
// Output:
// 'Content of text file\n'
我们将 Node.js Readable 转换为 web ReadableStream(行 A)。然后我们使用先前解释的协议来读取块。
10.2.1.2 示例:使用 ReadableStream 内容组装字符串
在下一个示例中,我们将所有 ReadableStream 的块连接成一个字符串并返回它:
/**
* Returns a string with the contents of `readableStream`.
*/
async function readableStreamToString(readableStream) {
const reader = readableStream.getReader();
try {
let result = '';
while (true) {
const {done, value} = await reader.read();
if (done) {
return result; // (A)
}
result += value;
}
} finally {
reader.releaseLock(); // (B)
}
}
方便的是,finally子句总是被执行 - 无论我们如何离开try子句。也就是说,如果我们返回一个结果(行 A),锁将被正确释放(行 B)。
10.2.2 通过异步迭代消费 ReadableStreams
ReadableStreams 也可以通过异步迭代进行消费:
const iterator = readableStream[Symbol.asyncIterator]();
let exhaustive = false;
try {
while (true) {
let chunk;
({done: exhaustive, value: chunk} = await iterator.next());
if (exhaustive) break;
console.log(chunk);
}
} finally {
// If the loop was terminated before we could iterate exhaustively
// (via an exception or `return`), we must call `iterator.return()`.
// Check if that was the case.
if (!exhaustive) {
iterator.return();
}
}
值得庆幸的是,for-await-of循环为我们处理了异步迭代的所有细节:
for await (const chunk of readableStream) {
console.log(chunk);
}
10.2.2.1 示例:使用异步迭代读取流
让我们重新尝试从文件中读取文本。这次,我们使用异步迭代而不是 Reader:
import * as fs from 'node:fs';
import {Readable} from 'node:stream';
const nodeReadable = fs.createReadStream(
'text-file.txt', {encoding: 'utf-8'});
const webReadableStream = Readable.toWeb(nodeReadable);
for await (const chunk of webReadableStream) {
console.log(chunk);
}
// Output:
// 'Content of text file'
10.2.2.2 示例:使用 ReadableStream 内容组装字符串
我们以前使用 Reader 来组装一个包含 ReadableStream 内容的字符串。有了异步迭代,代码变得更简单了:
/**
* Returns a string with the contents of `readableStream`.
*/
async function readableStreamToString2(readableStream) {
let result = '';
for await (const chunk of readableStream) {
result += chunk;
}
return result;
}
10.2.2.3 注意事项:浏览器不支持对 ReadableStreams 进行异步迭代
目前,Node.js 和 Deno 支持对 ReadableStreams 进行异步迭代,但 Web 浏览器不支持:有一个 GitHub 问题链接到错误报告。
鉴于尚不完全清楚浏览器将如何支持异步迭代,包装比填充更安全。以下代码基于Chromium bug 报告中的建议:
async function* getAsyncIterableFor(readableStream) {
const reader = readableStream.getReader();
try {
while (true) {
const {done, value} = await reader.read();
if (done) return;
yield value;
}
} finally {
reader.releaseLock();
}
}
10.2.3 将可读流导入可写流
可读流有两种管道方法:
-
readableStream.pipeTo(writeableStream)同步返回一个 Promisep。它异步读取readableStream的所有块,并将它们写入writableStream。完成后,它会实现p。当我们探索可写流时,我们将看到
.pipeTo()的示例,因为它提供了一种方便的方式将数据传输到其中。 -
readableStream.pipeThrough(transformStream)将readableStream导入transformStream.writable并返回transformStream.readable(每个 TransformStream 都有这些属性,它们指向其可写侧和可读侧)。另一种看待这个操作的方式是,我们通过连接transformStream到readableStream创建一个新的可读流。当我们探索 TransformStreams 时,我们将看到
.pipeThrough()的示例,因为这是它们主要使用的方法。
10.3 将数据源通过包装转换为可读流
如果我们想通过一个可读流读取外部源,我们可以将其包装在一个适配器对象中,并将该对象传递给ReadableStream构造函数。适配器对象被称为可读流的底层源(当我们更仔细地看 backpressure 时,将解释排队策略):
new ReadableStream(underlyingSource?, queuingStrategy?)
这是底层源的类型(随意浏览此类型及其属性的解释;当我们在示例中遇到它们时,它们将再次解释):
interface UnderlyingSource<TChunk> {
start?(
controller: ReadableStreamController<TChunk>
): void | Promise<void>;
pull?(
controller: ReadableStreamController<TChunk>
): void | Promise<void>;
cancel?(reason?: any): void | Promise<void>;
// Only used in byte streams and ignored in this section:
type: 'bytes' | undefined;
autoAllocateChunkSize: bigint;
}
这是当可读流调用这些方法时:
-
在调用
ReadableStream的构造函数后立即调用.start(controller)。 -
每当可读流的内部队列中有空间时,都会调用
.pull(controller)。直到队列再次满了为止,它会被重复调用。此方法只会在.start()完成后调用。如果.pull()没有入队任何内容,它将不会再次被调用。 -
如果可读流的消费者通过
readableStream.cancel()或reader.cancel()取消它,将调用.cancel(reason)。reason是传递给这些方法的值。
这些方法中的每一个都可以返回一个 Promise,并且在 Promise 解决之前不会采取进一步的步骤。如果我们想要做一些异步操作,这是有用的。
.start()和.pull()的参数controller让它们访问流。它具有以下类型:
type ReadableStreamController<TChunk> =
| ReadableStreamDefaultController<TChunk>
| ReadableByteStreamController<TChunk> // ignored here
;
interface ReadableStreamDefaultController<TChunk> {
enqueue(chunk?: TChunk): void;
readonly desiredSize: number | null;
close(): void;
error(err?: any): void;
}
现在,块是字符串。我们稍后将介绍字节流,其中 Uint8Arrays 很常见。这些方法的作用是:
-
.enqueue(chunk)将chunk添加到可读流的内部队列。 -
.desiredSize指示.enqueue()写入的队列中有多少空间。如果队列已满,则为零,如果超过了最大大小,则为负。因此,如果期望大小为零或负,则我们必须停止入队。-
如果流关闭,其期望大小为零。
-
如果流处于错误模式,其期望大小为
null。
-
-
.close()关闭可读流。消费者仍然可以清空队列,但之后,流将结束。底层源调用此方法很重要-否则,读取其流将永远不会结束。 -
.error(err)将流置于错误模式:以后与它的所有交互都将以错误值err失败。
10.3.1 实现底层源的第一个示例
在我们实现底层源的第一个示例中,我们只提供了.start()方法。我们将在下一小节中看到.pull()的用例。
const readableStream = new ReadableStream({
start(controller) {
controller.enqueue('First line\n'); // (A)
controller.enqueue('Second line\n'); // (B)
controller.close(); // (C)
},
});
for await (const chunk of readableStream) {
console.log(chunk);
}
// Output:
// 'First line\n'
// 'Second line\n'
我们使用控制器创建一个具有两个块(行 A 和行 B)的流。关闭流很重要(行 C)。否则,for-await-of循环永远不会结束!
请注意,这种入队的方式并不完全安全:存在超出内部队列容量的风险。我们很快将看到如何避免这种风险。
10.3.2 使用 ReadableStream 包装推送源或拉取源
一个常见的场景是将推送源或拉取源转换为 ReadableStream。源是推送还是拉取决定了我们将如何与 UnderlyingSource 连接到 ReadableStream:
-
推送源:这样的源在有新数据时通知我们。我们使用
.start()来设置监听器和支持数据结构。如果我们收到太多数据,期望的大小不再是正数,我们必须告诉我们的源暂停。如果以后调用了.pull(),我们可以取消暂停。对外部源在期望的大小变为非正数时暂停的反应称为应用背压。 -
拉取源:我们向这样的源请求新数据-通常是异步的。因此,我们通常在
.start()中不做太多事情,并在调用.pull()时检索数据。
接下来我们将看到两种来源的例子。
10.3.2.1 示例:从具有背压支持的推送源创建一个 ReadableStream
在下面的示例中,我们将一个 ReadableStream 包装在一个套接字周围-它向我们推送数据(它调用我们)。这个例子来自 web 流规范:
function makeReadableBackpressureSocketStream(host, port) {
const socket = createBackpressureSocket(host, port);
return new ReadableStream({
start(controller) {
socket.ondata = event => {
controller.enqueue(event.data);
if (controller.desiredSize <= 0) {
// The internal queue is full, so propagate
// the backpressure signal to the underlying source.
socket.readStop();
}
};
socket.onend = () => controller.close();
socket.onerror = () => controller.error(
new Error('The socket errored!'));
},
pull() {
// This is called if the internal queue has been emptied, but the
// stream’s consumer still wants more data. In that case, restart
// the flow of data if we have previously paused it.
socket.readStart();
},
cancel() {
socket.close();
},
});
}
10.3.2.2 示例:从拉取源创建一个 ReadableStream
工具函数iterableToReadableStream()接受一个块的可迭代对象,并将其转换为一个 ReadableStream:
/**
* @param iterable an iterable (asynchronous or synchronous)
*/
function iterableToReadableStream(iterable) {
return new ReadableStream({
start() {
if (typeof iterable[Symbol.asyncIterator] === 'function') {
this.iterator = iterable[Symbol.asyncIterator]();
} else if (typeof iterable[Symbol.iterator] === 'function') {
this.iterator = iterable[Symbol.iterator]();
} else {
throw new Error('Not an iterable: ' + iterable);
}
},
async pull(controller) {
if (this.iterator === null) return;
// Sync iterators return non-Promise values,
// but `await` doesn’t mind and simply passes them on
const {value, done} = await this.iterator.next();
if (done) {
this.iterator = null;
controller.close();
return;
}
controller.enqueue(value);
},
cancel() {
this.iterator = null;
controller.close();
},
});
}
让我们使用一个异步生成器函数来创建一个异步可迭代对象,并将该可迭代对象转换为一个 ReadableStream:
async function* genAsyncIterable() {
yield 'how';
yield 'are';
yield 'you';
}
const readableStream = iterableToReadableStream(genAsyncIterable());
for await (const chunk of readableStream) {
console.log(chunk);
}
// Output:
// 'how'
// 'are'
// 'you'
iterableToReadableStream()也适用于同步可迭代对象:
const syncIterable = ['hello', 'everyone'];
const readableStream = iterableToReadableStream(syncIterable);
for await (const chunk of readableStream) {
console.log(chunk);
}
// Output:
// 'hello'
// 'everyone'
可能会有一个静态的辅助方法ReadableStream.from(),提供这个功能(请参阅其拉取请求以获取更多信息)。
10.4 向 WritableStreams 写入
WritableStreams 让我们向各种接收器写入数据块。它们具有以下类型(随意浏览此类型和其属性的解释;当我们在示例中遇到它们时,它们将再次解释):
interface WritableStream<TChunk> {
getWriter(): WritableStreamDefaultWriter<TChunk>;
readonly locked: boolean;
close(): Promise<void>;
abort(reason?: any): Promise<void>;
}
这些属性的解释:
-
.getWriter()返回一个 Writer-通过它我们可以向 WritableStream 写入数据的对象。 -
.locked:WritableStream 一次只能有一个活动的 Writer。当一个 Writer 正在使用时,WritableStream 被锁定,无法调用.getWriter()。 -
.close()关闭流:-
底层接收器(稍后会详细介绍)在关闭之前仍将接收所有排队的块。
-
从现在开始,所有的写入尝试都将无声地失败(没有错误)。
-
该方法返回一个 Promise,如果接收器成功写入所有排队的块并关闭,将实现该 Promise。如果在这些步骤中发生任何错误,它将被拒绝。
-
-
.abort()中止流:-
它将流置于错误模式。
-
返回的 Promise 在接收器成功关闭时实现,如果发生错误则拒绝。
-
以下小节涵盖了向 WritableStreams 发送数据的两种方法:
-
通过 Writers 向 WritableStreams 写入
-
将数据传输到 WritableStreams
10.4.1 通过 Writers 向 WritableStreams 写入
我们可以使用Writers向 WritableStreams 写入。它们具有以下类型(随意浏览此类型和其属性的解释;当我们在示例中遇到它们时,它们将再次解释):
interface WritableStreamDefaultWriter<TChunk> {
readonly desiredSize: number | null;
readonly ready: Promise<undefined>;
write(chunk?: TChunk): Promise<void>;
releaseLock(): void;
close(): Promise<void>;
readonly closed: Promise<undefined>;
abort(reason?: any): Promise<void>;
}
这些属性的解释:
-
.desiredSize指示 WriteStream 队列中有多少空间。如果队列已满,则为零,如果超过最大大小,则为负数。因此,如果期望的大小为零或负数,我们必须停止写入。-
如果流关闭,它的期望大小为零。
-
如果流处于错误模式,它的期望大小为
null。
-
-
.ready返回一个 Promise,在期望的大小从非正数变为正数时实现。这意味着没有背压活动,可以写入数据。如果期望的大小后来再次变为非正数,则会创建并返回一个新的待处理 Promise。 -
.write()将一个块写入流。它返回一个 Promise,在写入成功后实现,如果有错误则拒绝。 -
.releaseLock()释放 Writer 对其流的锁定。 -
.close()具有与关闭 Writer 流相同的效果。 -
.closed返回一个 Promise,在流关闭时被实现。 -
.abort()具有与中止 Writer 流相同的效果。
以下代码显示了使用 Writers 的协议:
const writer = writableStream.getWriter(); // (A)
assert.equal(writableStream.locked, true); // (B)
try {
// Writing the chunks (explained later)
} finally {
writer.releaseLock(); // (C)
}
我们不能直接向writableStream写入,我们首先需要获取一个Writer(A 行)。每个 WritableStream 最多只能有一个 Writer。在获取了 Writer 之后,writableStream被锁定(B 行)。在我们可以再次调用.getWriter()之前,我们必须调用.releaseLock()(C 行)。
有三种写入块的方法。
10.4.1.1 写入方法 1:等待.write()(处理背压效率低下)
第一种写入方法是等待每个.write()的结果:
await writer.write('Chunk 1');
await writer.write('Chunk 2');
await writer.close();
由.write()返回的 Promise 在我们传递给它的块成功写入时实现。“成功写入”具体意味着什么取决于 WritableStream 的实现方式 - 例如,对于文件流,该块可能已发送到操作系统,但仍然驻留在缓存中,因此实际上尚未写入磁盘。
由.close()返回的 Promise 在流关闭时实现。
这种写入方法的一个缺点是等待写入成功意味着队列没有被使用。因此,数据吞吐量可能会较低。
10.4.1.2 写入方法 2:忽略.write()拒绝(忽略背压)
在第二种写入方法中,我们忽略了.write()返回的 Promise,只等待.close()返回的 Promise:
writer.write('Chunk 1').catch(() => {}); // (A)
writer.write('Chunk 2').catch(() => {}); // (B)
await writer.close(); // reports errors
.write()的同步调用将块添加到 WritableStream 的内部队列中。通过不等待返回的 Promises,我们不必等待每个块被写入。但是,等待.close()确保队列为空,并且所有写入都成功后我们才继续。
在 A 行和 B 行调用.catch()是必要的,以避免在写入过程中出现问题时出现有关未处理的 Promise 拒绝的警告。这样的警告通常会记录在控制台上。我们可以忽略.write()报告的错误,因为.close()也会向我们报告这些错误。
通过使用一个忽略 Promise 拒绝的辅助函数,可以改进先前的代码:
ignoreRejections(
writer.write('Chunk 1'),
writer.write('Chunk 2'),
);
await writer.close(); // reports errors
function ignoreRejections(...promises) {
for (const promise of promises) {
promise.catch(() => {});
}
}
这种方法的一个缺点是忽略了背压:我们只是假设队列足够大,可以容纳我们写入的所有内容。
10.4.1.3 写入方法 3:等待.ready(高效处理背压)
在这种写入方法中,我们通过等待 Writer getter.ready来有效地处理背压:
await writer.ready; // reports errors
// How much room do we have?
