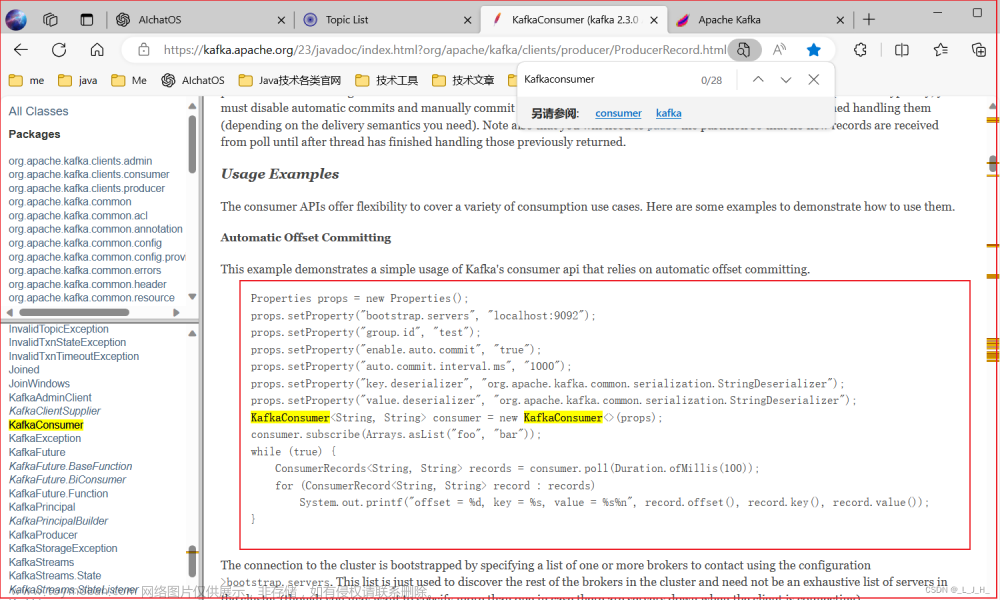
每条消息都有一个与之相关的时间戳(timestamp),可以使用这个时间戳来筛选或消费特定时间范围内的消息。
timestamp()方法获取消息的时间戳,并检查它是否在指定的时间范围内。文章来源:https://www.toymoban.com/news/detail-820431.html
请注意,时间戳是以毫秒为单位的UNIX时间戳。需要根据需要调整start_timestamp和end_timestamp的值。文章来源地址https://www.toymoban.com/news/detail-820431.html
from confluent_kafka import Consumer, KafkaError
def consume_messages_by_timestamp(bootstrap_servers, group_id, topic, start_timestamp, end_timestamp):
consumer_config = {
'bootstrap.servers': bootstrap_servers,
'group.id': group_id,
'auto.offset.reset': 'earliest', # 从最早的偏移量开始消费
}
consumer = Consumer(consumer_config)
# 订阅主题
consumer.subscribe([topic])
try:
while True:
msg = consumer.poll(1.0) # 1秒的超时时间
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
# 到达分区末尾,继续等待消息
continue
else:
print(f"消费者错误: {msg.error()}")
break
# 获取消息的时间戳
timestamp = msg.timestamp()[1]
# 检查消息是否在指定的时间范围内
if start_timestamp <= timestamp <= end_timestamp:
print(f"从主题 '{msg.topic()}' 的分区 '{msg.partition()}' 接收到消息: {msg.value().decode('utf-8')}")
except KeyboardInterrupt:
pass
finally:
# 关闭消费者
consumer.close()
# 示例用法
bootstrap_servers = 'your_kafka_bootstrap_servers'
group_id = 'your_consumer_group_id'
topic = 'your_kafka_topic'
start_timestamp = 1642656000000 # 2022-01-20 00:00:00 in milliseconds
end_timestamp = 1642742399000 # 2022-01-20 23:59:59 in milliseconds
consume_messages_by_timestamp(bootstrap_servers, group_id, topic, start_timestamp, end_timestamp)
到了这里,关于使用时间戳来消费消息(kafka)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!