原文来自【 Qualcomm’s Hexagon DSP, and now, NPU 】
本文主要介绍Qualcomm Hexagon DSP和NPU,这些为处理简单大量运算而设计的硬件。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
一、前言
二、High Level
三、Frontend
四、Fetch and Decode
五、Scalar Integer Execution
六、Vector Execution (HVX)
七、Tensor
八、Final Words
九、参考
一、前言
手机必须处理电信和视听处理,同时最大限度地延长电池寿命。数字信号处理器 (DSP) 使用专用硬件从 CPU 卸载这些任务,从而降低功耗。

高通公司的 Hexagon 在公司 Snapdragon 产品中卸载信号处理方面有着悠久的历史。为了应对近期机器学习应用的兴起,高通正在为 Hexagon 添加矩阵乘法功能。

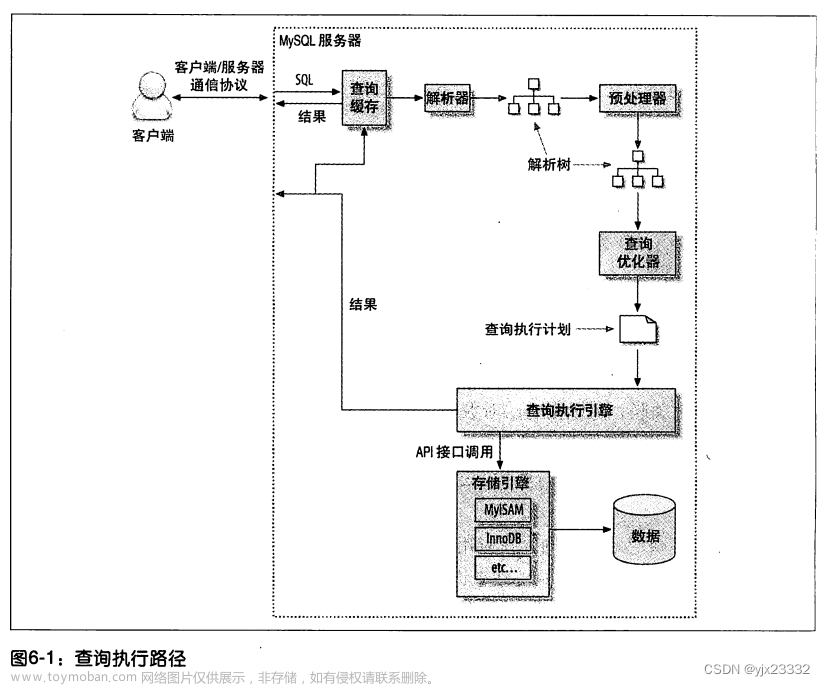
二、High Level
Hexagon 是一款有序、四宽超长指令字 (VLIW) 处理器,具有专门的信号处理功能。它使用 SMT 来利用线程级并行性并隐藏延迟。Hexagon 的矢量和张量单元使用协处理器模型,能够提供大量的每时钟吞吐量。

Hexagon 就像 CPU 一样支持虚拟内存和缓存,并且可以运行编译后的 C 代码。但是,它具有不同的执行模型,其中指令首先提交然后执行。该模型支持深度执行管道,但缺点是某些异常只能在提交后捕获,因此不精确。

在 Snapdragon 8 Gen 2 中,Hexagon 具有 6 路 SMT。因此,高通的 DSP 介于每个 SMSP/SIMD 具有 12/16 线程的 GPU 和很少超出 2 路 SMT 的 CPU 之间。默认情况下,每个 Hexagon 线程都会获取一个标量上下文,但必须请求访问才能使用向量或张量协处理器。
三、Frontend
分支预测通常与高性能 CPU 相关。然而,高通公司认为为 Hexagon 实现分支预测器是合适的,BTB 和返回堆栈命中的性能监控事件就证明了这一点。事件描述表明大多数分支可以通过两个周期的延迟来处理,不太常见的是 3 个周期的延迟。在 3 个周期的情况下,BTB 可能没有为分支缓存的目标,并且解码器计算目标地址。如果是这样,指令缓存将有 3 个周期的延迟。