console.log(writer.desiredSize);
writer.write('Chunk 1').catch(() => {});
await writer.ready; // reports errors
// How much room do we have?
console.log(writer.desiredSize);
writer.write('Chunk 2').catch(() => {});
await writer.close(); // reports errors
.ready中的 Promise 在流从有背压到无背压的转换时实现。
10.4.1.4 示例:通过 Writer 写入文件
在这个例子中,我们通过 WritableStream 创建一个文本文件data.txt:
import * as fs from 'node:fs';
import {Writable} from 'node:stream';
const nodeWritable = fs.createWriteStream(
'new-file.txt', {encoding: 'utf-8'}); // (A)
const webWritableStream = Writable.toWeb(nodeWritable); // (B)
const writer = webWritableStream.getWriter();
try {
await writer.write('First line\n');
await writer.write('Second line\n');
await writer.close();
} finally {
writer.releaseLock()
}
在 A 行,我们为文件data.txt创建了一个 Node.js 流。在 B 行,我们将这个流转换为 web 流。然后我们使用 Writer 将字符串写入其中。
10.4.2 向 WritableStreams 进行管道传输
除了使用 Writers,我们还可以通过将 ReadableStreams 传输到 WritableStreams 来向 WritableStreams 写入:
await readableStream.pipeTo(writableStream);
由.pipeTo()返回的 Promise 在传输成功完成时实现。
10.4.2.1 管道传输是异步进行的
管道传输是在当前任务完成或暂停后执行的。以下代码演示了这一点:
const readableStream = new ReadableStream({ // (A)
start(controller) {
controller.enqueue('First line\n');
controller.enqueue('Second line\n');
controller.close();
},
});
const writableStream = new WritableStream({ // (B)
write(chunk) {
console.log('WRITE: ' + JSON.stringify(chunk));
},
close() {
console.log('CLOSE WritableStream');
},
});
console.log('Before .pipeTo()');
const promise = readableStream.pipeTo(writableStream); // (C)
promise.then(() => console.log('Promise fulfilled'));
console.log('After .pipeTo()');
// Output:
// 'Before .pipeTo()'
// 'After .pipeTo()'
// 'WRITE: "First line\n"'
// 'WRITE: "Second line\n"'
// 'CLOSE WritableStream'
// 'Promise fulfilled'
在 A 行我们创建一个 ReadableStream。在 B 行我们创建一个 WritableStream。
我们可以看到.pipeTo()(行 C)立即返回。在一个新的任务中,块被读取和写入。然后writableStream被关闭,最后,promise被实现。
10.4.2.2 示例:将数据管道到文件的可写流
在下面的示例中,我们为一个文件创建一个 WritableStream,并将一个 ReadableStream 管道传递给它:
const webReadableStream = new ReadableStream({ // (A)
async start(controller) {
controller.enqueue('First line\n');
controller.enqueue('Second line\n');
controller.close();
},
});
const nodeWritable = fs.createWriteStream( // (B)
'data.txt', {encoding: 'utf-8'});
const webWritableStream = Writable.toWeb(nodeWritable); // (C)
await webReadableStream.pipeTo(webWritableStream); // (D)
在 A 行,我们创建了一个 ReadableStream。在 B 行,我们为文件data.txt创建了一个 Node.js 流。在 C 行,我们将这个流转换为 web 流。在 D 行,我们将我们的webReadableStream管道传递给文件的 WritableStream。
10.4.2.3 示例:将两个 ReadableStreams 写入到一个 WritableStream
在下面的示例中,我们将两个 ReadableStreams 写入单个 WritableStream。
function createReadableStream(prefix) {
return new ReadableStream({
async start(controller) {
controller.enqueue(prefix + 'chunk 1');
controller.enqueue(prefix + 'chunk 2');
controller.close();
},
});
}
const writableStream = new WritableStream({
write(chunk) {
console.log('WRITE ' + JSON.stringify(chunk));
},
close() {
console.log('CLOSE');
},
abort(err) {
console.log('ABORT ' + err);
},
});
await createReadableStream('Stream 1: ')
.pipeTo(writableStream, {preventClose: true}); // (A)
await createReadableStream('Stream 2: ')
.pipeTo(writableStream, {preventClose: true}); // (B)
await writableStream.close();
// Output
// 'WRITE "Stream 1: chunk 1"'
// 'WRITE "Stream 1: chunk 2"'
// 'WRITE "Stream 2: chunk 1"'
// 'WRITE "Stream 2: chunk 2"'
// 'CLOSE'
我们告诉.pipeTo()在 ReadableStream 关闭后不关闭 WritableStream(行 A 和行 B)。因此,在行 A 之后,WritableStream 保持打开状态,我们可以将另一个 ReadableStream 管道传递给它。
10.5 将数据接收端通过包装转换为可写流
如果我们想通过 WritableStream 写入到外部接收端,我们可以将其包装在一个适配器对象中,并将该对象传递给WritableStream的构造函数。适配器对象被称为 WritableStream 的底层接收端(当我们更仔细地看反压时,排队策略将在稍后解释):
new WritableStream(underlyingSink?, queuingStrategy?)
这是底层接收端的类型(随意浏览此类型和其属性的解释;当我们在示例中遇到它们时,它们将再次解释):
interface UnderlyingSink<TChunk> {
start?(
controller: WritableStreamDefaultController
): void | Promise<void>;
write?(
chunk: TChunk,
controller: WritableStreamDefaultController
): void | Promise<void>;
close?(): void | Promise<void>;;
abort?(reason?: any): void | Promise<void>;
}
这些属性的解释:
-
.start(controller)在我们调用WritableStream的构造函数后立即调用。如果我们做一些异步操作,我们可以返回一个 Promise。在这个方法中,我们可以准备写入。 -
.write(chunk, controller)当一个新的块准备写入外部接收端时调用。我们可以通过返回一个 Promise 来施加反压,一旦反压消失就会实现。 -
.close()在调用writer.close()后调用,并且所有排队的写入都成功。在这个方法中,我们可以在写入后进行清理。 -
如果调用了
writeStream.abort()或writer.abort(),则会调用.abort(reason)。reason是传递给这些方法的值。
.start()和.write()的参数controller让它们错误 WritableStream。它具有以下类型:
interface WritableStreamDefaultController {
readonly signal: AbortSignal;
error(err?: any): void;
}
-
.signal是一个 AbortSignal,如果我们想在流被中止时中止写入或关闭操作,我们可以监听它。 -
.error(err)错误 WritableStream:它被关闭,并且以后所有与它的交互都会失败,错误值为err。
10.5.1 示例:跟踪一个可读流
在下一个示例中,我们将一个 ReadableStream 管道到一个 WritableStream,以便检查 ReadableStream 如何生成块:
const readableStream = new ReadableStream({
start(controller) {
controller.enqueue('First chunk');
controller.enqueue('Second chunk');
controller.close();
},
});
await readableStream.pipeTo(
new WritableStream({
write(chunk) {
console.log('WRITE ' + JSON.stringify(chunk));
},
close() {
console.log('CLOSE');
},
abort(err) {
console.log('ABORT ' + err);
},
})
);
// Output:
// 'WRITE "First chunk"'
// 'WRITE "Second chunk"'
// 'CLOSE'
10.5.2 示例:收集写入到 WriteStream 的块到一个字符串中
在下一个示例中,我们创建了WriteStream的一个子类,它将所有写入的块收集到一个字符串中。我们可以通过.getString()方法访问该字符串:
class StringWritableStream extends WritableStream {
#string = '';
constructor() {
super({
// We need to access the `this` of `StringWritableStream`.
// Hence the arrow function (and not a method).
write: (chunk) => {
this.#string += chunk;
},
});
}
getString() {
return this.#string;
}
}
const stringStream = new StringWritableStream();
const writer = stringStream.getWriter();
try {
await writer.write('How are');
await writer.write(' you?');
await writer.close();
} finally {
writer.releaseLock()
}
assert.equal(
stringStream.getString(),
'How are you?'
);
这种方法的一个缺点是我们混合了两个 API:WritableStream的 API 和我们新的字符串流 API。另一种选择是委托给 WritableStream 而不是扩展它:
function StringcreateWritableStream() {
let string = '';
return {
stream: new WritableStream({
write(chunk) {
string += chunk;
},
}),
getString() {
return string;
},
};
}
const stringStream = StringcreateWritableStream();
const writer = stringStream.stream.getWriter();
try {
await writer.write('How are');
await writer.write(' you?');
await writer.close();
} finally {
writer.releaseLock()
}
assert.equal(
stringStream.getString(),
'How are you?'
