上篇文章记录了 kubeadm 工具搭建 kubernetes 集群的过程,本文记录 K8S 一些核心概念以及各个组件是如何协调工作的。
1. K8S 核心架构

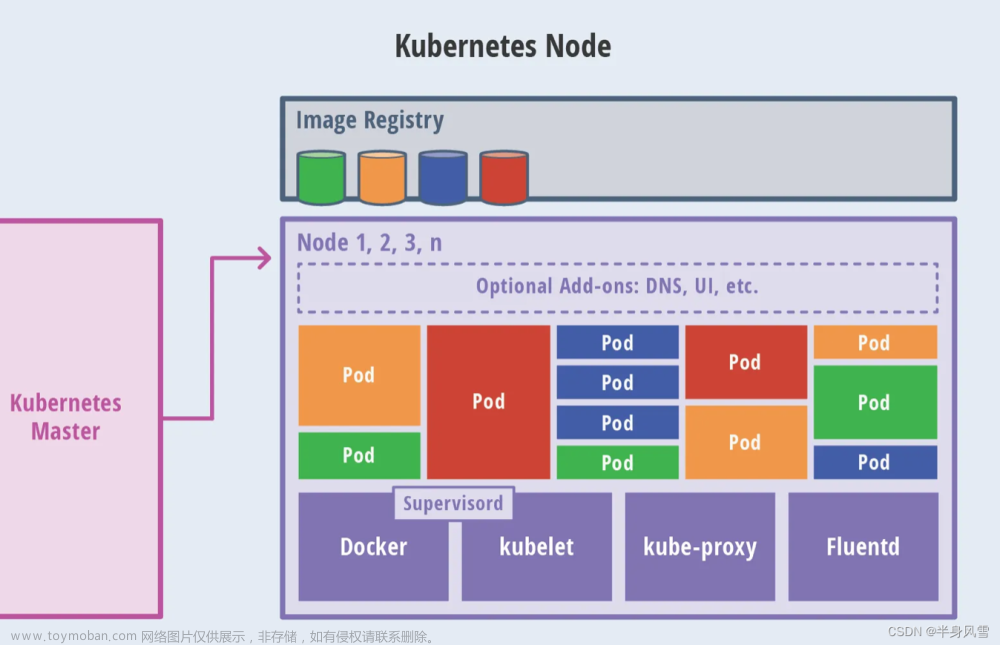
K8S 采用了控制面 / 数据面(Control Plane / Data Plane)架构,集群中的 主机 被称为节点,主机可以是物理机也可以是虚拟机。其中控制节点叫做 master 节点,数据节点叫做 worker 节点。worker 节点工作是靠 master 节点进行管理和调度的,进入节点内部如下图所示。
2. mater 节点核心组件

-
apiserver 是
Master节点中的一个组件,同时也是整个Kubernetes系统的唯一入口,它对外公开了一系列的RESTful API,并且加上了验证、授权等功能,所有其他组件都只能和它直接通信,可以说是Kubernetes里的联络员,如下图所示。

-
etcd 是一个高可用的分布式
Key-Value数据库,用来持久化存储系统里的各种资源对象和状态,相当于Kubernetes里的配置管理员。它只与 apiserver 有直接联系,任何其他组件想要读写 etcd 里的数据都必须经过 apiserver。它存储了Kubernetes对象的所有配置、状态和元数据,包括:pods、secrets、daemonsets、deployment、configmaps、statfulsets等对象。客户端可以通过watch API订阅事件,kubernetes api-servier通过该API跟踪对象状态的变化。所有对象存储在/registry目录下。例如,一个在default命名空间中,名字为nginx的pod,可以在/registry/pods/default/nginx下找到,如下图所示。