方向预测可能是通过简单的双峰计数器提供的,其机制类似于原始奔腾。即使是一个简单的分支预测器也比没有预测器好,这使得 Hexagon 能够在不过度依赖线程级并行性的情况下表现良好。
四、Fetch and Decode
一旦分支预测器提供了目标地址,Hexagon 就会从指令缓存中获取 128 位 VLIW 包。高通没有指定 Hexagon 的指令缓存大小,但之前的版本有 16 KB。如果 Hexagon 保持相同的指令缓存大小,我不会感到惊讶,因为吞吐量受限的应用程序往往具有较小的指令占用空间。

每个 VLIW 捆绑包(bundle)最多包含四个指令,这让我想知道为什么高通选择“Hexagon”名称。“Qualcomm Quadrilateral”会更有意义,听起来也更好。VLIW 捆绑包允许使用简单的硬件进行超标量执行。解码器很便宜,因为特定的 VLIW 位置仅包含指令的子集。硬件先读后写和先写后写危险解决方案是不必要的,因为打包到 VLIW 包中的指令必须是独立的,并且不能写入相同的目标寄存器。执行管道选择逻辑也被简化,因为每个VLIW包位置对应于一个执行管道。
指令被获取和解码后,它们被发送到适当的单元或协处理器来执行。
五、Scalar Integer Execution
Hexagon 有一个 32 位标量单元,每个线程上下文有 32 个寄存器。与 AMD GCN 或 RDNA 上的标量单元主要从向量单元卸载控制流和地址生成操作不同,Hexagon 的标量单元非常强大,可以自行处理轻量级 DSP 任务。由于采用 VLIW 封装,每个周期最多可以完成 4 条指令,并且每条指令都可以代表大量工作。H.264 解码有针对绝对差和 (SAD)、位域操作和上下文自适应二进制算术编码 (CABAC) 的专用指令。“标量”单元甚至可以进行向量运算。字节或半字(16 位)元素可以打包到 32 位寄存器中。相邻的 32 位寄存器可以作为 64 位寄存器进行寻址,从而允许更长的向量宽度操作,包括 2 x 32 位寄存器。标量单元的两个管道也可以处理浮点运算。它类似于 Intel 的 MMX,只不过向量寄存器是通用寄存器的别名。

硬件循环和循环缓冲区处理有助于提高指令密度和寄存器利用率。两对循环启动和循环计数寄存器提供硬件循环支持,从而释放通用寄存器来保存其他数据。硬件循环可以辅助分支预测器,但对于迭代次数为 2 或更少的小循环,仍然可能会发生错误预测。循环缓冲区也获得硬件支持。CS0 和 CS1 寄存器存储缓冲区基址,缓冲区长度存储在 M0 或 M1 寄存器中。然后,程序可以使用循环缓冲区,而无需对每个指针增量进行边界检查。特殊的“全局指针”寄存器可以与全局指针相对寻址模式一起使用,帮助访问全局或静态数据。这些机制可以减少套准压力。