);
这个功能也可以通过类来实现(而不是作为对象的工厂函数)。
10.6 使用 TransformStreams
一个 TransformStream:
-
通过其writable side接收输入,即 WritableStream。
-
然后可能会或可能不会转换这个输入。
-
结果可以通过一个 ReadableStream 来读取,它的可读端。
使用 TransformStreams 最常见的方式是“管道传递”它们:
const transformedStream = readableStream.pipeThrough(transformStream);
.pipeThrough() 将readableStream管道到transformStream的可写端,并返回其可读端。换句话说:我们已经创建了一个新的ReadableStream,它是readableStream的转换版本。
.pipeThrough() 不仅接受 TransformStreams,还接受任何具有以下形式的对象:
interface ReadableWritablePair<RChunk, WChunk> {
readable: ReadableStream<RChunk>;
writable: WritableStream<WChunk>;
}
10.6.1 标准 TransformStreams
Node.js 支持以下标准 TransformStreams:
-
编码(WHATWG 标准) –
TextEncoderStream和TextDecoderStream:-
这些流支持 UTF-8,但也支持许多“旧编码”。
-
一个 Unicode 代码点被编码为多达四个 UTF-8 代码单元(字节)。在字节流中,编码的代码点可能会跨越块。
TextDecoderStream可以正确处理这些情况。 -
大多数 JavaScript 平台都可以使用(
TextEncoderStream,TextDecoderStream)。
-
-
压缩流(W3C 草案社区组报告) –
CompressionStream,DecompressionStream:-
当前支持的压缩格式:
deflate(ZLIB 压缩数据格式),deflate-raw(DEFLATE 算法),gzip(GZIP 文件格式)。 -
在许多 JavaScript 平台上都可以使用(
CompressionStream,DecompressionStream)。
-
10.6.1.1 示例:解码一系列 UTF-8 编码的字节流
在下面的示例中,我们解码了一系列 UTF-8 编码的字节流:
const response = await fetch('https://example.com');
const readableByteStream = response.body;
const readableStream = readableByteStream
.pipeThrough(new TextDecoderStream('utf-8'));
for await (const stringChunk of readableStream) {
console.log(stringChunk);
}
response.body是一个 ReadableByteStream,其块是Uint8Array的实例(TypedArrays)。我们通过TextDecoderStream将该流传输,以获得具有字符串块的流。
请注意,单独翻译每个字节块(例如通过TextDecoder)是行不通的,因为一个 Unicode 代码点在 UTF-8 中被编码为多达四个字节,而这些字节可能不都在同一个块中。
10.6.1.2 示例:创建一个用于标准输入的可读文本流
以下 Node.js 模块记录通过标准输入发送给它的所有内容:
// echo-stdin.mjs
import {Readable} from 'node:stream';
const webStream = Readable.toWeb(process.stdin)
.pipeThrough(new TextDecoderStream('utf-8'));
for await (const chunk of webStream) {
console.log('>>>', chunk);
}
我们可以通过存储在process.stdin中的流访问标准输入(process是一个全局 Node.js 变量)。如果我们不为此流设置编码并通过Readable.toWeb()进行转换,我们将获得一个字节流。我们通过 TextDecoderStream 将其传输,以获得一个文本流。
请注意,我们逐步处理标准输入:一旦另一个块可用,我们就会记录它。换句话说,我们不会等到标准输入完成。当数据要么很大要么只是间歇性发送时,这是很有用的。
10.7 实现自定义 TransformStreams
我们可以通过将 Transformer 对象传递给TransformStream的构造函数来实现自定义 TransformStream。这样的对象具有以下类型(随意略过此类型和其属性的解释;当我们在示例中遇到它们时,它们将再次解释):
interface Transformer<TInChunk, TOutChunk> {
start?(
controller: TransformStreamDefaultController<TOutChunk>
): void | Promise<void>;
transform?(
chunk: TInChunk,
controller: TransformStreamDefaultController<TOutChunk>
): void | Promise<void>;
flush?(
controller: TransformStreamDefaultController<TOutChunk>
): void | Promise<void>;
}
这些属性的解释:
-
.start(controller)在我们调用TransformStream的构造函数之后立即调用。在这里,我们可以在转换开始之前准备好一些东西。 -
.transform(chunk, controller)执行实际的转换。它接收一个输入块,并可以使用其参数controller来排队一个或多个转换后的输出块。它也可以选择不排队任何内容。 -
.flush(controller)在所有输入块成功转换后调用。在这里,我们可以在转换完成后执行清理工作。
这些方法中的每一个都可以返回一个 Promise,并且在 Promise 解决之前不会采取进一步的步骤。如果我们想要执行一些异步操作,这是很有用的。
参数controller具有以下类型:
interface TransformStreamDefaultController<TOutChunk> {
enqueue(chunk?: TOutChunk): void;
readonly desiredSize: number | null;
terminate(): void;
error(err?: any): void;
}
-
.enqueue(chunk)将chunk添加到 TransformStream 的可读端(输出)。 -
.desiredSize返回可读端(输出)的 TransformStream 内部队列的期望大小。 -
.terminate()关闭可读端(输出)并错误可写端(输入)的 TransformStream。如果转换器对可写端(输入)的剩余块不感兴趣并希望跳过它们,则可以使用它。 -
.error(err)错误 TransformStream:以后所有与它的交互都将以错误值err失败。
TransformStream 中的背压如何?该类将背压从其可读端(输出)传播到其可写端(输入)。假设转换不会改变数据量太多。因此,Transform 可以忽略背压。但是,可以通过transformStreamDefaultController.desiredSize检测到它,并通过从transformer.transform()返回一个 Promise 来传播它。
10.7.1 示例:将任意块的流转换为行流
TransformStream的以下子类将流转换为每个块都包含一行文本的流。也就是说,除了最后一个块可能以行尾(EOL)字符串结束之外,每个块都以行尾(EOL)字符串结束:Unix(包括 macOS)上为'\n',Windows 上为'\r\n'。
class ChunksToLinesTransformer {
#previous = '';
transform(chunk, controller) {
let startSearch = this.#previous.length;
this.#previous += chunk;
while (true) {
// Works for EOL === '\n' and EOL === '\r\n'
const eolIndex = this.#previous.indexOf('\n', startSearch);
if (eolIndex < 0) break;
// Line includes the EOL
const line = this.#previous.slice(0, eolIndex+1);
controller.enqueue(line);
this.#previous = this.#previous.slice(eolIndex+1);
startSearch = 0;
}
}
flush(controller) {
// Clean up and enqueue any text we’re still holding on to
if (this.#previous.length > 0) {
controller.enqueue(this.#previous);
}
}
}
class ChunksToLinesStream extends TransformStream {
constructor() {
super(new ChunksToLinesTransformer());
}
}
const stream = new ReadableStream({
async start(controller) {
controller.enqueue('multiple\nlines of\ntext');
controller.close();
},
});
const transformStream = new ChunksToLinesStream();
const transformed = stream.pipeThrough(transformStream);
for await (const line of transformed) {
console.log('>>>', JSON.stringify(line));
}
// Output:
// '>>> "multiple\n"'
// '>>> "lines of\n"'
// '>>> "text"'
请注意,Deno 的内置TextLineStream提供类似的功能。
提示:我们也可以通过异步生成器进行这种转换。它将异步迭代 ReadableStream 并返回一个包含行的异步可迭代对象。其实现在§9.4“通过异步生成器转换可读流”中显示。
10.7.2 提示:异步生成器也非常适合转换流
由于 ReadableStreams 是异步可迭代的,我们可以使用异步生成器来转换它们。这导致非常优雅的代码:
const stream = new ReadableStream({
async start(controller) {
controller.enqueue('one');
controller.enqueue('two');
controller.enqueue('three');
controller.close();
},
});
async function* prefixChunks(prefix, asyncIterable) {
for await (const chunk of asyncIterable) {
yield '> ' + chunk;
}
}
const transformedAsyncIterable = prefixChunks('> ', stream);
for await (const transformedChunk of transformedAsyncIterable) {
console.log(transformedChunk);
}
// Output:
// '> one'
// '> two'
// '> three'
10.8 仔细观察背压
让我们仔细观察背压。考虑以下管道链:
rs.pipeThrough(ts).pipeTo(ws);
rs是一个 ReadableStream,ts是一个 TransformStream,ws是一个 WritableStream。这些是由前一个表达式创建的连接(.pipeThrough使用.pipeTo将rs连接到ts的可写端):
rs -pipeTo-> ts{writable,readable} -pipeTo-> ws
观察:
-
rs的基础源可以被视为在rs之前的管道链成员。 -
ws的基础接收器可以被视为在ws之后的管道链成员。 -
每个流都有一个内部缓冲区:ReadableStreams 在其基础源之后进行缓冲。WritableStreams 在其基础接收器之前进行缓冲。
假设ws的基础接收器速度慢,ws的缓冲区最终满了。然后发生以下步骤:
-
ws发出满的信号。 -
pipeTo停止从ts.readable读取。 -
ts.readable发出满的信号。 -
ts停止从ts.writable移动块到ts.readable。 -
ts.writable发出满的信号。 -
pipeTo停止从rs读取。 -
rs向其基础源发出满的信号。 -
基础源暂停。
这个例子说明我们需要两种功能:
-
接收数据的实体需要能够发出背压信号。
-
发送数据的实体需要对信号做出反应,施加背压。
让我们探索这些功能在 web 流 API 中是如何实现的。
10.8.1 发出背压
背压由接收数据的实体发出信号。Web 流有两个这样的实体:
-
WritableStream 通过 Writer 方法
.write()接收数据。 -
当其基础源调用 ReadableStreamDefaultController 方法
.enqueue()时,ReadableStream 接收数据。
在这两种情况下,输入都通过队列进行缓冲。施加背压的信号是队列已满。让我们看看如何检测到这一点。
这些是队列的位置:
-
一个 WritableStream 的队列在 WritableStreamDefaultController 中内部存储(参见 web 流标准)。
-
一个 ReadableStream 的队列在 ReadableStreamDefaultController 中内部存储(参见 web 流标准)。
队列的期望大小是一个数字,表示队列中还有多少空间:
-
如果队列中仍有空间,则为正。
-
如果队列已达到其最大大小,则为零。
-
如果队列已超过其最大大小,则为负。
因此,如果期望的大小为零或更少,我们必须施加背压。它可以通过包含队列的对象的 getter.desiredSize获得。
期望的大小是如何计算的?通过指定所谓的排队策略的对象。ReadableStream和WritableStream具有默认的排队策略,可以通过它们的构造函数的可选参数进行覆盖。接口QueuingStrategy有两个属性:
-
方法
.size(chunk)返回chunk的大小。- 队列的当前大小是它包含的块的大小之和。
-
属性
.highWaterMark指定队列的最大大小。
队列的期望大小是高水位标记减去队列的当前大小。
10.8.2 对背压的反应
发送数据的实体需要对信号背压做出反应,通过施加背压。
10.8.2.1 通过 Writer 写入 WritableStream 的代码
-
我们可以在
writer.ready中等待 Promise。在等待期间,我们被阻塞,期望的背压得到了实现。一旦队列中有空间,Promise 就会被实现。当writer.desiredSize的值大于零时,实现会被触发。 -
或者,我们可以等待
writer.write()返回的 Promise。如果我们这样做,队列甚至不会被填满。
如果我们愿意,我们还可以根据writer.desiredSize来确定我们的块的大小。
10.8.2.2 ReadableStream 的底层源
可以传递给 ReadableStream 的底层源对象包装了外部源。在某种程度上,它也是管道链的成员;在其 ReadableStream 之前的成员。
-
只有在队列中有空间时,才会要求底层拉取源提供新数据。在没有空间时,会自动施加背压,因为没有数据被拉取。
-
在入队后,底层推送源应检查
controller.desiredSize:如果为零或更少,则应通过暂停其外部源来施加背压。
10.8.2.3 WritableStream 的底层接收端
可以传递给 WritableStream 的底层接收端对象包装了外部接收端。在某种程度上,它也是管道链的成员;在其 WritableStream 之后的成员。
每个外部接收端以不同的方式(在某些情况下根本不)信号背压。底层接收端可以通过从方法.write()返回一个被实现的 Promise 来施加背压,一旦写入完成。在web 流标准中有一个例子,演示了这是如何工作的。
10.8.2.4 一个 transformStream(.writable → .readable)
TransformStream 通过为前者实现底层接收端和为后者实现底层源,将其可写端连接到其可读端。它具有一个内部插槽.[[backpressure]],指示内部背压当前是否处于活动状态。
-
可写端的底层接收器的
.write()方法会异步等待,直到没有内部背压,然后将另一个块提供给 TransformStream 的转换器(web streams 标准:TransformStreamDefaultSinkWriteAlgorithm)。然后转换器可以通过其 TransformStreamDefaultController 加入一些内容。请注意,.write()返回一个 Promise,在方法完成时会被满足。在此之前,WriteStream 通过其队列缓冲传入的写请求。因此,可写端的背压通过该队列及其期望的大小来表示。 -
如果通过 TransformStreamDefaultController 将一个块加入队列,并且可读端的队列变满了,TransformStream 的背压就会被激活(web streams 标准:
TransformStreamDefaultControllerEnqueue)。 -
如果从读取器中读取了一些内容,
ReadableStream的背压可能会被取消(web streams 标准:ReadableStreamDefaultReaderRead):-
如果队列中现在有空间,可能是时候调用底层源的
.pull()了(web streams 标准:.[[PullSteps]])。 -
可读端的底层源的
.pull()会取消背压(web streams 标准:TransformStreamDefaultSourcePullAlgorithm)。
-
10.8.2.5 .pipeTo()(ReadableStream → WritableStream)
.pipeTo()通过读取器从 ReadableStream 读取块,并通过写入器将它们写入 WritableStream。当writer.desiredSize为零或更小时,它会暂停(web streams 标准:ReadableStreamPipeTo的第 15 步)。
10.9 字节流
到目前为止,我们只使用过文本流,流的块是字符串。但是 web streams API 也支持字节流,用于二进制数据,其中块是 Uint8Arrays(TypedArrays):
-
ReadableStream有一个特殊的'bytes'模式。 -
WritableStream本身不关心块是字符串还是 Uint8Arrays。因此,实例是文本流还是字节流取决于底层接收器可以处理什么类型的块。 -
TransformStream可以处理什么类型的块也取决于其 Transformer。
接下来,我们将学习如何创建可读的字节流。
10.9.1 可读的字节流
ReadableStream构造函数创建的流的类型取决于可选的属性.type和可选的第一个参数underlyingSource:
-
如果
.type被省略或没有提供底层源,则新实例是一个文本流。 -
如果
.type是字符串'bytes',则新实例是一个字节流:const readableByteStream = new ReadableStream({ type: 'bytes', async start() { /*...*/ } // ... });
如果一个 ReadableStream 处于'bytes'模式,会发生什么变化?
