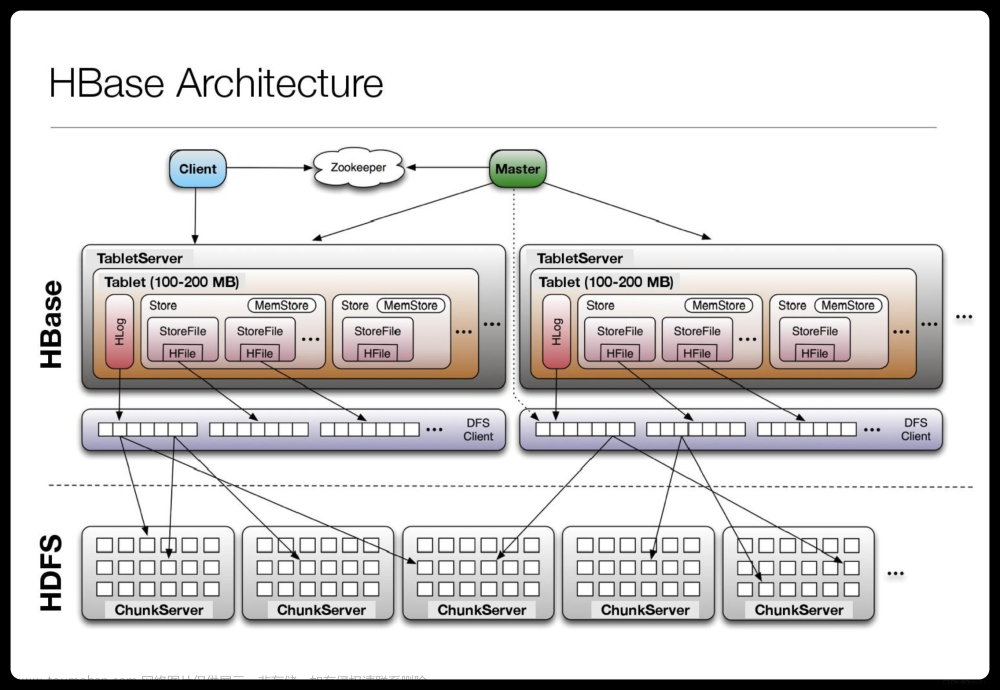
首先保证Zookeeper和Hadoop正常运行
一、解压压缩包
[hadoop@hadoop102 software]$ tar -zxvf hbase-2.4.11-bin.tar.gz -C /opt/module/
二、配置环境变量
[hadoop@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.4.11
export PATH=$PATH:$HBASE_HOME/bin
使环境变量生效:
[hadoop@hadoop102 software]$ source /etc/profile.d/my_env.sh
三、修改配置文件
3.1 修改hbase-env.sh
不使用hbase内置的zookeeper,使用独立zookeeper
[hadoop@hadoop102 conf]$ vim /opt/module/hbase-2.4.11/conf/hbase-env.sh
内容:
export HBASE_MANAGES_ZK=false
3.2 修改hbase-site.xml
表明zookeeper集群,hbase web访问路径
[hadoop@hadoop102 conf]$ vim /opt/module/hbase-2.4.11/conf/hbase-site.xml
内容:
<!-- 分布式部署 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 默认配置 -->
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- zookeeper集群地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<!-- 用来持久化HBase的数据,一般设置的是hdfs的文件目录(需要和hadoop的core-site.xml保持一致) -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:9820/hbase</value>
</property>
<!-- WAL配置 -->
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
3.3 修改regionservers
regionserver所在机器
[hadoop@hadoop102 conf]$ vim /opt/module/hbase-2.4.11/conf/regionservers
内容:
hadoop102
hadoop103
hadoop104
四、解决HBase和Hadoop的log4j兼容性问题,使用Hadoop的jar包
[hadoop@hadoop102 conf]$ mv /opt/module/hbase-2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase-2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
五、HBase远程发送到其他集群
[hadoop@hadoop102 conf]$ mytools_rsync /opt/module/hbase-2.4.11/
六、启动
[hadoop@hadoop102 hbase-2.4.11]$ bin/start-hbase.sh
七、停止
bin/stop-hbase.sh
八、基本操作
8.1 进入Hbase客户端
[hadoop@hadoop102 hbase-2.4.11]$ bin/hbase shell
8.2 namespace
hbase:003:0> create_namespace 'first_namespace'
hbase:004:0> list_namespace
8.3 DDL
8.3.1 创建表
在first_namespace命名空间中创建表格student,两个列族。info列族数据维护的版本数为5个,如果不写默认版本数为1。
hbase:009:0> create 'first_namespace:student', {NAME => 'info', VERSIONS => 5}, {NAME => 'msg'}
hbase:022:0> create 'first_namespace:student01', {NAME => 'info', VERSIONS => 5}, {NAME => 'msg'}
8.3.2 查看表
hbase:015:0> describe 'first_namespace:student'
8.3.3 修改表
表名创建时写的所有和列族相关的信息,都可以后续通过alter修改,包括增加删除列族。
# 修改列族
hbase:016:0> alter 'first_namespace:student', {NAME => 'msg', VERSIONS => 3}
# 新增列族
hbase:018:0> alter 'first_namespace:student', {NAME => 'msg01', VERSIONS => 3}
# 删除列族
hbase:020:0> alter 'first_namespace:student', NAME => 'msg01', METHOD => 'delete'
8.3.4 删除表
shell中删除表格,需要先将表格状态设置为不可用。
hbase:024:0> disable 'first_namespace:student01'
hbase:025:0> drop 'first_namespace:student01'
8.4 DML
8.4.1 写入数据
在HBase中如果想要写入数据,只能添加结构中最底层的cell。可以手动写入时间戳指定cell的版本,推荐不写默认使用当前的系统时间。
hbase:027:0> put 'first_namespace:student','1001','info:name','zhangsan'
hbase:028:0> put 'first_namespace:student','1001','info:name','lisi'
hbase:029:0> put 'first_namespace:student','1001','info:age','18'
如果重复写入相同rowKey,相同列的数据,会写入多个版本进行覆盖。
8.4.2 读取数据
读取数据的方法有两个:get和scan。
get最大范围是一行数据,也可以进行列的过滤,读取数据的结果为多行cell。
hbase:030:0> get 'first_namespace:student','1001'