标量端内存访问由未指定大小的 L1 缓存提供服务,尽管 Hexagon 过去使用过 32 KB L1D。L1 数据缓存只有两个 64 位端口,专用于标量单元。Hexagon 的加载/存储单元通过重播解决内存依赖性、页面交叉、存储缓冲区填充和缓存组冲突等边缘情况。
L1 未命中由 L2 缓存处理。同样,高通没有给出缓存大小,但 Snapdragon 820 的 Hexagon DSP使用了 512 KB L2。较旧的 Snapdragon 800 使用 256 KB L2 1,因此高通当前的 DSP 可能具有 1 MB 或更大的 L2 。v73 PRM 指的是具有 32 个条目的 L2 记分板,因此 L2 缓存可能可以处理 32 个待处理请求。
六、Vector Execution (HVX)
Hexagon Vector Extensions为更繁重的 DSP 任务提供了更多支持。HVX 提供 32 个 1024 位向量寄存器和一组粗略映射到 VLIW 捆绑位置的执行管道。Hexagon DSP 的可用向量上下文通常少于标量上下文,因此线程必须请求 HVX 访问。Hexagon V73 PRM 给出了具有四个向量上下文的示例。四个上下文将有 16 KB 的向量寄存器。相比之下,Intel 的 Skylake-X 有 10.7 KB 的矢量寄存器来支持 AVX-512。让线程请求 HVX 功能而不是默认提供它,可以让 Hexagon 在没有 GPU 大小的寄存器文件的情况下运行,并关闭矢量协处理器以执行轻量级任务。

除了大型向量寄存器文件之外,HVX 还为每个线程提供四个 128 位谓词寄存器。谓词寄存器可以保存向量比较的结果,并且可以用作某些指令(例如条件累加)的掩码。
过去的 Hexagon 实现仅专注于向量整数运算,但高通添加了浮点功能以使 HVX 更加灵活。

由于矢量化应用程序往往会占用大量内存,因此 Qualcomm 甚至不会尝试在 L1 中缓存矢量访问。相反,向量单元使用 L2 缓存作为其第一级缓存。除了 L2 缓存外,Hexagon 还具有大型 TCM(紧耦合内存)。这是一个软件管理的暂存器,类似于 AMD GCN 的 LDS,但很大。Snapdragon 8 Gen 2 上的 Hexagon 具有 8 MB TCM。
TCM 对于 Hexagon 的高性能分散和聚集操作至关重要。聚集指令从内存中的非连续位置填充向量,而分散指令则在相反方向上执行相同的操作。分散和聚集对于缓存来说很困难,因为具有 128 字节大小元素的 1024 位向量可能需要 128 次内存访问。在集合关联高速缓存中查找行需要将地址与集合中的每个标记进行比较。从假设的 512 KB、8 路 L2 收集的最坏情况可能需要 128 * 8 = 1024 次标签比较。由于 TCM 不是缓存,因此它避免了标签检查的开销。Hexagon 甚至不会尝试在可缓存内存上执行分散和聚集操作,而仅在 TCM 上执行这些操作。

与标量侧一样,HVX 也有专门的 DSP 硬件。直方图指令有助于计算图像中亮度值的 256 箱直方图,并消耗四个 VLIW 包上的所有执行资源。其他向量指令与 AVX 上的指令类似,包括向量加法、最小/最大、绝对值和一些归约运算。
七、Tensor
HVX 在机器学习的矩阵乘法方面可以做得还过得去,但与 Nvidia、AMD 和英特尔一样,高通也看到了很多优化机会。专用矩阵乘法指令允许每条指令完成更多工作,从而降低功耗。累加器可以得到特殊处理,因为值会添加到它们中,但累加器值不会被读取太多(除了在写回内存之前进行下转换)。高通因此为Hexagon添加了张量协处理器。我很惊讶他们没有将其称为“高通矩形”,因为这就是矩阵的样子。

Hexagon 的 NPU 每个周期可以完成大量 16K 乘法累加运算,可能使用 4 位权重。相比之下,AMD Phoenix XDNA 上的 16 个 AIE-ML 块可以在每个周期以 4 位整数精度完成 8K 乘法累加运算,在 1.25 GHz 下实现 20 TOPS。XDNA 的运行时钟可能比 Hexagon 的 NPU 高得多。高通没有透露时钟目标,但我们可以通过查看前几代产品来推断这一点。

Snapdragon 855/865 的 Hexagon DSP 时钟频率为 576 MHz。如果 DSP 可以在张量单元处于活动状态时实现相同的时钟,那么它应该能够达到 18.8 TOPS,与 Phoenix 大致相当。如果 Hexagon 在张量负载下以较低的时钟运行,我也不会感到惊讶。但即使是这样,高通公司也有信心他们最新的 DSP 能够在机器学习应用中击败以前的 DSP。