在默认模式下,底层源可以返回任何类型的块。在字节模式下,块必须是 ArrayBufferViews,即 TypedArrays(例如 Uint8Arrays)或 DataViews。
此外,可读的字节流可以创建两种读取器:
-
.getReader()返回一个ReadableStreamDefaultReader的实例。 -
.getReader({mode: 'byob'})返回一个ReadableStreamBYOBReader的实例。
“BYOB” 代表 “Bring Your Own Buffer”,意味着我们可以传递一个缓冲区(ArrayBufferView)给 reader.read()。之后,该 ArrayBufferView 将被分离并且不再可用。但是.read() 返回其数据在一个新的 ArrayBufferView 中,该 ArrayBufferView 具有相同的类型并访问相同的 ArrayBuffer 的相同区域。
此外,可读的字节流具有不同的控制器:它们是ReadableByteStreamController的实例(而不是ReadableStreamDefaultController)。除了强制底层源将 ArrayBufferViews(TypedArrays 或 DataViews)入队之外,它还通过其属性.byobRequest支持 ReadableStreamBYOBReaders。底层源将其数据写入存储在此属性中的 BYOBRequest。Web 流标准在其“创建流的示例”部分中有两个使用.byobRequest的示例。
10.9.2 示例:填充随机数据的无限可读的字节流
在下一个示例中,创建一个无限可读的字节流,用随机数据填充其块(灵感来自:example4.mjs in “在 Node.js 中实现 Web 流 API”)。
import {promisify} from 'node:util';
import {randomFill} from 'node:crypto';
const asyncRandomFill = promisify(randomFill);
const readableByteStream = new ReadableStream({
type: 'bytes',
async pull(controller) {
const byobRequest = controller.byobRequest;
await asyncRandomFill(byobRequest.view);
byobRequest.respond(byobRequest.view.byteLength);
},
});
const reader = readableByteStream.getReader({mode: 'byob'});
const buffer = new Uint8Array(10); // (A)
const firstChunk = await reader.read(buffer); // (B)
console.log(firstChunk);
由于readableByteStream是无限的,我们无法循环读取它。这就是为什么我们只读取它的第一个块(B 行)。
我们在 A 行创建的缓冲区在 B 行之后被传输,因此无法读取。
10.9.3 示例:压缩可读的字节流
在下面的示例中,我们创建一个可读的字节流,并将其通过一个将其压缩为 GZIP 格式的流:
const readableByteStream = new ReadableStream({
type: 'bytes',
start(controller) {
// 256 zeros
controller.enqueue(new Uint8Array(256));
controller.close();
},
});
const transformedStream = readableByteStream.pipeThrough(
new CompressionStream('gzip'));
await logChunks(transformedStream);
async function logChunks(readableByteStream) {
const reader = readableByteStream.getReader();
try {
while (true) {
const {done, value} = await reader.read();
if (done) break;
console.log(value);
}
} finally {
reader.releaseLock();
}
}
10.9.4 示例:通过fetch()读取网页
fetch()的结果解析为一个响应对象,其属性.body是一个可读的字节流。我们通过TextDecoderStream将该字节流转换为文本流:
const response = await fetch('https://example.com');
const readableByteStream = response.body;
const readableStream = readableByteStream.pipeThrough(
new TextDecoderStream('utf-8'));
for await (const stringChunk of readableStream) {
console.log(stringChunk);
}
10.10 Node.js 特定的辅助函数
Node.js 是唯一支持以下辅助函数的 Web 平台,它称之为实用消费者:
import {
arrayBuffer,
blob,
buffer,
json,
text,
} from 'node:stream/consumers';
这些函数将 Web ReadableStreams、Node.js Readables 和 AsyncIterators 转换为被满足的 Promise:
-
ArrayBuffers(
arrayBuffer()) -
Blobs(
blob()) -
Node.js 缓冲区(
buffer()) -
JSON 对象(
json()) -
字符串(
text())
假定二进制数据为 UTF-8 编码:
import * as streamConsumers from 'node:stream/consumers';
const readableByteStream = new ReadableStream({
type: 'bytes',
start(controller) {
// TextEncoder converts strings to UTF-8 encoded Uint8Arrays
const encoder = new TextEncoder();
const view = encoder.encode('"😀"');
assert.deepEqual(
view,
Uint8Array.of(34, 240, 159, 152, 128, 34)
);
controller.enqueue(view);
controller.close();
},
});
const jsonData = await streamConsumers.json(readableByteStream);
assert.equal(jsonData, '😀');
字符串流按预期工作:
import * as streamConsumers from 'node:stream/consumers';
const readableByteStream = new ReadableStream({
start(controller) {
controller.enqueue('"😀"');
controller.close();
},
});
const jsonData = await streamConsumers.json(readableByteStream);
assert.equal(jsonData, '😀');
10.11 进一步阅读
本节提到的所有材料都是本章的来源。
本章不涵盖 Web 流 API 的每个方面。您可以在此处找到更多信息:
-
“WHATWG 流标准” by Adam Rice, Domenic Denicola, Mattias Buelens, and 吉野剛史 (Takeshi Yoshino)
-
“Web Streams API” in Node.js 文档
更多材料:
-
Web 流 API:
-
“在 Node.js 中实现 Web 流 API” by James M. Snell
-
“流 API” 在 MDN 上
-
“流-权威指南” by Thomas Steiner
-
-
背压:
-
“Node.js 流中的背压” by Vladimir Topolev
-
“流中的背压” in Node.js 文档
-
-
Unicode(代码点,UTF-8,UTF-16 等):“Unicode 简介”章节 in “JavaScript for impatient programmers”
-
“异步迭代”章节 in “JavaScript for impatient programmers”
-
“Typed Arrays:处理二进制数据”章节 in “JavaScript for impatient programmers”
评论
十一、流配方
exploringjs.com/nodejs-shell-scripting/ch_stream-recipes.html
-
11.1 写入标准输出(stdout)
-
11.1.1 通过
console.log()写入 stdout -
11.1.2 通过 Node.js 流写入 stdout
-
11.1.3 通过 Web 流写入 stdout
-
-
11.2 写入标准错误(stderr)
-
11.3 从标准输入(stdin)读取
-
11.3.1 通过 Node.js 流从 stdin 读取
-
11.3.2 通过 Web 流从 stdin 读取
-
11.3.3 通过模块
'node:readline'从 stdin 读取
-
-
11.4 Node.js 流配方
-
11.5 Web 流配方
11.1 写入标准输出(stdout)
这是写入 stdout 的三个选项:
-
我们可以通过
console.log()写入它。 -
我们可以通过 Node.js 流写入它。
-
我们可以通过 Web 流写入它。
11.1.1 通过console.log()写入 stdout
console.log(format, ...args)写入 stdout 并始终附加换行符'\n'(即使在 Windows 上也是如此)。第一个参数可以包含占位符,这些占位符的解释方式与util.format()相同:
console.log('String: %s Number: %d Percent: %%', 'abc', 123);
const obj = {one: 1, two: 2};
console.log('JSON: %j Object: %o', obj, obj);
// Output:
// 'String: abc Number: 123 Percent: %'
// 'JSON: {"one":1,"two":2} Object: { one: 1, two: 2 }'
第一个参数之后的所有参数始终显示在输出中,即使没有足够的占位符。
11.1.2 通过 Node.js 流写入 stdout
process.stdout是stream.Readable的一个实例。这意味着我们可以像使用其他 Node.js 流一样使用它-例如:
process.stdout.write('two');
process.stdout.write(' words');
process.stdout.write('\n');
前面的代码等同于:
console.log('two words');
请注意,这种情况下末尾没有换行符,因为console.log()总是会添加一个。
如果我们使用.write()来处理大量数据,我们应该考虑回压,如§9.5.2.1“writable.write(chunk)”中所解释的那样。
以下配方适用于process.stdout:§11.4“Node.js 流配方”。
11.1.3 通过 Web 流写入 stdout
我们可以将process.stdout转换为 Web 流并写入其中:
import {Writable} from 'node:stream';
const webOut = Writable.toWeb(process.stdout);
const writer = webOut.getWriter();
try {
await writer.write('First line\n');
await writer.write('Second line\n');
await writer.close();
} finally {
writer.releaseLock()
}
以下配方适用于webOut:§11.5“Web 流配方”。
11.2 写入标准错误(stderr)
写入 stderr 的工作方式与写入 stdout 类似:
-
我们可以通过
console.error()写入它。 -
我们可以通过 Node.js 流写入它。
-
我们可以通过 Web 流写入它。
有关更多信息,请参阅前一节。
11.3 从标准输入(stdin)读取
这些是从 stdin 读取的选项:
-
我们可以通过 Node.js 流从中读取。
-
我们可以通过 Web 流从中读取。
-
我们可以使用模块
'node:readline'。
11.3.1 通过 Node.js 流从 stdin 读取
process.stdin是stream.Writable的一个实例。这意味着我们可以像使用其他 Node.js 流一样使用它:
// Switch to text mode (otherwise we get chunks of binary data)
process.stdin.setEncoding('utf-8');
for await (const chunk of process.stdin) {
console.log('>', chunk);
}
以下配方适用于webIn:§11.4“Node.js 流配方”。
11.3.2 通过 Web 流从 stdin 读取
我们首先必须将process.stdin转换为 Web 流:
import {Readable} from 'node:stream';
// Switch to text mode (otherwise we get chunks of binary data)
process.stdin.setEncoding('utf-8');
const webIn = Readable.toWeb(process.stdin);
for await (const chunk of webIn) {
console.log('>', chunk);
