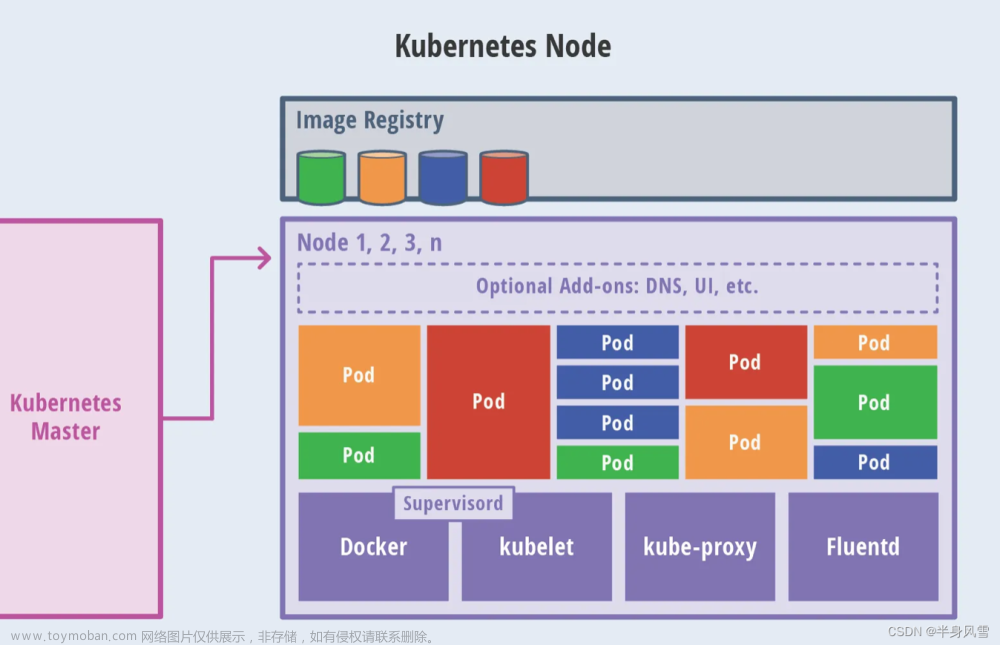
K8S容器编排高级应用
1.Pod控制器
pod控制器帮助我们自动管理pod,并满足期望的pod数量。pod控制器通过label标签来管理pod。在资源文件中通过selector来配置选择器,通过kind来配置控制器。一般我们的应用在生产环境用k8s一定要用pod控制器管理pod而不是自己创建pod这样才能保证可靠性。
版本升级的时候一般通过改资源文件的方式来升级,尽量不要用命令来升级不然资源文件没有改不利于后期维护。
1.pod控制器组成
1.标签选择器
匹配并关联 Pod 资源对象。
2.期望副本数
期望在集群中精确运行着的 Pod 资源的对象数量。
3.pod模板
用于新建 Pod 资源对象的 Pod 模板资源文件。
2.ReplicaSet控制器
rs控制器代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,支持扩缩容,版本升级不支持,需要手动完成,比较老的pod控制器,频繁的版本迭代不要用这种控制器。
3.Deployment控制器
工作在 ReplicaSet 之上,用于管理无状态应用,支持滚动更新(比如1.0版本升级到2.0版本可以无感知升级)和回滚功能,还提供声明式配置。使用deployment控制器会自动创建相关的RS控制器资源。
4.HPA控制器
ReplicaSet控制器和Deployment控制器扩容的时候需要手动完成,HPA控制器Pod可以水平自动缩放,可以根据Pod的负载动态调整Pod的副本数量,业务高峰期自动扩容Pod副本以满足业务请求,在业务低峰期自动缩容Pod,实现节约资源的目的。
部署mertics-server服务来收集和监控k8s的各种指标
1.资源配置
为了能够使用HPA的功能必须要对我们的POD进行资源配置,Kubernetes采用request和limit两种配置类型来对资源进行分配
1.资源配置类型
1.request(资源需求)
运行Pod的节点必须满足运行Pod的最基本需求才能运行Pod
2.limit(资源限额)
运行Pod期间,可能内存使用量会增加,那最多能使用多少内存,这就是资源限额
2.资源单位
1.cpu单位
cpu的单位是核心数。一个容器申请0.5个CPU,就相当于申请1个CPU的一半,你也可以加个后缀m,表示千分之一的概念,比如说100m(100豪)的CPU等价于0.1个CPU。默认情况下就是基于CPU的HPA,需要创建HPA 的资源清单设置最小pod数量和最大pod数量。
2.内存单位
内存单位是内存使用的容量
K、M、G、T、P、E ## 通常是以1000为换算标准的。
Ki、Mi、Gi、Ti、Pi、Ei ## 通常是以1024为换算标准的
3.扩缩容策略
HPA会根据获得的指标数值,应用相应的算法算出一个伸缩系数,此系数是指标的期望值与目前值的比值,如果大于1表示扩容,小于1表示缩容。
1.资源文件主要参数
1.scaleTargetRef:目标作用对象,可以是Deployment、ReplicationController或ReplicaSet
2.averageUtilization:期望每个Pod的CPU使用率都为 10% ,该使用率基于Pod设置的 CPU Request 值进行计算,假如该值为 100m ,那么系统将维持Pod的实际CPU使用值为100m*10%=10m ,超过 10m 就会触发扩容
3.minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个Pod的CPU使用率为10%
2.K8S数据存储
1.数据卷
Docker 可以通过bind将数据持久存储于容器自身文件系统之外的存储空间之中,kubernetes 也支持类似的存储卷功能,不过,其存储卷是与 Pod 资源绑定而非容器。
1.非持久性存储
emptyDir、hostPath
2.网络连接性存储
SAN:iscsi
NFS:nfs、cfs
3.分布式存储
glusterfs、cephfs、rbd
4.云端存储
