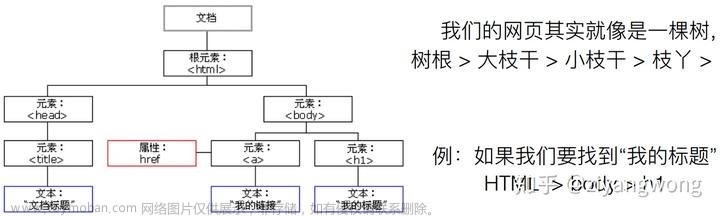
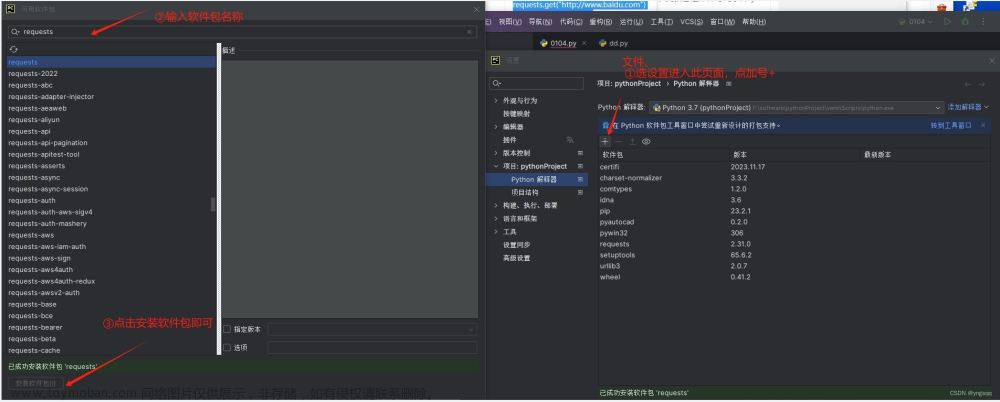
安装第三方模块— requests
完成图片操作后输入:pip install requests
科普:
get:公开数据
post:加密 ,个人信息
进入某音乐网页,打开开发者工具F12

选择网络,再选择—>媒体——>获取URL【先完成刷新页面】
科普:
爬哪个网址?
怎么找视频/音频网址?
都是指URL,并非最上方的地址
把URL复制即可
如下操作:
requests 是一个工具,有get功能,给一个url 得到响应res【看不懂可跳过】
解释:【看不懂没关系!请看下面的代码!可以直接套用】
res=requests.get(url) # 发送请求
print(res.content) # 获取二进制数据
wb 写入 rb 读取
固定代码【可以直接使用】
import requests # 可以直接粘贴
url='刚刚在上面那步获取的URL,请粘贴到这里' # 新手易犯错误:缺少等号(=)
res=requests.get(url) # 可以直接粘贴【前提:上一行代码最左侧是 小写字母url】
print(res.content)# 可以直接粘贴
open('歌曲名【自己打就行】.mp3','wb').write(res.content)# 举例:open('abc哈哈哈.mp3','wb').write(res.content),注意!其余的内容不要修改,只打歌曲名就行
print("下载歌曲成功了!")# 可以直接粘贴
其他解释:下歌曲的后缀是.mp3 下视频的后缀是.mp4
代码是通用的
找到下载的歌曲
1.在你的PyCharm左侧,仔细找一下 你刚刚自己打的歌曲名(XXXXXX.mp3)
2.找到后,鼠标右键——>打开于——>某个地方(如资源管理器)
注意!合法合理使用!爬取数据须遵规!
请学习:相关法律内容文章来源:https://www.toymoban.com/news/detail-820691.html
数据爬虫的合法性边界和法律适用
根据我国刑法规定,突破技术屏障入侵他人计算机系统、获取系统内的数据,可能涉及的罪名包括非法侵入计算机信息系统罪、非法获取计算机信息系统数据罪、破坏计算机信息系统罪。此外,如果利用爬虫技术非法获取公民个人信息,可能触犯侵犯公民个人信息罪。文章来源地址https://www.toymoban.com/news/detail-820691.html
到了这里,关于【超简版,代码可用!】【0基础Python爬虫入门——下载歌曲/视频】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!