-
scheduler 负责容器的编排工作,检查节点的资源状态,把
Pod调度到最适合的节点上运行,scheduler只负责找节点,具体执行还是通过kubelet来执行的。因为节点状态和Pod信息都存储在etcd里,所以scheduler必须通过api-server才能获得。当api-server接收到pod创建请求,controller manager会把pod对象(资源配额是通过controller manager来做的)存储到etcd,scheduler监听到etcd中pod信息的变化,使用调度算法选择合适的节点部署pod,调度信息(pod-node绑定关系)写入etcd中,并告知controller manager,kubelet监听到pod对象信息的变化,发起创建pod请求,创建pod,并将pod状态上报api-server。关于调度策略,
scheduler采用预选和评分的方式来选择pod部署的最佳节点。1.在过滤阶段,调度器会找到适合调度
Pod的节点。根据待调度的Pod需要的资源要求,筛选出满足资源要求的节点。假设有 5 节点可用资源满足Pod的资源要求,那么这 5 个节点可以作为备选。如果没有节点能够满足资源要求,那么Pod是不可调度的,并被移动到调度队列中。如果是一个大型集群,比如有 100 个工作节点,调度器不会遍历所有节点。通过调节参数percentageOfNodesToScore可以指定大型集群调度器遍历的节点比例。默认情况percentageOfNodesToScore=50%,调度器会尝试以round-robin的方式迭代 50% 的节点。如果工作节点分布在多个zone,那么调度器将遍历不同zone中的节点。对于超大型集群,percentageOfNodesToScore的默认值是 5%。
2. 在评分阶段,调度器给过滤后的工作节点打分,并根据分数对节点进行排序。调度程序通过调用多个调度插件进行评分。最后,将选择评分最高的工作节点来调度Pod。如果所有节点的评分相同,则随机选择一个节点进行调度。

-
controller-manager 管理着所有的控制器,使得各个控制器工作在预期的状态下,如果与
etcd中的状态不一致则对资源进行协调操作让实际状态和预期状态达到最终的一致,比如故障检测、自动扩展、滚动更新等。它也必须通过api-server获得存储在etcd里的信息,才能够实现对资源的各种操作。内置的
kubernetes controllers包括:node controller:负责在节点出现故障时发现和响应。replication controller:负责保证集群中一个资源对象Replication Controller所关联的pod副本数始终保持预设值。可理解成确保集群中有且仅有 N 个pod实例,N 是rc中定义的pod副本数量。endpoints controller:填充端点对象(即连接services和pods),负责监听service和对应的pod副本的变化。 可以理解端点是一个服务暴露出来的访问点,如果需要访问一个服务,则必须知道它的endpoint。service account & token controllers:为新的命名空间创建默认帐户和 API 访问令牌。resourceQuota controller:确保指定的资源对象在任何时候都不会超量占用系统物理资源。namespace controller:管理namespace的生命周期。service controller:属于 K8S 集群与外部的云平台之间的一个接口控制器

以上组件都被容器化了,运行在集群的 pod 里,可以通过 kubectl 查看他们的状态。
kubectl get pod -n kube-system # -n kube-system 表示命名空间

3. worker 节点核心组件

-
kubelet 是
Node的代理,负责管理pod的创建(通过监听etcd中pod信息的变化实现),更新和删除,收集node,pod状态上报给api-server。使用集群中配置的CNI插件为pod分配IP地址,并为pod设置必要的网络路由和防火墙规则。

-
kube-proxy 是
node的网络代理,负责管理容器的网络通信,简单来说就是为Pod转发TCP/UDP数据包。通过api-server,获取有关service和endpoints的详细信息。并监视service和endpoint的变化。接着,kube-proxy可以使用以下任何一种代理模式,将流量路由到service绑定的pod。kube-proxy会根据不同配置以不同的模式启动:- iptables 模式
iptables模式是kube-proxy使用的第二代模式,该模式在kubernetes v1.1版本开始支持,从v1.2版本开始成为kube-proxy的默认模式。iptables模式的负载均衡模式是通过底层netfilter/iptables规则来实现的,通过informer机制watch接口实时跟踪service和endpoint的变更事件,并触发对iptables规则的同步更新(来自service配置)。在
iptables模式下,kube-proxy只是作为controller,而不是server,真正服务的是内核的netfilter,体现在用户态的是iptables。所以整体的效率会比userspace模式高,见下图。

