往期文章
希望了解更多的道友点这里
0. 分享【脑机接口 + 人工智能】的学习之路
1.1 . 脑电EEG代码开源分享 【1.前置准备-静息态篇】
1.2 . 脑电EEG代码开源分享 【1.前置准备-任务态篇】
2.1 . 脑电EEG代码开源分享 【2.预处理-静息态篇】
2.2 . 脑电EEG代码开源分享 【2.预处理-任务态篇】
3.1 . 脑电EEG代码开源分享 【3.可视化分析-静息态篇】
3.2 . 脑电EEG代码开源分享 【3.可视化分析-任务态篇】
4.1 . 脑电EEG代码开源分享 【4.特征提取-时域篇】
4.2 . 脑电EEG代码开源分享 【4.特征提取-频域篇】
4.3 . 脑电EEG代码开源分享 【4.特征提取-时频域篇】
4.4 . 脑电EEG代码开源分享 【4.特征提取-空域篇】
5 . 脑电EEG代码开源分享 【5.特征选择】
6.1 . 脑电EEG代码开源分享 【6.分类模型-机器学习篇】
6.2 . 脑电EEG代码开源分享 【6.分类模型-深度学习篇】
汇总. 专栏:脑电EEG代码开源分享【文档+代码+经验】
0 . 【深度学习】常用网络总结
一、前言
本文档旨在归纳BCI-EEG-matlab的数据处理代码,作为EEG数据处理的总结,方便快速搭建处理框架的Baseline,实现自动化、模块插拔化、快速化。本文以任务态(锁时刺激,如快速序列视觉呈现)为例,分享脑电EEG的分析处理方法。
脑电数据分析系列。分为以下6个模块:
- 前置准备
- 数据预处理
- 数据可视化
- 特征提取(特征候选集)
- 特征选择(量化特征择优)
- 分类模型
本文内容:【6. 分类模型-深度学习篇】】
提示:以下为各功能代码详细介绍,若节约阅读时间,请下滑至文末的整合代码
二、分类模型 框架介绍
分类模型-深度学习篇主要介绍了 基础 的 网络结构框架 ,将深度学习解决脑电领域问题,形成【BCI + AI】的处理框架,为脑机接口的科研开辟了新赛道、新领域。
如果深入介绍 EEG+深度网络,恐怕3个系列都包含不了,本文作为 脑电+AI 的科普,和大家一起探讨深度网络的应用模式。本文介绍了3种经典模型架构,分别是:图像领域的卷积神经网络(CNN),语音领域的长短时记忆网络(LSTM),社交领域的图神经网络(GNN)。展示了目前神经网络在脑电领域的常用方法,在此框架上优化改进的结构层出不穷,大家可以根据自己的任务需要和数据特点,神经网络的灵活性和模块化方便广大学者尝试和探索。
本文中的3种框架提供了3种思路,为最长程度发挥各神经网络结构自身长处,建议根据每种网络结构特长选择适用的脑电表征形式。例如, CNN 卷积核擅长捕捉图像轮廓和色彩信息,我们可以将脑电输入格式改为 雨谱图、脑地形图等可视化图像呈现方式。例如,LSTM能有效提取时序信号的前后语义特征,脑电信号输入格式应倾向保留原始时序信息。GNN图卷积关注拓补结构,应将脑电数据处理为导联间连接关系。
前文我们花了4篇文章讲完了时域、频域、时频域、空域的特征提取,并应用特征选择方法筛选出了优质特征,终于迎来尾声的分类模型,打通了从原始数据到分类结果的全流程。
分类模型的代码框图、流程如下所示:
分类模型的主要功能,分为以下7部分:
- CNN 卷积神经网络
- LSTM 长短时记忆网络
- GNN 图神经网络
-
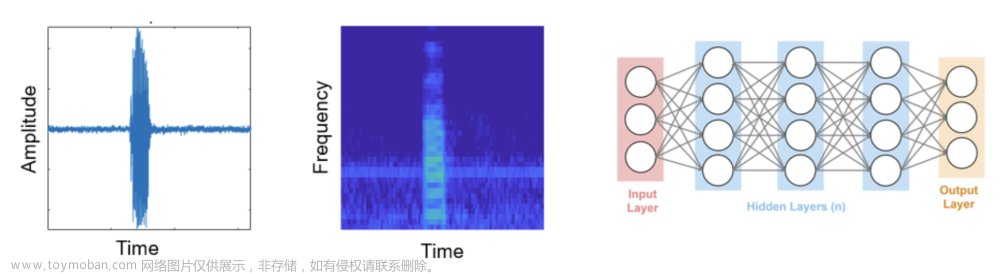
CNN 卷积神经网络:卷积核(滤波器)在图片上方滑动,对相应感受野内的图像信息进行加权求和,经过卷积核处理后的输出为特征图(feature map)。多个不同卷积核分别对图像进行特征提取运算,获得多种角度的特征输出层。一般认为底层的卷积核提取明暗、色彩、轮廓等低级特征,高层的卷积核获得语义、整体的高级特征。大家了解CNN基础后会发现,卷积核一般为方形,尤其适用于计算机视觉的图像处理,因此CNN多应用于图像分析领域。若想将脑电信号也转换为相应的图像形式,推荐大家尝试将各导联脑电数据转换成时频雨谱图,再将雨谱图纵向拼接起来形成格式为 雨谱图 * 导联数,这样卷积核正面扫过的区域就有了脑电的时频图像特征。或者大家希望保留脑电时空特征,可以绘制不同时刻的脑地形图,并将脑电图纵向排列,形成脑地形图 * 时间的格式。总之,卷积核面向的脑电数据尽量具有图像结构。
脑电转换为图片形式输入:
CNN框架举例:
-
LSTM 长短时记忆网络:LSTM提出后称霸语音领域多年,其中心思想保留了RNN(循环神经网络)的前后语义关联性:本输出作为下一阶段输入,特色在于其三扇门:遗忘门,输入门,输出门,可以更长跨距的保留先前输入的信息不被遗忘。本人亲测过LSTM简单结构,在脑电原始信号处理中就很好使。个人经验在脑电领域的LSTM优于CNN,从脑电高分辨率的时序优势也可以理解,推荐大家尝试。注:建议大家入门LSTM时不要苦读代码或者原文,搜索CSDN上的LSTM动图讲解等关键词,极其方便理解。
LSTM原理示意图:
-
GNN 图神经网络:脑电信号是由分布在大脑各个区域的电极采集而来,脑电信号的各个通道之间存在空间关系或者是拓扑信息。图的构造需要3个部分:节点、特征和边集。脑电数据是由许多个电极采集,将分布在大脑不同位置的电极通道作为图的节点。不同的采集设备有不同的通道数,目前常用的有16通道、32通道、64通道和128通道。特征就是每个通道采集的数据,可以是原始采集的数据,也可以是手工提取的特征如PSD、DE特征等。
GNN网络框架举例:
三、脑电特征选择 代码
提示:Python3.8,torch1.9.1提示:入门级框架介绍,之后会出专栏介绍【脑电 + 深度学习】
3.0 参数设置
主要参数设置:
LR学习率:0.0001
Batch_size :128
Epoch :30
Loss损失函数:CrossEntropyLoss
optim优化器:Adam
网络初始化:kaiming_uniform_