}
以下配方适用于webIn:§11.5“Web 流配方”。
11.3.3 通过模块'node:readline'从 stdin 读取
内置模块'node:readline'允许我们提示用户以交互方式输入信息-例如:
import * as fs from 'node:fs';
import * as readline from 'node:readline/promises';
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
const filePath = await rl.question('Please enter a file path: ');
fs.writeFileSync(filePath, 'Hi!', {encoding: 'utf-8'})
rl.close();
有关模块'node:readline'的更多信息,请参见:
-
§9.3.3“通过模块’node:readlines’从可读流中读取行”
-
官方文档。
11.4 Node.js 流配方
可读流:
-
§9.3.1.2“
Readable.from(): 从可迭代对象创建可读流” -
§9.3.2“通过
for-await-of从可读流中读取块”- §9.3.2.1“在字符串中收集可读流的内容”
-
§9.3.3“通过模块’node:readlines’从可读流中读取行”
-
§9.4“通过异步生成器转换可读流”
- §9.4.1“在异步可迭代对象中从块转换为编号行”
可写流:
-
§9.5.2“写入可写流”
-
§9.5.2.2“通过
stream.pipeline()将可读流传输到可写流”
11.5 网络流配方
从中创建一个 ReadableStream:
-
字符串:§10.3.1“实现基础源的第一个示例”
-
可迭代对象:§10.3.2.2“示例:从拉取源创建一个 ReadableStream”
从 ReadableStream 中读取:
-
§10.2.1“通过读取器消耗 ReadableStreams”
-
§10.2.2“通过异步迭代消耗 ReadableStreams”
- §10.2.2.2“示例:组装包含 ReadableStream 内容的字符串”
-
§10.2.3“将 ReadableStreams 传输到 WritableStreams”
转换 ReadableStreams:
-
§10.6“使用 TransformStreams”
-
§10.7.2“提示:异步生成器也非常适合转换流”
-
§10.7.1“示例:将任意块的流转换为行流”
使用 WritableStreams:
-
§10.4“写入可写流”
-
§10.5.2“示例:在字符串中收集写入到 WriteStream 的块”
评论
十二、在子进程中运行 shell 命令
原文:
exploringjs.com/nodejs-shell-scripting/ch_nodejs-child-process.html译者:飞龙
协议:CC BY-NC-SA 4.0
-
12.1 本章概述](ch_nodejs-child-process.html#overview-of-this-chapter)
-
12.1.1 Windows vs. Unix
-
12.1.2 我们在示例中经常使用的功能
-
-
12.2 异步生成进程:
spawn()-
12.2.1
spawn()的工作原理 -
12.2.2 何时执行 shell 命令?](ch_nodejs-child-process.html#when-is-the-shell-command-executed)
-
12.2.3 仅命令模式 vs. 参数模式](ch_nodejs-child-process.html#spawn-argument-modes)
-
12.2.4 向子进程的 stdin 发送数据
-
12.2.5 手动进行管道传输](ch_nodejs-child-process.html#piping-manually)
-
12.2.6 处理不成功的退出(包括错误)
-
12.2.7 等待子进程退出](ch_nodejs-child-process.html#waiting-for-the-exit-of-a-child-process)
-
12.2.8 终止子进程](ch_nodejs-child-process.html#terminating-child-processes)
-
-
12.3 同步生成进程:
spawnSync()-
12.3.1 何时执行 shell 命令?](ch_nodejs-child-process.html#when-is-the-shell-command-executed-1)
-
12.3.2 从 stdout 读取](ch_nodejs-child-process.html#reading-from-stdout)
-
12.3.3 向子进程的 stdin 发送数据
-
12.3.4 处理不成功的退出(包括错误)
-
-
12.4 基于
spawn()的异步辅助函数-
12.4.1
exec() -
12.4.2
execFile()
-
-
12.5 基于
spawnAsync()的同步辅助函数-
12.5.1
execSync() -
12.5.2
execFileSync()
-
-
12.6 有用的库](ch_nodejs-child-process.html#useful-libraries)
-
12.6.1 tinysh:用于生成 shell 命令的辅助程序
-
12.6.2 node-powershell:通过 Node.js 执行 Windows PowerShell 命令
-
-
12.7 在模块
'node:child_process'的功能之间进行选择
在本章中,我们将探讨如何通过模块'node:child_process'从 Node.js 执行 shell 命令。
12.1 本章概述
模块'node:child_process'有一个用于执行 shell 命令(在生成的子进程中)的函数,有两个版本:
-
一个异步版本的
spawn()。 -
一个同步版本的
spawnSync()。
我们将首先探讨spawn(),然后是spawnSync()。最后,我们将看一下基于它们并且相对类似的以下函数:
-
基于
spawn():-
exec() -
execFile()
-
-
基于
spawnSync():-
execSync() -
execFileSync()
-
12.1.1 Windows vs. Unix
本章中显示的代码在 Unix 上运行,但我也在 Windows 上进行了测试-其中大部分代码需要进行轻微更改(例如以'\r\n'而不是'\n'结尾)。
12.1.2 我们在示例中经常使用的功能
以下功能在示例中经常出现。这就是为什么在这里解释一次:
-
断言:对于原始值使用
assert.equal(),对于对象使用assert.deepEqual()。示例中从未显示必要的导入:import * as assert from 'node:assert/strict'; -
函数
Readable.toWeb()将 Node 的原生stream.Readable转换为 web 流(ReadableStream的实例)。这在§10“在 Node.js 上使用 web 流”中有解释。示例中始终导入Readable。 -
异步函数
readableStreamToString()会消耗可读的 web 流并返回一个字符串(包装在 Promise 中)。这在 web 流章节中有解释。假定这个函数在示例中是可用的。
12.2 异步生成进程:spawn()
12.2.1 spawn()的工作原理
spawn(
command: string,
args?: Array<string>,
options?: Object
): ChildProcess
spawn() 异步地在新进程中执行命令:该进程与 Node 的主 JavaScript 进程并行运行,我们可以通过各种方式与其通信(通常通过流)。
接下来,有关spawn()的参数和结果的文档。如果您喜欢通过示例学习,可以跳过该内容,继续阅读后面的小节。
12.2.1.1 参数:command
command是一个包含 shell 命令的字符串。有两种使用该参数的模式:
-
仅命令模式:省略
args,command包含整个 shell 命令。我们甚至可以使用 shell 功能,如在多个可执行文件之间进行管道传输,将 I/O 重定向到文件,变量和通配符。-
options.shell必须为true,因为我们需要一个 shell 来处理 shell 功能。
-
-
参数模式:
command仅包含命令的名称,args包含其参数。-
如果
options.shell为true,则参数中的许多元字符会被解释,并且通配符和变量名称等功能会起作用。 -
如果
options.shell为false,则字符串会直接使用,我们不必转义元字符。
-
这两种模式在本章后面进行了演示。
12.2.1.2 参数:options
以下options最有趣:
-
.shell: boolean|string(默认值:false)是否应使用 shell 来执行命令?
-
在 Windows 上,此选项几乎总是应为
true。例如,否则无法执行.bat和.cmd文件。 -
在 Unix 上,只有核心 shell 功能(例如管道,I/O 重定向,文件名通配符和变量)在
.shell为false时不可用。 -
如果
.shell为true,我们必须小心处理用户输入并对其进行清理,因为很容易执行任意代码。如果我们想将其用作非元字符,则还必须转义元字符。 -
我们还可以将
.shell设置为 shell 可执行文件的路径。然后 Node.js 将使用该可执行文件来执行命令。如果我们将.shell设置为true,Node.js 将使用:-
Unix:
'/bin/sh' -
Windows:
process.env.ComSpec
-
-
-
.cwd: string | URL指定在执行命令时要使用的当前工作目录(CWD)。
-
.stdio: Array<string|Stream>|string配置标准 I/O 的设置方式。下面会有解释。
-
.env: Object(默认值:process.env)让我们为子进程指定 shell 变量。提示:
-
查看
process.env(例如在 Node.js REPL 中)以查看存在哪些变量。 -
我们可以使用扩展运算符来非破坏性地覆盖现有变量 - 或者如果尚不存在,则创建它:
{env: {...process.env, MY_VAR: 'Hi!'}}
-
-
.signal: AbortSignal如果我们创建了一个 AbortController
ac,我们可以将ac.signal传递给spawn(),并通过ac.abort()中止子进程。这在本章后面有演示。 -
.timeout: number如果子进程的执行时间超过
.timeout毫秒,则会被终止。
12.2.1.3 options.stdio
子进程的每个标准 I/O 流都有一个数字 ID,称为文件描述符:
-
标准输入(stdin)的文件描述符为 0。
-
标准输出(stdout)的文件描述符为 1。
-
标准错误(stderr)的文件描述符为 2。
可能会有更多的文件描述符,但这很少见。
options.stdio配置子进程的流是否以及如何被管道连接到父进程的流。它可以是一个数组,其中每个元素配置等于其索引的文件描述符。可以使用以下值作为数组元素:
-
'pipe':-
索引 0:将
childProcess.stdin管道连接到子进程的 stdin。请注意,尽管其名称如此,但前者是属于父进程的流。 -
索引 1:将子进程的 stdout 管道连接到
childProcess.stdout。 -
索引 2:将子进程的 stderr 管道连接到
childProcess.stderr。
-
-
'ignore':忽略子进程的流。 -
'inherit':将子进程的流管道连接到父进程的相应流。- 例如,如果我们希望子进程的 stderr 被记录到控制台,我们可以在索引 2 处使用
'inherit'。
- 例如,如果我们希望子进程的 stderr 被记录到控制台,我们可以在索引 2 处使用
-
原生 Node.js 流:管道到该流或从该流。
-
还支持其他值,但这超出了本章的范围。
除了通过数组指定options.stdio之外,我们还可以缩写:
-
'pipe'等同于['pipe', 'pipe', 'pipe'](options.stdio的默认值)。 -
'ignore'等同于['ignore', 'ignore', 'ignore']。 -
'inherit'等同于['inherit', 'inherit', 'inherit']。
12.2.1.4 结果:ChildProcess的实例
spawn()返回ChildProcess的实例。
有趣的数据属性:
-
.exitCode: number | null包含子进程退出时的代码:
-
0(零)表示正常退出。
-
大于零的数字表示发生了错误。
-
null表示进程尚未退出。
-
-
.signalCode: string | null子进程被杀死的 POSIX 信号,或者如果没有被杀死则为
null。有关更多信息,请参阅下面的.kill()方法的描述。 -
流:根据标准 I/O 的配置方式(请参阅前面的小节),以下流变得可用:
-
.stdin -
.stdout -
.stderr
-
-
.pid: number | undefined子进程的进程标识符(PID)。如果生成失败,
.pid为undefined。在调用spawn()后立即可用此值。
有趣的方法:
-
.kill(signalCode?: number | string = 'SIGTERM'): boolean向子进程发送 POSIX 信号(通常导致进程终止):
-
signal的 man 页面包含值的列表。 -
Windows 不支持信号,但 Node.js 模拟了其中一些 - 例如:
SIGINT,SIGTERM和SIGKILL。有关更多信息,请参阅Node.js 文档。
此方法在本章后面进行了演示。
-
有趣的事件:
-
.on('exit', (exitCode: number|null, signalCode: string|null) => {})此事件在子进程结束后发出:
-
回调参数为我们提供了退出代码或信号代码:其中一个始终为非空。
-
由于多个进程可能共享相同的流,因此其标准 I/O 流可能仍然打开。事件
'close'在子进程退出后通知我们所有 stdio 流都已关闭。
-
-
.on('error', (err: Error) => {})如果进程无法被生成(请参阅示例后面)或子进程无法被杀死,则最常见地发出此事件。在此事件之后可能会或可能不会发出
'exit'事件。
我们稍后将看到如何将事件转换为可以等待的 Promise。
12.2.2 shell 命令何时执行?