- ipvs 模式
ipvs(IP Virtual Server) 实现了传输层负载均衡,也就是 4 层交换,作为 Linux 内核的一部分。ipvs 运行在主机上,在真实服务器前充当负载均衡器。ipvs 可以将基于 TCP 和 UDP 的服务请求转发到真实服务器上,并使真实服务器上的服务在单个 IP 地址上显示为虚拟服务。在 v1.11 版本中正式开始使用。

- ipvs 的优点(具体原因后面 controller 章节会解释)
-
ipvs 为大型集群提供了更好的可拓展性和性能
-
ipvs 支持比 iptables 更复杂的负载均衡算法(包括:最小负载、最少连接、加权等)
-
ipvs 支持服务器健康检查和连接重试等功能
-
可以动态修改 ipset 的集合,即使 iptables 的规则正在使用这个集合
-
**container-runtime **是容器和镜像的实际使用者,在
kubelet的指挥下创建容器,管理Pod的生命周期,是真正工作的程序。(这里的 container-rutime 是 docker,值得注意的是,并不要求一定是 docker,而且 K8S 1.24 开始彻底放弃了 docker 作为 container-runtime)。常见的容器运行时有,cri-o, containerd, docker,对比如下图所示。

以上三个组件只有 kube-proxy 被容器化了,kubelet 作为管理容器的组件容器化会限制它的能力,必须运行在 container-runtime 之外。

4. 组件之间的交互方式
- 每个
Node上的kubelet会定期向apiserver上报节点状态,apiserver再存到etcd里。 - 每个
Node上的kube-proxy实现了TCP/UDP反向代理,让容器对外提供稳定的服务。 -
scheduler通过apiserver得到当前的节点状态,调度Pod,然后apiserver下发命令给某个Node的kubelet,kubelet调用container-runtime启动容器。 -
controller-manager也通过apiserver得到实时的节点状态,监控可能的异常情况,再使用相应的手段去调节恢复。
5. 插件
除了上面的核心组件,kubernetes 集群要完全运行还需要一些其他的组件,比如 CNI 插件,CoreDNS,监控,kubernetes 面板等。文章来源:https://www.toymoban.com/news/detail-820397.html
-
CNI插件,负责为pod分配 IP 地址,并使这些pod能在集群内部相互通信。常见的CNI插件包括calico,flannel等。 -
CoreDNS,充当kubernetes集群内部的DNS服务,可基于该服务实现服务发现。 - 监控,收集集群性能参数和节点资源使用情况。
-
kubernetes面板,通过面板实现集群管理。
6. CNI 插件在集群中是如何工作的
-
Kube-controller-manager会给每个节点分配一个pod CIDR, 每个pod会从pod CIDR拿到一个唯一的 IP 地址。 -
kubelet与容器运行时交互以启动预定义的pod,CRI插件(容器运行时的一部分)和CNI插件交互以配置pod网络。 -
CNI插件使得不同节点之间实现网络访问。
 文章来源地址https://www.toymoban.com/news/detail-820397.html
文章来源地址https://www.toymoban.com/news/detail-820397.html
参考资料
- https://blog.csdn.net/weixin_58544496/article/details/128205060
- https://zhuanlan.zhihu.com/p/669267473
- https://devopscube.com/kubernetes-architecture-explained/
- https://devopscube.com/kubernetes-tutorials-beginners/
- https://devopscube.com/learn-kubernetes-complete-roadmap/#Learn_Ingress_Ingress_Controllers
- https://mikechen.cc/26043.html
- https://blog.csdn.net/qq_45737042/article/details/122089698
- https://zhuanlan.zhihu.com/p/651560930
- https://cloud.tencent.com/developer/article/2363154
- https://blog.csdn.net/youzhouliu/article/details/124860773
- https://v1-28.docs.kubernetes.io/docs/concepts/architecture/
- https://blog.csdn.net/weixin_53072519/article/details/125228115
- https://zhuanlan.zhihu.com/p/490585683
- https://blog.csdn.net/justlpf/article/details/129203746
到了这里,关于K8S 入门实战(3)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!