运算设备:GPU
3.1 深度网络-基础代码
3.1.1 CNN 卷积网络
重要参数:卷积层数、卷积核尺寸,池化层、激活函数
class my_cnn(nn.Module):
def __init__(self):
super(my_cnn, self).__init__() # 继承__init__功能
# 第一层卷积
self.feature = nn.Sequential(
#1
nn.Conv2d(
in_channels=16,
out_channels=24,
#kernel_size=(param[para_loop][0],param[para_loop][1]),
kernel_size=(9,7),
stride=1,
padding = (0,0),
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2,2)),
#2
nn.Conv2d(
in_channels=24,
out_channels=28,
kernel_size=(12,8),
stride=1,
padding = (0,0),
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(4,4)),
#3
nn.Conv2d(
in_channels=28,
out_channels=32,
kernel_size=(6,4),
stride=1,
padding = (0,0),
),
nn.ReLU(),
# nn.MaxPool2d(kernel_size=(2,2)),
)
self.classification = nn.Sequential(
# nn.Dropout(p=0.5),
#nn.Linear(in_features=16 * param[para_loop][2] * param[para_loop][3], out_features=64),
nn.Linear(in_features=32 * 3 * 2, out_features=32), # nn.Dropout(p=0.5),
# nn.Dropout(p=0.5),
nn.Linear(in_features=32 , out_features=2),
)
def forward(self, x):
x = self.feature(x)
temp = x.view(x.shape[0], -1)
output = self.classification(temp)
return output, x
# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device ="cpu"
cnn_model = my_cnn().to(device)
print(cnn_model)
3.1.2 LSTM 长短时记忆网络
LSTM网络-网络框架核心代码:
# 定义LSTM网络模型
class my_lstm(nn.Module):
def __init__(self):
super(my_lstm, self).__init__()
self.rnn = nn.LSTM( # if use nn.RNN(), it hardly learns
input_size=INPUT_SIZE, # 输入维度
hidden_size=50, # 隐藏层神经元节点个数
num_layers=2, # 神经元层数
batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
bidirectional = True,
)
self.out =nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(100, 2) ,
)
def forward(self, x):
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size)
# h_c shape (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # h_n就是h状态,h_c就是细胞的状态
# choose r_out at the last time step
out = self.out(r_out[:, -1, :]) # 我们只要每一个time_step里的最后的一个。比如64个矩阵,每个28*28,我们只要每一个的第28次的那个数据。
return out
device = torch.device("cuda:3" if torch.cuda.is_available() else "cpu")
lstm_model = my_lstm().to(device)
print(lstm_model)
3.1.3 GNN-图卷积网络
GCN图卷积神经网络-网络框架核心代码:
import numpy as np
class Graph():
""" The Graph to model the skeletons extracted by the openpose
Args:
strategy (string): must be one of the follow candidates
- uniform: Uniform Labeling
- distance: Distance Partitioning
- spatial: Spatial Configuration
For more information, please refer to the section 'Partition Strategies'
in our paper (https://arxiv.org/abs/1801.07455).