在使用异步spawn()时,命令的子进程是异步启动的。以下代码演示了这一点:
import {spawn} from 'node:child_process';
spawn(
'echo', ['Command starts'],
{
stdio: 'inherit',
shell: true,
}
);
console.log('After spawn()');
这是输出:
After spawn()
Command starts
12.2.3 仅命令模式 vs. 参数模式
在本节中,我们以两种方式指定相同的命令调用:
-
仅命令模式:我们通过第一个参数
command提供整个调用。 -
参数模式:我们通过第一个参数
command提供命令,通过第二个参数args提供参数。
12.2.3.1 仅命令模式
import {Readable} from 'node:stream';
import {spawn} from 'node:child_process';
const childProcess = spawn(
'echo "Hello, how are you?"',
{
shell: true, // (A)
stdio: ['ignore', 'pipe', 'inherit'], // (B)
}
);
const stdout = Readable.toWeb(
childProcess.stdout.setEncoding('utf-8'));
// Result on Unix
assert.equal(
await readableStreamToString(stdout),
'Hello, how are you?\n' // (C)
);
// Result on Windows: '"Hello, how are you?"\r\n'
每个带参数的仅命令生成都需要.shell为true(A 行)-即使它像这个这么简单。
在 B 行,我们告诉spawn()如何处理标准 I/O:
-
忽略标准输入。
-
将子进程的标准输出管道到
childProcess.stdout(属于父进程的流)。 -
将子进程的标准错误输出管道到父进程的标准错误输出。
在这种情况下,我们只对子进程的输出感兴趣。因此,一旦我们处理了输出,我们就完成了。在其他情况下,我们可能需要等到子进程退出。如何做到这一点,稍后会有演示。
在仅命令模式下,我们看到 shell 的更多特殊之处 - 例如,Windows 命令 shell 输出包括双引号(最后一行)。
12.2.3.2 参数模式
import {Readable} from 'node:stream';
import {spawn} from 'node:child_process';
const childProcess = spawn(
'echo', ['Hello, how are you?'],
{
shell: true,
stdio: ['ignore', 'pipe', 'inherit'],
}
);
const stdout = Readable.toWeb(
childProcess.stdout.setEncoding('utf-8'));
// Result on Unix
assert.equal(
await readableStreamToString(stdout),
'Hello, how are you?\n'
);
// Result on Windows: 'Hello, how are you?\r\n'
12.2.3.3 args中的元字符
让我们探讨一下如果args中有元字符会发生什么:
import {Readable} from 'node:stream';
import {spawn} from 'node:child_process';
async function echoUser({shell, args}) {
const childProcess = spawn(
`echo`, args,
{
stdio: ['ignore', 'pipe', 'inherit'],
shell,
}
);
const stdout = Readable.toWeb(
childProcess.stdout.setEncoding('utf-8'));
return readableStreamToString(stdout);
}
// Results on Unix
assert.equal(
await echoUser({shell: false, args: ['$USER']}), // (A)
'$USER\n'
);
assert.equal(
await echoUser({shell: true, args: ['$USER']}), // (B)
'rauschma\n'
);
assert.equal(
await echoUser({shell: true, args: [String.raw`\$USER`]}), // (C)
'$USER\n'
);
-
如果我们不使用 shell,例如美元符号(
$)等元字符没有效果(A 行)。 -
在 shell 中,
$USER被解释为一个变量(B 行)。 -
如果我们不想要这个,我们必须通过反斜杠转义美元符号(C 行)。
其他元字符(如星号(*))也会产生类似的效果。
这是 Unix shell 元字符的两个例子。Windows shell 有它们自己的元字符和它们自己的转义方式。
12.2.3.4 一个更复杂的 shell 命令
让我们使用更多的 shell 特性(这需要仅命令模式):
import {Readable} from 'node:stream';
import {spawn} from 'node:child_process';
import {EOL} from 'node:os';
const childProcess = spawn(
`(echo cherry && echo apple && echo banana) | sort`,
{
stdio: ['ignore', 'pipe', 'inherit'],
shell: true,
}
);
const stdout = Readable.toWeb(
childProcess.stdout.setEncoding('utf-8'));
assert.equal(
await readableStreamToString(stdout),
'apple\nbanana\ncherry\n'
);
12.2.4 将数据发送到子进程的标准输入
到目前为止,我们只读取了子进程的标准输出。但是我们也可以将数据发送到标准输入:
import {Readable, Writable} from 'node:stream';
import {spawn} from 'node:child_process';
const childProcess = spawn(
`sort`, // (A)
{
stdio: ['pipe', 'pipe', 'inherit'],
}
);
const stdin = Writable.toWeb(childProcess.stdin); // (B)
const writer = stdin.getWriter(); // (C)
try {
await writer.write('Cherry\n');
await writer.write('Apple\n');
await writer.write('Banana\n');
} finally {
writer.close();
}
const stdout = Readable.toWeb(
childProcess.stdout.setEncoding('utf-8'));
assert.equal(
await readableStreamToString(stdout),
'Apple\nBanana\nCherry\n'
);
我们使用 shell 命令sort(A 行)来为我们对文本行进行排序。
在 B 行,我们使用Writable.toWeb()将本机 Node.js 流转换为网络流(更多信息,请参见§10“在 Node.js 上使用网络流”)。
如何通过写入器(C 行)向 WritableStream 写入也在网络流章节中有解释。
12.2.5 手动进行管道传输
我们之前让 shell 执行以下命令:
(echo cherry && echo apple && echo banana) | sort
在下面的例子中,我们手动进行管道传输,从 echo(A 行)到 sorting(B 行):
import {Readable, Writable} from 'node:stream';
import {spawn} from 'node:child_process';
const echo = spawn( // (A)
`echo cherry && echo apple && echo banana`,
{
stdio: ['ignore', 'pipe', 'inherit'],
shell: true,
}
);
const sort = spawn( // (B)
`sort`,
{
stdio: ['pipe', 'pipe', 'inherit'],
shell: true,
}
);
//==== Transferring chunks from echo.stdout to sort.stdin ====
const echoOut = Readable.toWeb(
echo.stdout.setEncoding('utf-8'));
const sortIn = Writable.toWeb(sort.stdin);
const sortInWriter = sortIn.getWriter();
try {
for await (const chunk of echoOut) { // (C)
await sortInWriter.write(chunk);
}
} finally {
sortInWriter.close();
}
//==== Reading sort.stdout ====
const sortOut = Readable.toWeb(
sort.stdout.setEncoding('utf-8'));
assert.equal(
await readableStreamToString(sortOut),
'apple\nbanana\ncherry\n'
);
例如echoOut这样的 ReadableStreams 是异步可迭代的。这就是为什么我们可以使用for-await-of循环来读取它们的chunks(流数据的片段)。更多信息,请参见§10“在 Node.js 上使用网络流”。
12.2.6 处理不成功的退出(包括错误)
有三种主要的不成功的退出方式:
-
子进程无法生成。
-
Shell 中发生了错误。
-
一个进程被终止。
12.2.6.1 子进程无法生成
以下代码演示了如果子进程无法生成会发生什么。在这种情况下,原因是 shell 的路径没有指向可执行文件(A 行)。
import {spawn} from 'node:child_process';
const childProcess = spawn(
'echo hello',
{
stdio: ['inherit', 'inherit', 'pipe'],
shell: '/bin/does-not-exist', // (A)
}
);
childProcess.on('error', (err) => { // (B)
assert.equal(
err.toString(),
'Error: spawn /bin/does-not-exist ENOENT'
);
});
这是我们第一次使用事件来处理子进程。在 B 行,我们为'error'事件注册了一个事件监听器。当前代码片段完成后,子进程开始。这有助于防止竞争条件:当我们开始监听时,我们可以确保事件尚未被触发。
12.2.6.2 Shell 中发生了错误
如果 shell 代码包含错误,我们不会收到'error'事件(B 行),而是会收到一个带有非零退出代码的'exit'事件(A 行):
import {Readable} from 'node:stream';
import {spawn} from 'node:child_process';
const childProcess = spawn(
'does-not-exist',
{
stdio: ['inherit', 'inherit', 'pipe'],
shell: true,
}
);
childProcess.on('exit',
async (exitCode, signalCode) => { // (A)
assert.equal(exitCode, 127);
assert.equal(signalCode, null);
const stderr = Readable.toWeb(
childProcess.stderr.setEncoding('utf-8'));
assert.equal(
await readableStreamToString(stderr),
'/bin/sh: does-not-exist: command not found\n'
);
}
);
childProcess.on('error', (err) => { // (B)
console.error('We never get here!');
});
12.2.6.3 进程被终止
如果在 Unix 上终止进程,退出代码是null(C 行),信号代码是一个字符串(D 行):
import {Readable} from 'node:stream';
import {spawn} from 'node:child_process';
const childProcess = spawn(
'kill $$', // (A)
{
stdio: ['inherit', 'inherit', 'pipe'],
shell: true,
}
);
console.log(childProcess.pid); // (B)
childProcess.on('exit', async (exitCode, signalCode) => {
assert.equal(exitCode, null); // (C)
assert.equal(signalCode, 'SIGTERM'); // (D)
const stderr = Readable.toWeb(
childProcess.stderr.setEncoding('utf-8'));
assert.equal(
await readableStreamToString(stderr),
'' // (E)
);
});
请注意,没有错误输出(E 行)。
子进程不是自己终止(A 行),我们也可以暂停它更长时间,然后通过我们在 B 行记录的进程 ID 手动终止它。
如果我们在 Windows 上杀死一个子进程会发生什么?
-
exitCode是1。 -
signalCode是null。
12.2.7 等待子进程退出
有时我们只想等到命令执行完毕。这可以通过事件和 Promise 来实现。
12.2.7.1 通过事件等待
import * as fs from 'node:fs';
import {spawn} from 'node:child_process';
const childProcess = spawn(
`(echo first && echo second) > tmp-file.txt`,
{
shell: true,
stdio: 'inherit',
}
);
childProcess.on('exit', (exitCode, signalCode) => { // (A)
assert.equal(exitCode, 0);
assert.equal(signalCode, null);
assert.equal(
fs.readFileSync('tmp-file.txt', {encoding: 'utf-8'}),
'first\nsecond\n'
);
});
我们使用标准的 Node.js 事件模式,并为 'exit' 事件注册了一个监听器(A 行)。
12.2.7.2 通过 Promises 等待
import * as fs from 'node:fs';
import {spawn} from 'node:child_process';
const childProcess = spawn(
`(echo first && echo second) > tmp-file.txt`,
{
shell: true,
stdio: 'inherit',
}
);
const {exitCode, signalCode} = await onExit(childProcess); // (A)
assert.equal(exitCode, 0);
assert.equal(signalCode, null);
assert.equal(
fs.readFileSync('tmp-file.txt', {encoding: 'utf-8'}),
'first\nsecond\n'
);
我们在 A 行使用的辅助函数 onExit() 返回一个 Promise,如果触发了 'exit' 事件,它就会被满足:
export function onExit(eventEmitter) {
return new Promise((resolve, reject) => {
eventEmitter.once('exit', (exitCode, signalCode) => {
if (exitCode === 0) { // (B)
resolve({exitCode, signalCode});
} else {
reject(new Error(
`Non-zero exit: code ${exitCode}, signal ${signalCode}`));
}
});
eventEmitter.once('error', (err) => { // (C)
reject(err);
});
});
}
如果 eventEmitter 失败,返回的 Promise 被拒绝,await 在 A 行抛出异常。onExit() 处理两种失败情况:
-
exitCode不是零(B 行)。发生了这种情况:-
如果有 shell 错误。那么
exitCode大于零。 -
如果在 Unix 上杀死子进程。那么
exitCode是null,signalCode是非空的。- 在 Windows 上杀死子进程会产生一个 shell 错误。
-
-
一个
'error'事件被触发(C 行)。如果孩子进程无法被生成,就会发生这种情况。
12.2.8 终止子进程
12.2.8.1 通过 AbortController 终止子进程
在这个例子中,我们使用 AbortController 来终止一个 shell 命令:
import {spawn} from 'node:child_process';
const abortController = new AbortController(); // (A)
const childProcess = spawn(
`echo Hello`,
{
stdio: 'inherit',
shell: true,
signal: abortController.signal, // (B)
}
);
childProcess.on('error', (err) => {
assert.equal(
err.toString(),
'AbortError: The operation was aborted'
);
});
abortController.abort(); // (C)
我们创建一个 AbortController(A 行),将其信号传递给 spawn()(B 行),并通过 AbortController 终止 shell 命令(C 行)。
子进程是异步启动的(在当前代码片段执行后)。这就是为什么我们可以在进程甚至开始之前中止,以及为什么在这种情况下我们看不到任何输出。
12.2.8.2 通过 .kill() 终止子进程
在下一个例子中,我们通过方法 .kill() 终止一个子进程(最后一行):
import {spawn} from 'node:child_process';
const childProcess = spawn(
`echo Hello`,
{
stdio: 'inherit',
shell: true,
}
);
childProcess.on('exit', (exitCode, signalCode) => {
assert.equal(exitCode, null);
assert.equal(signalCode, 'SIGTERM');
});
childProcess.kill(); // default argument value: 'SIGTERM'
再次,在孩子进程开始之前我们就杀死了它(异步!),并且没有输出。
12.3 同步生成进程:spawnSync()
spawnSync(
command: string,
args?: Array<string>,
options?: Object
): Object
spawnSync() 是 spawn() 的同步版本 - 它会等待子进程退出,然后同步返回一个对象。
参数大多与spawn()相同。options 有一些额外的属性 - 例如:
-
.input: string | TypedArray | DataView如果这个属性存在,它的值将被发送到子进程的标准输入。
-
.encoding: string(默认:'buffer')指定用于所有标准 I/O 流的编码。
该函数返回一个对象。它最有趣的属性是:
-
.stdout: Buffer | string包含写入子进程标准输出流的内容。
-
.stderr: Buffer | string包含写入子进程标准错误流的内容。
-
.status: number | null包含子进程的退出代码或
null。退出代码或信号代码中的一个是非空的。 -
.signal: string | null包含孩子进程的信号代码或
null。退出代码或信号代码中的一个是非空的。 -
.error?: Error只有在生成失败时才会创建这个属性,然后包含一个错误对象。
使用异步的 spawn() 时,子进程并行运行,我们可以通过流读取标准 I/O。相反,同步的 spawnSync() 收集流的内容并将其同步返回给我们(见下一小节)。
12.3.1 shell 命令何时执行?