hbase:031:0> get 'first_namespace:student','1001' , {COLUMN => 'info:name'}
也可以修改读取cell的版本数,默认读取一个。最多能够读取当前列族设置的维护版本数。
hbase:032:0> get 'first_namespace:student','1001' , {COLUMN => 'info:name', VERSIONS => 6}
scan是扫描数据,能够读取多行数据,不建议扫描过多的数据,推荐使用startRow和stopRow来控制读取的数据,默认范围左闭右开。
hbase:036:0> scan 'first_namespace:student',{STARTROW => '1001',STOPROW => '1002'}
8.4.3 删除数据
删除数据的方法有两个:delete和deleteall。
执行命令会标记数据为要删除,不会直接将数据彻底删除,删除数据只在特定时期清理磁盘时进行
delete删除最新的一个版本。老版本会显示出来
hbase:037:0> delete 'first_namespace:student','1001','info:name'
deleteall删除当前列所有版本的数据,即为当前行当前列的多个cell。
hbase:039:0> deleteall 'first_namespace:student','1001','info:name'
deleteall删除当前列族数据
hbase:006:0> deleteall 'first_namespace:student','1001'
hbase:011:0> quit
九、访问WEB页面
http://hadoop102:16010/
十、HBASE API
10.1 环境准备
新建项目后在pom.xml中添加依赖:
注意:会报错javax.el包不存在,是一个测试用的依赖,不影响使用
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.4.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.1-b06</version>
</dependency>
</dependencies>
10.2 创建连接
根据官方API介绍,HBase的客户端连接由ConnectionFactory类来创建,用户使用完成之后需要手动关闭连接。同时连接是一个重量级的,推荐一个进程使用一个连接,对HBase的命令通过连接中的两个属性Admin和Table来实现。
10.2.1 单线程创建连接
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.AsyncConnection;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.CompletableFuture;
public class HBaseConnect {
public static void main(String[] args) throws IOException {
// 1. 创建配置对象
Configuration conf = new Configuration();
// 2. 添加配置参数
conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");
// 3. 创建hbase的连接
// 默认使用同步连接
Connection connection = ConnectionFactory.createConnection(conf);
// 可以使用异步连接
// 主要影响后续的DML操作
CompletableFuture<AsyncConnection> asyncConnection = ConnectionFactory.createAsyncConnection(conf);
// 3. 使用连接2
System.out.println(connection);
// 5. 关闭连接
connection.close();
}
}
10.2.2 多线程创建连接
使用类单例模式,确保使用一个连接,可以同时用于多个线程。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.AsyncConnection;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.CompletableFuture;
public class HBaseConnect {
// 设置静态属性hbase连接
public static Connection connection = null;
static {
// 创建hbase的连接
try {
// 使用配置文件的方法
connection = ConnectionFactory.createConnection();
} catch (IOException e) {
System.out.println("连接获取失败");
e.printStackTrace();
}
}
/**
* 连接关闭方法,用于进程关闭时调用
* @throws IOException
*/
public static void closeConnection() throws IOException {
if (connection != null) {
connection.close();
}
}
}
在resources文件夹中创建配置文件hbase-site.xml,添加以下内容文章来源:https://www.toymoban.com/news/detail-821214.html
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
</configuration>
10.3 操作数据
创建类HBaseDML文章来源地址https://www.toymoban.com/news/detail-821214.html
public class HBaseDML {
// 添加静态属性connection指向单例连接
public static Connection connection = HBaseConnect.connection;
}
10.3.1 建表&删表
public static void createTable(Connection conn,String namespace,String tableName,String...families){
if(families.length < 1){