layout (string): must be one of the follow candidates
- openpose: Is consists of 18 joints. For more information, please
refer to https://github.com/CMU-Perceptual-Computing-Lab/openpose#output
- ntu-rgb+d: Is consists of 25 joints. For more information, please
refer to https://github.com/shahroudy/NTURGB-D
max_hop (int): the maximal distance between two connected nodes
dilation (int): controls the spacing between the kernel points
"""
def __init__(self,
layout='openpose',
strategy='uniform',
max_hop=1,
dilation=1):
self.max_hop = max_hop
self.dilation = dilation
self.get_edge(layout)
self.hop_dis = get_hop_distance(
self.num_node, self.edge, max_hop=max_hop)
self.get_adjacency(strategy)
def __str__(self):
return self.A
def get_edge(self, layout):
if layout == 'openpose':
self.num_node = 18
self_link = [(i, i) for i in range(self.num_node)]
neighbor_link = [(4, 3), (3, 2), (7, 6), (6, 5), (13, 12), (12,
11),
(10, 9), (9, 8), (11, 5), (8, 2), (5, 1), (2, 1),
(0, 1), (15, 0), (14, 0), (17, 15), (16, 14)]
self.edge = self_link + neighbor_link
self.center = 1
elif layout == 'ntu-rgb+d':
self.num_node = 25
self_link = [(i, i) for i in range(self.num_node)]
neighbor_1base = [(1, 2), (2, 21), (3, 21), (4, 3), (5, 21),
(6, 5), (7, 6), (8, 7), (9, 21), (10, 9),
(11, 10), (12, 11), (13, 1), (14, 13), (15, 14),
(16, 15), (17, 1), (18, 17), (19, 18), (20, 19),
(22, 23), (23, 8), (24, 25), (25, 12)]
neighbor_link = [(i - 1, j - 1) for (i, j) in neighbor_1base]
self.edge = self_link + neighbor_link
self.center = 21 - 1
elif layout == 'ntu_edge':
self.num_node = 24
self_link = [(i, i) for i in range(self.num_node)]
neighbor_1base = [(1, 2), (3, 2), (4, 3), (5, 2), (6, 5), (7, 6),
(8, 7), (9, 2), (10, 9), (11, 10), (12, 11),
(13, 1), (14, 13), (15, 14), (16, 15), (17, 1),
(18, 17), (19, 18), (20, 19), (21, 22), (22, 8),
(23, 24), (24, 12)]
neighbor_link = [(i - 1, j - 1) for (i, j) in neighbor_1base]
self.edge = self_link + neighbor_link
self.center = 2
# elif layout=='customer settings'
# pass
else:
raise ValueError("Do Not Exist This Layout.")
#计算邻接矩阵A
def get_adjacency(self, strategy):
valid_hop = range(0, self.max_hop + 1, self.dilation) #range(start,stop,step)
adjacency = np.zeros((self.num_node, self.num_node))
for hop in valid_hop:
adjacency[self.hop_dis == hop] = 1
normalize_adjacency = normalize_digraph(adjacency)
unnormalize_adjacency = normalize_undigraph(adjacency)
if strategy == 'uniform':
A = np.zeros((1, self.num_node, self.num_node))
A[0] = normalize_adjacency
self.A = A
elif strategy == 'distance':
A = np.zeros((len(valid_hop), 18, 18))
for i, hop in enumerate(valid_hop):
A[i][self.hop_dis == hop] = normalize_adjacency[self.hop_dis ==
hop]
self.A = A
elif strategy == 'spatial':
A = []
for hop in valid_hop:
a_root = np.zeros((self.num_node, self.num_node))
a_close = np.zeros((self.num_node, self.num_node))
a_further = np.zeros((self.num_node, self.num_node))
for i in range(self.num_node):
for j in range(self.num_node):
if self.hop_dis[j, i] == hop:
if self.hop_dis[j, self.center] == self.hop_dis[
i, self.center]:
a_root[j, i] = normalize_adjacency[j, i]
elif self.hop_dis[j, self.