使用同步的 spawnSync() 时,命令的子进程是同步启动的。以下代码演示了这一点:
import {spawnSync} from 'node:child_process';
spawnSync(
'echo', ['Command starts'],
{
stdio: 'inherit',
shell: true,
}
);
console.log('After spawnSync()');
这是输出:
Command starts
After spawnSync()
12.3.2 从标准输出读取
以下代码演示了如何读取标准输出:
import {spawnSync} from 'node:child_process';
const result = spawnSync(
`echo rock && echo paper && echo scissors`,
{
stdio: ['ignore', 'pipe', 'inherit'], // (A)
encoding: 'utf-8', // (B)
shell: true,
}
);
console.log(result);
assert.equal(
result.stdout, // (C)
'rock\npaper\nscissors\n'
);
assert.equal(result.stderr, null); // (D)
在 A 行,我们使用 options.stdio 告诉 spawnSync() 我们只对标准输出感兴趣。我们忽略标准输入,并将标准错误传输到父进程。
因此,我们只能得到标准输出的结果属性(C 行),标准错误的属性是 null(D 行)。
由于我们无法访问spawnSync()内部使用的流来处理子进程的标准 I/O,我们通过options.encoding(B 行)告诉它使用哪种编码。
12.3.3 向子进程的 stdin 发送数据
我们可以通过选项属性.input(A 行)向子进程的标准输入流发送数据:
import {spawnSync} from 'node:child_process';
const result = spawnSync(
`sort`,
{
stdio: ['pipe', 'pipe', 'inherit'],
encoding: 'utf-8',
input: 'Cherry\nApple\nBanana\n', // (A)
}
);
assert.equal(
result.stdout,
'Apple\nBanana\nCherry\n'
);
12.3.4 处理不成功的退出(包括错误)
有三种主要的不成功的退出情况(当退出代码不为零时):
-
子进程无法被生成。
-
shell 中发生错误。
-
进程被终止。
12.3.4.1 子进程无法生成
如果生成失败,spawn()会发出一个'error'事件。相比之下,spawnSync()将result.error设置为一个错误对象:
import {spawnSync} from 'node:child_process';
const result = spawnSync(
'echo hello',
{
stdio: ['ignore', 'inherit', 'pipe'],
encoding: 'utf-8',
shell: '/bin/does-not-exist',
}
);
assert.equal(
result.error.toString(),
'Error: spawnSync /bin/does-not-exist ENOENT'
);
12.3.4.2 shell 中发生错误
如果在 shell 中发生错误,退出代码result.status大于零,result.signal为null:
import {spawnSync} from 'node:child_process';
const result = spawnSync(
'does-not-exist',
{
stdio: ['ignore', 'inherit', 'pipe'],
encoding: 'utf-8',
shell: true,
}
);
assert.equal(result.status, 127);
assert.equal(result.signal, null);
assert.equal(
result.stderr, '/bin/sh: does-not-exist: command not found\n'
);
12.3.4.3 进程被终止
如果在 Unix 上终止子进程,result.signal包含信号的名称,result.status为null:
import {spawnSync} from 'node:child_process';
const result = spawnSync(
'kill $$',
{
stdio: ['ignore', 'inherit', 'pipe'],
encoding: 'utf-8',
shell: true,
}
);
assert.equal(result.status, null);
assert.equal(result.signal, 'SIGTERM');
assert.equal(result.stderr, ''); // (A)
请注意,没有输出发送到标准错误流(A 行)。
如果我们在 Windows 上终止一个子进程:
-
result.status为 1 -
result.signal为null -
result.stderr为''
12.4 基于spawn()的异步辅助函数
在本节中,我们将看到基于spawn()的两个异步函数:
-
exec() -
execFile()
在本章中,我们忽略了fork()。引用Node.js 文档:
fork()生成一个新的 Node.js 进程,并调用一个指定的模块,建立了一个 IPC 通信通道,允许在父进程和子进程之间发送消息。
12.4.1 exec()
exec(
command: string,
options?: Object,
callback?: (error, stdout, stderr) => void
): ChildProcess
exec()在新生成的 shell 中运行一个命令。与spawn()的主要区别在于:
-
除了返回一个 ChildProcess,
exec()还通过回调函数传递结果:错误对象或 stdout 和 stderr 的内容。 -
错误原因:子进程无法生成,shell 错误,子进程被终止。
- 相比之下,
spawn()只在子进程无法被生成时发出'error'事件。另外两种失败是通过退出代码和(在 Unix 上)信号代码来处理的。
- 相比之下,
-
没有参数
args。 -
options.shell的默认值为true。
import {exec} from 'node:child_process';
const childProcess = exec(
'echo Hello',
(error, stdout, stderr) => {
if (error) {
console.error('error: ' + error.toString());
return;
}
console.log('stdout: ' + stdout); // 'stdout: Hello\n'
console.error('stderr: ' + stderr); // 'stderr: '
}
);
exec()可以通过util.promisify()转换为基于 Promise 的函数:
-
ChildProcess 成为返回的 Promise 的属性。
-
Promise 的解决方式如下:
-
完成值:
{stdout, stderr} -
拒绝值:与回调函数的参数
error相同,但有两个额外的属性:.stdout和.stderr。
-
import * as util from 'node:util';
import * as child_process from 'node:child_process';
const execAsync = util.promisify(child_process.exec);
try {
const resultPromise = execAsync('echo Hello');
const {childProcess} = resultPromise;
const obj = await resultPromise;
console.log(obj); // { stdout: 'Hello\n', stderr: '' }
} catch (err) {
console.error(err);
}
12.4.2 execFile()
execFile(file, args?, options?, callback?): ChildProcess
与exec()类似,具有以下区别:
-
支持参数
args。 -
options.shell的默认值为false。
与exec()类似,execFile()可以通过util.promisify()转换为基于 Promise 的函数。
12.5 基于spawnAsync()的同步辅助函数
12.5.1 execSync()
execSync(
command: string,
options?: Object
): Buffer | string
execSync()在一个新的子进程中运行一个命令,并同步等待该进程退出。与spawnSync()的主要区别在于:
-
只返回 stdout 的内容。
-
三种失败通过异常报告:子进程无法生成,shell 错误,子进程被终止。
- 相比之下,
spawnSync()的结果只有一个.error属性,如果子进程无法被生成。另外两种失败是通过退出代码和(在 Unix 上)信号代码来处理的。
- 相比之下,
-
没有参数
args。 -
options.shell的默认值为true。
import {execSync} from 'node:child_process';
try {
const stdout = execSync('echo Hello');
console.log('stdout: ' + stdout); // 'stdout: Hello\n'
} catch (err) {
console.error('Error: ' + err.toString());
}
12.5.2 execFileSync()
execFileSync(file, args?, options?): Buffer | string
与execSync()类似,但有以下区别:
-
支持参数
args。 -
options.shell的默认值是false。
12.6 有用的库
12.6.1 tinysh:生成 shell 命令的辅助程序
tinysh由 Anton Medvedev 是一个帮助生成 shell 命令的小型库-例如:
import sh from 'tinysh';
console.log(sh.ls('-l'));
console.log(sh.cat('README.md'));
我们可以通过使用.call()将对象作为this传递来覆盖默认选项:
sh.tee.call({input: 'Hello, world!'}, 'file.txt');
我们可以使用任何属性名称,tinysh 会使用该名称执行 shell 命令。它通过代理实现了这一壮举。这是实际库的略微修改版本:
import {execFileSync} from 'node:child_process';
const sh = new Proxy({}, {
get: (_, bin) => function (...args) { // (A)
return execFileSync(bin, args,
{
encoding: 'utf-8',
shell: true,
...this // (B)
}
);
},
});
在 A 行中,我们可以看到如果从sh获取名为bin的属性,则返回一个调用execFileSync()并使用bin作为第一个参数的函数。
在 B 行中传播this使我们能够通过.call()指定选项。默认值首先出现,以便可以通过this进行覆盖。
12.6.2 node-powershell:通过 Node.js 执行 Windows PowerShell 命令
在 Windows 上使用node-powershell 库的示例如下:
import { PowerShell } from 'node-powershell';
PowerShell.$`echo "hello from PowerShell"`;
12.7 在模块'node:child_process'的函数之间进行选择
一般约束:
-
在执行命令时,其他异步任务是否应该运行?
- 使用任何异步函数。
-
您是否只执行一个命令(没有后台异步任务)?
- 使用任何同步函数。
-
您想通过流访问子进程的 stdin 或 stdout 吗?
- 只有异步函数才能让您访问流:在这种情况下,
spawn()更简单,因为它没有提供传递错误和标准 I/O 内容的回调。
- 只有异步函数才能让您访问流:在这种情况下,
-
您想在字符串中捕获 stdout 或 stderr 吗?
-
异步选项:
exec()和execFile() -
同步选项:
spawnSync(),execSync(),execFileSync()
-
异步函数-在spawn()和exec()或execFile()之间进行选择:
-
exec()和execFile()有两个好处:-
由于它们都通过第一个回调参数报告,因此更容易处理失败。
-
获取 stdout 和 stderr 作为字符串更容易-由于回调。
-
-
如果这些好处对您不重要,您可以选择
spawn()。它的签名更简单,没有(可选的)回调。
同步函数-在spawnSync()和execSync()或execFileSync()之间进行选择:
-
execSync()和execFileSync()有两个特点:-
它们返回一个包含 stdout 内容的字符串。
-
由于它们都通过异常报告,因此更容易处理失败。
-
-
如果您需要比
execSync()和execFileSync()通过它们的返回值和异常提供的更多信息,则选择spawnSync()。
在exec()和execFile()之间进行选择(选择execSync()和execFileSync()时适用相同的参数):
-
options.shell在exec()中的默认值为true,但在execFile()中为false。 -
execFile()支持args,exec()不支持。
评论
第四部分:处理包
原文:
exploringjs.com/nodejs-shell-scripting/pt_packages.html译者:飞龙
协议:CC BY-NC-SA 4.0
接下来:13 安装 npm 包并运行 bin 脚本
十三、安装 npm 包并运行 bin 脚本
原文:
exploringjs.com/nodejs-shell-scripting/ch_installing-packages.html译者:飞龙
协议:CC BY-NC-SA 4.0
-
13.1 全局安装 npm 注册表包
-
13.1.1 哪些包是全局安装的?
npm ls -g(ch_installing-packages.html#which-packages-are-installed-globally-npm-ls–g) -
13.1.2 全局安装的包在哪里?
npm root -g(ch_installing-packages.html#where-are-packages-installed-globally-npm-root–g) -
13.1.3 全局安装的 shell 脚本在哪里?