awsElasticBlockStore、azureDisk、gitRepo
3.pod的调度策略
pod的调度都是通过pod控制器自动完成,但是仍可以通过手动配置的方式进行调度,目的就是让pod的调度符合我们的预期。
1.节点调度
Pod.spec.nodeName 用于强制约束将Pod调度到指定的Node节点上,指定了nodeName的Pod会直接跳过Scheduler的调度逻辑,直接写入PodList列表,该匹配规则是强制匹配。
2.标签调度
也叫定向调度,把pod调度到具有特定标签的node节点的一种调度方式,比如把MySQL数据库调度到具有SSD的node节点以优化数据库性能。需要给指定的node打上标签,并在pod中设置nodeSelector属性以完成pod的指定调度。
4.service的服务发现
在kubernetes中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着不方便直接采用pod的ip对服务进行访问。
kubernetes提供了Service资源,Service会对提供同一个服务的多个pod进行聚合,并且提供一个统一的入口地址,通过访问Service的入口地址就能访问到后面的pod服务。Service通过Label Selector访问Pod组。
1.服务发现原理
真正起作用的其实是kube-proxy服务进程
每个Node节点上都运行着一个kube-proxy服务进程,当创建pod的时候会通过api-server向etcd写入创建的pod的信息,而kube-proxy会基于监听的机制发现这种pod的变动,然后他会将最新的pod的信息告知service我们可以通过service和etcd访问各个pod。service的ip不会变化,pod的ip每次重启不固定。
2.service类型
1. ClusterIp
自动分配一个仅Cluster内部可以访问的虚拟IP
只能内部访问
2.nodeport
在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过: nodeport来访问该服务
可以外部访问
3.LoadBalancer
在NodePort的基础上,借助 Cloud Provider 创建一个外部负载均衡器,并将请求转发到nodeport可以外部访问
4.ExternalName
把集群外部的服务引入到集群内部来,在集群内部直接使用,没有任何类型代理被创建,这只有Kubernetes 1.7或更高版本的kube-dns才支持
5.ingress
Ingress 使用开源的反向代理负载均衡器来实现对外暴漏服务,比如 Nginx、Apache、Haproxy等,用的最多的是使用nginx来做的。
1.ingress优势
1.动态配置
可以自动修改ngnix配置文件,当服务启动时,会自动注册到ingress当中自动添加反向代理
2.减少端口暴露
是k8s的很多服务会以 nodeport 方式映射出去文章来源:https://www.toymoban.com/news/detail-820661.html
2.ingress-nginx原理
1.流程
客户端 – ingress-nginx – service(多个)-- pod (多个)文章来源地址https://www.toymoban.com/news/detail-820661.html
2.工作原理
1.Nginx 对k8s运行的service提供反向代理,在配置文件中配置了域名与service的对应关系并且可以自动化的动态配置。
2.客户端通过使用 DNS 服务或者直接配置本地的 hosts 文件,将域名都映射到 Nginx 代理服务器。
3.当客户端访问时,浏览器会把包含域名的请求发送给 nginx 服务器,nginx 服务器根据传来的域名,选择对应的 Service,然后根据一定的负载均衡策略,选择某个pod接收来自客户端的请求并作出响应
到了这里,关于K8S容器编排高级应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!