center] > self.hop_dis[i, self.
center]:
a_close[j, i] = normalize_adjacency[j, i]
else:
a_further[j, i] = normalize_adjacency[j, i]
if hop == 0:
A.append(a_root)
else:
A.append(a_root + a_close)
A.append(a_further)
A = np.stack(A)
self.A = A
else:
raise ValueError("Do Not Exist This Strategy")
# 此函数的返回值hop_dis就是图的邻接矩阵
def get_hop_distance(num_node, edge, max_hop=1):
A = np.zeros((num_node, num_node))
for i, j in edge:
A[j, i] = 1
A[i, j] = 1
# compute hop steps
hop_dis = np.zeros((num_node, num_node)) + np.inf # np.inf 表示一个无穷大的正数
# np.linalg.matrix_power(A, d)求矩阵A的d幂次方,transfer_mat矩阵(I,A)是一个将A矩阵拼接max_hop+1次的矩阵
transfer_mat = [np.linalg.matrix_power(A, d) for d in range(max_hop + 1)]
# (np.stack(transfer_mat) > 0)矩阵中大于0的返回Ture,小于0的返回False,最终arrive_mat是一个布尔矩阵,大小与transfer_mat一样
arrive_mat = (np.stack(transfer_mat) > 0)
# range(start,stop,step) step=-1表示倒着取
for d in range(max_hop, -1, -1):
# 将arrive_mat[d]矩阵中为True的对应于hop_dis[]位置的数设置为d
hop_dis[arrive_mat[d]] = d
return hop_dis
# 将矩阵A中的每一列的各个元素分别除以此列元素的形成新的矩阵
def normalize_digraph(A):
Dl = np.sum(A, 0) #将矩阵A压缩成一行
num_node = A.shape[0]
Dn = np.zeros((num_node, num_node))
for i in range(num_node):
if Dl[i] > 0:
Dn[i, i] = Dl[i]**(-1)
AD = np.dot(A, Dn)
return AD
def normalize_undigraph(A):
Dl = np.sum(A, 0)
num_node = A.shape[0]
Dn = np.zeros((num_node, num_node))
for i in range(num_node):
if Dl[i] > 0:
Dn[i, i] = Dl[i]**(-0.5)
DAD = np.dot(np.dot(Dn, A), Dn)
return DAD
总结
科学家认为深度学习目前的瓶颈需要人脑结构的启发,类脑智能逐渐兴起,
人脑智能的感知能力 + 机器智能的高效处理,混合智能在不断探索。
深度学习+脑机交互 提供了新的结合和思路,
深度网络作为工具用于脑电数据的分类和解码仅是浅层应用。
深度网络结构为研究人员提供了很大的灵活性和自由度,
在大数据的数据驱动模式下可以获得优异性能。
matlab 可视化友好,python 搭建网络友好,
建议新手在数据处理及可视化阶段使用Matlab 分析查看数据,
搭建网络时使用pytorch构建深度网络框架,可以较大发挥各平台的优势。
囿于能力,挂一漏万,如有笔误请大家指正~
感谢您耐心的观看,本系列更新了约30000字,约3000行开源代码,体量相当于一篇硕士工作。
往期内容放在了文章开头,麻烦帮忙点点赞,分享给有需要的朋友~
坚定初心,本博客永远:
免费拿走,全部开源,全部无偿分享~
To:新想法、鬼点子的道友:
自己:脑机接口+人工智领域,主攻大脑模式解码、身份认证、仿脑模型…
在读博士第3年,在最后1年,希望将代码、文档、经验、掉坑的经历分享给大家~
做的不好请大佬们多批评、多指导~ 虚心向大伙请教!
想一起做些事情 or 奇奇怪怪点子 or 单纯批评我的,请至Rongkaizhang_bci@163.com文章来源:https://www.toymoban.com/news/detail-820773.html
 )文章来源地址https://www.toymoban.com/news/detail-820773.html
)文章来源地址https://www.toymoban.com/news/detail-820773.html
到了这里,关于脑电EEG代码开源分享 【6. 分类模型-深度学习篇】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!