npm bin -g(ch_installing-packages.html#where-are-shell-scripts-installed-globally-npm-bin–g) -
13.1.4 全局安装的包在哪里?npm 安装前缀
-
13.1.5 更改全局安装包的位置
-
-
13.2 在本地安装 npm 注册表包
- 13.2.1 在本地安装 bin 脚本
-
13.3 安装未发布的包
-
13.3.1
npm link: 全局安装未发布的包 -
13.3.2
npm link: 在本地安装全局链接的包 -
13.3.3
npm link: 撤消链接 -
13.3.4 通过本地路径安装未发布的包(ch_installing-packages.html#installing-unpublished-packages-via-local-paths)
-
13.3.5 安装未发布包的其他方法
-
-
13.4
npx: 在不安装的情况下运行 npm 包中的 bin 脚本- 13.4.1 npx 缓存
package.json 属性 "bin" 允许 npm 包指定它提供的 shell 脚本(有关更多信息,请参见§14“创建跨平台 shell 脚本”)。如果我们安装了这样的包,Node.js 会确保我们可以从命令行访问这些 shell 脚本(称为bin 脚本)。在本章中,我们探讨了两种安装带有 bin 脚本的包的方法:
-
在本地安装带有 bin 脚本的包意味着将其安装为包内的依赖项。这些脚本只能在该包内访问。
-
全局安装带有 bin 脚本的包意味着将其安装在“全局位置”,以便脚本可以在任何地方访问-无论是当前用户还是系统的所有用户(取决于 npm 的设置方式)。
我们探讨了所有这些的含义以及我们如何在安装后运行 bin 脚本。
13.1 全局安装 npm 注册表包
包cowsay 具有以下 package.json 属性:
"bin": {
"cowsay": "./cli.js",
"cowthink": "./cli.js"
},
要全局安装此包,我们使用 npm install -g:
npm install -g cowsay
注意:在 Unix 上,我们可能需要使用 sudo(我们很快将学会如何避免这样做):
sudo npm install -g cowsay
之后,我们可以在命令行中使用 cowsay 和 cowthink 命令。
请注意,只有 bin 脚本在全局可用。当 Node.js 在node_modules目录中查找裸模块规范时,包会被忽略。
13.1.1 哪些包是全局安装的? npm ls -g
我们可以检查全局安装的包以及它们的位置:
% npm ls -g
/usr/local/lib
├── corepack@0.12.1
├── cowsay@1.5.0
└── npm@8.15.0
在 Windows 上,安装路径是 %AppData%\npm,例如:
>echo %AppData%\npm
C:\Users\jane\AppData\Roaming\npm
13.1.2 全局安装的包在哪里? npm root -g
macOS 上的结果:
% npm root -g
/usr/local/lib/node_modules
Windows 上的结果:
>npm root -g
C:\Users\jane\AppData\Roaming\npm\node_modules
13.1.3 全局安装的 shell 脚本在哪里? npm bin -g
npm bin -g告诉我们 npm 全局安装 shell 脚本的位置。它还确保该目录在 shell PATH 中可用。
macOS 上的结果:
% npm bin -g
/usr/local/bin
% which cowsay
/usr/local/bin/cowsay
在 Windows 命令 shell 上的结果:
>npm bin -g
C:\Users\jane\AppData\Roaming\npm
>where cowsay
C:\Users\jane\AppData\Roaming\npm\cowsay
C:\Users\jane\AppData\Roaming\npm\cowsay.cmd
没有文件名扩展名的可执行文件cowsay是针对基于 Unix 的 Windows 环境(如 Cygwin、MinGW 和 MSYS)的。
Windows PowerShell 返回gcm cowsay的路径:
C:\Users\jane\AppData\Roaming\npm\cowsay.ps1
13.1.4 全局安装的包在哪里?npm 安装前缀
npm 的安装前缀决定了全局安装包和 bin 脚本的安装位置。
这是 macOS 上的安装前缀:
% npm config get prefix
/usr/local
因此:
-
包安装在
/usr/local/lib/node_modules中 -
Bin 脚本安装在
/usr/local/bin中
这是 Windows 上的安装前缀:
>npm config get prefix
C:\Users\jane\AppData\Roaming\npm
因此:
-
包安装在
C:\Users\jane\AppData\Roaming\npm\node_modules中 -
Bin 脚本安装在
C:\Users\jane\AppData\Roaming\npm中
13.1.5 改变全局安装包位置
在这一部分,我们将研究两种改变全局安装包位置的方法:
-
更改 npm 安装前缀
-
使用 Node.js 版本管理器
13.1.5.1 改变 npm 安装前缀
改变全局安装包位置的一种方法是改变 npm 的安装前缀。
Unix:
mkdir ~/npm-global
npm config set prefix '~/npm-global'
Windows 命令 shell:
mkdir "%UserProfile%\npm-global"
npm config set prefix "%UserProfile%\npm-global"
Windows PowerShell:
mkdir "$env:UserProfile\npm-global"
npm config set prefix "$env:UserProfile\npm-global"
配置数据保存在主目录中的.npmrc文件中。
从现在开始,全局安装将被添加到我们刚刚指定的目录中。
之后,我们仍然需要将npm bin -g目录添加到我们的 shell PATH 中,以便我们的 shell 可以找到我们全局安装的 bin 脚本。
**更改 npm 前缀的一个缺点:**如果我们告诉 npm 升级自己,它现在也会安装到新位置。
13.1.5.2 使用 Node.js 版本管理器
Node.js 版本管理器可以让我们同时安装多个 Node.js 版本并在它们之间切换。流行的版本管理器包括:
-
Unix:nvm
-
跨平台:Volta
13.2 安装 npm 注册包到本地
要本地安装 npm 注册包(如cowsay),我们需要执行以下操作:
cd my-package/
npm install cowsay
这将向package.json添加以下数据:
"dependencies": {
"cowsay": "¹.5.0",
···
}
此外,该包被下载到以下目录:
my-package/node_modules/cowsay/
在 Unix 上,npm 为 bin 脚本添加了这些符号链接:
my-package/node_modules/.bin/cowsay -> ../cowsay/cli.js
my-package/node_modules/.bin/cowthink -> ../cowsay/cli.js
在 Windows 上,npm 将这些文件添加到my-package\node_modules\.bin\中:
cowsay
cowsay.cmd
cowsay.ps1
cowthink
cowthink.cmd
cowthink.ps1
没有扩展名的文件是针对基于 Unix 的 Windows 环境(如 Cygwin、MinGW 和 MSYS)的脚本。
npm bin告诉我们本地安装的 bin 脚本的位置 - 例如:
% npm bin
/Users/john/my-package/node_modules/.bin
注意:本地安装的包始终安装在package.json文件旁边的node_modules目录中。如果当前目录中不存在package.json,npm 会在祖先目录中搜索并在那里安装包。要检查 npm 在本地安装包的位置,我们可以使用npm root命令 - 例如(Unix):
% cd $HOME
% npm root
/Users/john/node_modules
John 的主目录中没有package.json,但 npm 无法在祖先目录中安装任何内容,这就是为什么npm root显示这个目录。在当前位置本地安装包将导致创建package.json并像往常一样进行安装。
13.2.1 运行本地安装的 bin 脚本
(本小节中的所有命令都在my-package目录中执行。)
13.2.1.1 直接运行 bin 脚本
我们可以从 shell 中如下运行cowsay:
./node_modules/.bin/cowsay Hello
在 Unix 上,我们可以设置一个辅助程序:
alias npm-exec='PATH=$(npm bin):$PATH'
然后以下命令有效:
npm-exec cowsay Hello
13.2.1.2 通过包脚本运行 bin 脚本
我们还可以在package.json中添加一个包脚本:
{
···
"scripts": {
"cowsay": "cowsay"
},
···
}
现在我们可以在 shell 中执行这个命令:
npm run cowsay Hello
这是因为 npm 在 Unix 上临时将以下条目添加到$PATH中:
/Users/john/my-package/node_modules/.bin
/Users/john/node_modules/.bin
/Users/node_modules/.bin
/node_modules/.bin
在 Windows 上,类似的条目被添加到%Path%或$env:Path中:
C:\Users\jane\my-package\node_modules\.bin
C:\Users\jane\node_modules\.bin
C:\Users\node_modules\.bin
C:\node_modules\.bin
以下命令列出了包脚本运行时存在的环境变量及其值:
npm run env
13.2.1.3 通过 npx 运行 bin 脚本
在一个包内,可以使用 npx 来访问 bin 脚本:
npx cowsay Hello
npx cowthink Hello
稍后再详细介绍 npx。
13.3 安装未发布的包
有时,我们有一个包,要么我们还没有发布,要么永远不会发布,并且想要安装它。
13.3.1 npm link:全局安装未发布的包
假设我们有一个未发布的包,其名称是 @my-scope/unpublished-package,存储在目录 /tmp/unpublished-package/ 中。我们可以按如下方式全局提供它:
cd /tmp/unpublished-package/
npm link
如果我们这样做:
-
npm 将一个符号链接添加到全局的
node_modules(由npm root -g返回)- 例如:/usr/local/lib/node_modules/@my-scope/unpublished-package -> ../../../../../tmp/unpublished-package -
在 Unix 上,npm 还会从全局 bin 目录(由
npm bin -g返回)到每个 bin 脚本添加一个符号链接。该链接不是直接的,而是通过全局node_modules目录:/usr/local/bin/my-command -> ../lib/node_modules/@my-scope/unpublished-package/src/my-command.js -
在 Windows 上,它添加了通常的 3 个脚本(通过相对路径引用全局
node_modules中的链接包):C:\Users\jane\AppData\Roaming\npm\my-command C:\Users\jane\AppData\Roaming\npm\my-command.cmd C:\Users\jane\AppData\Roaming\npm\my-command.ps1
由于链接包的引用方式,其中的任何更改都会立即生效。当它发生变化时,无需重新链接它。
要检查全局安装是否成功,我们可以使用 npm ls -g 列出所有全局安装的包。
13.3.2 npm link:在本地安装全局链接的包
在我们全局安装了未发布的包之后(参见前一小节),我们可以选择在我们的一个包中(可以是已发布的或未发布的)中将其安装为本地包:
cd /tmp/other-package/
npm link @my-scope/unpublished-package
这创建了以下链接:
/tmp/other-package/node_modules/@my-scope/unpublished-package
-> ../../../unpublished-package
默认情况下,未发布的包不会被添加为 package.json 的依赖项。其背后的原因是 npm link 经常用于临时使用注册表包的未发布版本- 这些不应该出现在依赖项中。
13.3.3 npm link:取消链接
取消本地链接:
cd /tmp/other-package/
npm uninstall @my-scope/unpublished-package
取消全局链接:
cd /tmp/unpublished-package/
npm uninstall -g
13.3.4 通过本地路径安装未发布的包
另一种在本地安装未发布的包的方法是使用 npm install 并通过本地路径引用它(而不是通过包名):
cd /tmp/other-package/
npm install ../unpublished-package
这有两个效果。
首先,创建以下符号链接:
/tmp/other-package/node_modules/@my-scope/unpublished-package
-> ../../../unpublished-package
其次,将依赖项添加到 package.json 中:
"dependencies": {
"@my-scope/unpublished-package": "file:../unpublished-package",
···
}
这种安装未发布的包的方法也适用于全局:
cd /tmp/unpublished-package/
npm install -g .
13.3.5 安装未发布的包的其他方法
-
Yalc 让我们将包发布到本地的“Yalc 仓库”(类似本地注册表)。从该仓库中,我们可以将包安装为依赖项,例如,一个名为
my-package/的包。它们被复制到目录my-package/.yalc中,并且file:或link:依赖项被添加到package.json中。 -
relative-deps支持package.json中的"relativeDependencies",如果存在的话,会覆盖正常的依赖关系。与npm link和本地路径安装相比:-
正常的依赖关系不需要更改。
-
相对依赖项被安装为来自 npm 注册表的依赖项(而不是通过符号链接)。
relative-deps还有助于保持本地安装的相对依赖项及其原始依赖项同步。 -
-
npx link是npm link的一个更安全的版本,它不需要全局安装,还有其他好处。
13.4 npx:在不安装它们的情况下运行 npm 包中的 bin 脚本
npx 是一个与 npm 捆绑在一起的用于运行 bin 脚本的 shell 命令。
它最常见的用法是:
npx <package-name> arg1 arg2 ...
这个命令将名称为 package-name 的包安装到 npx 缓存中,并运行与包同名的 bin 脚本- 例如:
npx cowsay Hello
这意味着我们可以在不先安装它们的情况下运行 bin 脚本。npx 最适用于一次性调用 bin 脚本- 例如,许多框架提供用于设置新项目的 bin 脚本,这些通常通过 npx 运行。
npx 第一次使用包后,它将在其缓存中可用,并且后续调用速度更快。但是,我们无法确定包在缓存中停留的时间有多长。因此,npx 不能替代全局或本地安装 bin 脚本。
如果一个包带有与其包名称不同的 bin 脚本,我们可以像这样访问它们:
npx --package=<package-name> <bin-script> arg1 arg2 ...
例如:
npx --package=cowsay cowthink Hello
13.4.1 npx 缓存
npx 的缓存位于哪里?
在 Unix 上,我们可以通过以下命令找到:
npx --package=cowsay node -p \
"process.env.PATH.split(':').find(p => p.includes('_npx'))"
返回类似于这样的路径:
/Users/john/.npm/_npx/8f497369b2d6166e/node_modules/.bin
在 Windows 上,我们可以使用(一行分成两行):
npx --package=cowsay node -p
"process.env.Path.split(';').find(p => p.includes('_npx'))"
返回类似于这样的路径(单个路径分成两行):
C:\Users\jane\AppData\Local\npm-cache\_npx\
8f497369b2d6166e\node_modules\.bin
请注意,npx 的缓存与 npm 用于安装模块的缓存不同:
-
Unix:
-
npm 缓存:
$HOME/.npm/_cacache/ -
npx 缓存:
$HOME/.npm/_npx/
-
-
Windows(PowerShell):
-
npm 缓存:
$env:UserProfile\AppData\Local\npm-cache\_npx\ -
npx 缓存:
$env:UserProfile\AppData\Local\npm-cache\_cacache\
-
两个缓存的父目录可以通过以下方式确定:
npm config get cache
有关 npm 缓存的更多信息,请参阅npm 文档。
与 npx 缓存相比,npm 缓存中的数据永远不会被删除,只会被添加。我们可以在 Unix 上通过以下方式检查其大小:
du -sh $(npm config get cache)/_cacache/
在 Windows PowerShell 上:文章来源:https://www.toymoban.com/news/detail-820066.html
DiskUsage /d:0 "$(npm config get cache)\_cacache"
评论文章来源地址https://www.toymoban.com/news/detail-820066.html
到了这里,关于Node.js Shell 脚本开发指南(中)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
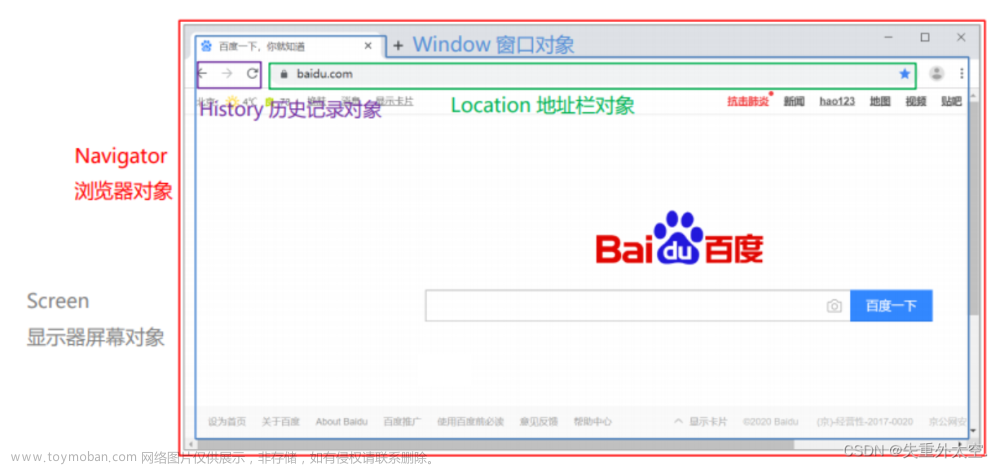


![uniapp适配微信隐私协议开发指南[uniapp+vue3+js]](https://imgs.yssmx.com/Uploads/2024/02/732508-1.png)