System.out.println("建表必须指定列族");
return;
}
try (Admin admin = conn.getAdmin()){
TableName tableNameObj = TableName.valueOf(namespace, tableName);
if(admin.tableExists(tableNameObj)){
System.out.println("~~要创建的表已经存在~~");
return;
}
List<ColumnFamilyDescriptor> cfdList = new ArrayList();
for (String family : families) {
ColumnFamilyDescriptor familyDescriptor = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(family)).build();
cfdList.add(familyDescriptor);
}
TableDescriptor desc = TableDescriptorBuilder
.newBuilder(tableNameObj)
.setColumnFamilies(cfdList)
.build();
admin.createTable(desc);
} catch (IOException e) {
e.printStackTrace();
}
}
//删表
public static void dropTable(Connection conn,String namespace,String tableName){
try (Admin admin = conn.getAdmin()){
TableName tableNameObj = TableName.valueOf(namespace, tableName);
if(!admin.tableExists(tableNameObj)){
System.out.println("~~要删除的表不存在~~");
return;
}
admin.disableTable(tableNameObj);
admin.deleteTable(tableNameObj);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception{
Connection conn = getConnection();
// createTable(getConnection(),"bigdata","student2","info","msg");
// dropTable(getConnection(),"bigdata","student2");
closeConnection(conn);
}
10.3.2 插入数据
//向表中添加|更新数据
public static void putCell(Connection conn,String nameSpace,String tableName,String rowKey,String family,String column,String value){
// 1.获取table
try (Table table = conn.getTable(TableName.valueOf(nameSpace, tableName))){
// 2.创建Put对象
Put put = new Put(Bytes.toBytes(rowKey));
// 3.添加put属性
put.addColumn(Bytes.toBytes(family),Bytes.toBytes(column),Bytes.toBytes(value));
// 3.put数据
table.put(put);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception{
Connection conn = getConnection();
putCell(conn,"bigdata","student2","1001","info","name","zhangsan");
putCell(conn,"bigdata","student2","1002","info","name","lisi");
putCell(conn,"bigdata","student2","1003","info","name","wangwu");
closeConnection(conn);
}
10.3.3 查询数据
public static void getCell(Connection conn, String nameSpace, String tableName, String rowKey, String family, String column) {
// 1.获取table
try (Table table = conn.getTable(TableName.valueOf(nameSpace, tableName))) {
// 2.获取Get对象
Get get = new Get(Bytes.toBytes(rowKey));
// 3.添加get属性
get.addColumn(Bytes.toBytes(family), Bytes.toBytes(column));
// 3.get数据
// 简便用法
// byte[] bytes = table.get(get).value();
//String value = new String(bytes);
// 复杂用法
// 3.1 获取result
Result result = table.get(get);
// 3.2 获取cells
Cell[] cells = result.rawCells();
// 3.3 遍历cells
String value = "";
for (Cell cell : cells) {
// 3.4 输出每个cell
System.out.println(Bytes.toString(CellUtil.cloneQualifier(cell)) + ":"
+Bytes.toString(CellUtil.cloneValue(cell)));
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception{
Connection conn = getConnection();
getCell(getConnection(), "bigdata", "student2", "1001", "info", "name");
closeConnection(conn);
}
10.3.4 扫描数据