八、Final Words
Hexagon 让您深入了解 DSP 的奇异世界。它位于 CPU 和 GPU 世界之间,将宽向量和张量单元与分支预测等 CPU 舒适性相结合。线程级并行能力也处于中间立场。Hexagon 使用 6 路 SMT,使其比典型的 CPU 内核具有更多的线程级并行性。但它缺乏 GPU 执行单元用来保持十几个或更多线程运行的大量寄存器文件。4 宽 VLIW 执行也旨在寻求中间立场。最近的 GPU 基本上是标量机器,偶尔具有双发射功能,而 CPU 则具有广泛的乱序执行功能。VLIW 不像乱序执行那么灵活,但可以为行为良好的代码提供更高的每线程性能。
因此,最终的处理器提供了一些 CPU 舒适性,同时仍然严重依赖指令集来简化硬件。它可能是音频解码等轻量级 DSP 任务的理想组合。这些应用程序应该具有足够的可预测性,以便 VLIW 能够表现良好,但并行性不足以证明在 GPU 上运行是合理的。有一段时间,海克斯康只需要一个“标量”单元。

随着处理需求的增长,Qualcomm 添加了 HVX 以提高 DSP 吞吐量。并非所有 DSP 任务都会受益于宽向量执行,因此让线程获取和释放 HVX 协处理器非常有意义。高通公司称图像处理是 Hexagon 的关键应用之一,而手机摄像头分辨率的提高可能证明了 HVX 的合理性。
现在,机器学习推动了高通为Hexagon添加了张量单元。与 HVX 一样,张量单元是线程必须请求访问的协处理器。高通没有提供有关寄存器文件大小的详细信息,他们的 Hot Chips 演示重点是使用不同数据类型的权衡。但张量单元的加入显示了Hexagon的可扩展性,以及高通扩大Hexagon作用的决心。
因此,高通最新的 Hexagon 型号覆盖了很大的区域。标量、矢量和张量单元使 DSP 能够处理从音频播放到图像处理再到机器学习的所有事务。然而,挖掘这种潜力将会很困难。
然而,众所周知,Hexagon DSP 很难编程。虽然 Snapdragon CPU 和 GPU 可以分别使用 OpenMP 和 OpenCL 来定位,但 DSP 不存在这样的模型。此外,DSP 是 VLIW 处理器,编写高效的代码来针对此处理范例需要 DSP 架构的特定知识。
除了没有 CPU 甚至 GPU 所享受的软件生态系统之外,Hexagon 最先进的功能还需要特定于架构的编码。分散/聚集和张量计算只能访问 TCM,不能对全局内存进行操作。软件必须承担沉重的负担并管理 TCM 和内存之间的数据移动。直方图计算和 CABAC 解码有专门的指令,但程序员可以通过内在函数或汇编来访问它们。
但如果开发人员付出必要的努力并牺牲理智,Hexagon 可以提供高每时钟吞吐量,同时避免一些 GPU 陷阱。它可能是许多手机任务的正确解决方案。文章来源:https://www.toymoban.com/news/detail-820257.html
九、参考
- Martin Saint-Laurent et al, “A 28 nm DSP Powered by an On-Chip LDO for High-Performance and Energy-Efficient Mobile Applications”
- Qualcomm Hexagon V73 Programmer’s Reference Manual
- Qualcomm Hexagon V73 HVX Programmer’s Reference Manual
- Anthony Cabrera et al, “Toward Performance Portable Programming for Heteogeneous System-on-Chips: Case Study with Qualcomm Snapdragon SoC”
- Lucian Codrescu et al, “Hexagon DSP: An Architecture Optimized for Mobile Multimedia and Communications”
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!文章来源地址https://www.toymoban.com/news/detail-820257.html
到了这里,关于性能优化-高通的Hexagon DSP和NPU的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!