public static void scanRows(Connection conn,String nameSpace, String tableName, String startRow, String stopRow){
TableName tableNameObj = TableName.valueOf(nameSpace, tableName);
try (Table table = conn.getTable(tableNameObj)){
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(startRow));
scan.withStopRow(Bytes.toBytes(stopRow));
ResultScanner resultScanner = table.getScanner(scan);
for (Result result : resultScanner) {
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
System.out.println(Bytes.toString(result.getRow()) +
":" +Bytes.toString(CellUtil.cloneQualifier(cell)) +
":" +Bytes.toString(CellUtil.cloneValue(cell)));
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception{
Connection conn = getConnection();
scanRows(getConnection(), "bigdata", "student2", "1001", "1004");
closeConnection(conn);
}
10.3.5 带过滤扫描
public static void scanRowsByFilter(Connection conn,String nameSpace, String tableName,
String columnFamily,String column,String value,
String startRow, String stopRow){
TableName tableNameObj = TableName.valueOf(nameSpace, tableName);
try (Table table = conn.getTable(tableNameObj)){
Scan scan = new Scan();
// 创建过滤器列表
// 默认过滤所有,可以选择过滤出一个
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
// 列值过滤器 过滤出单列数据
ColumnValueFilter columnValueFilter = new ColumnValueFilter(
// 列族
Bytes.toBytes(columnFamily),
// 列名
Bytes.toBytes(column),
// 匹配规则 一般为相等 也可以是大于等于 小于等于
CompareOperator.EQUAL,
Bytes.toBytes(value)
);
// 单列值过滤器
// 过滤出符合添加的整行数据 结果包含其他列
//注意:如果表中的一行数据没有查询的列,也会将这行数据查询出来
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
// 列族
Bytes.toBytes(columnFamily),
// 列名
Bytes.toBytes(column),
// 匹配规则 一般为相等 也可以是大于等于 小于等于
CompareOperator.EQUAL,
Bytes.toBytes(value)
);
filterList.addFilter(columnValueFilter);
filterList.addFilter(singleColumnValueFilter);
// 可以设置多个 需放入到过滤器列表中
scan.setFilter(filterList);
scan.withStartRow(Bytes.toBytes(startRow));
scan.withStopRow(Bytes.toBytes(stopRow));
ResultScanner resultScanner = table.getScanner(scan);
for (Result result : resultScanner) {
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
System.out.println(Bytes.toString(result.getRow()) +
":" +Bytes.toString(CellUtil.cloneQualifier(cell)) +
":" +Bytes.toString(CellUtil.cloneValue(cell)));
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception{
Connection conn = getConnection();
scanRowsByFilter(getConnection(), "bigdata", "student2",
"info","name","zhangsan" ,"1001", "1004");
closeConnection(conn);
}
10.3.6 删除数据
public static void deleteColumn(Connection conn, String nameSpace, String tableName, String rowKey, String family, String column) {
// 1.获取table
try (Table table = conn.getTable(TableName.valueOf(nameSpace, tableName))) {
// 2.创建Delete对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
// 3.添加删除信息
// 3.1 删除最新版本 标记为delete
// delete.addColumn(Bytes.toBytes(family),Bytes.toBytes(column));
// 3.2 删除所有版本 标记为DeleteColumn
// delete.addColumns(Bytes.toBytes(family), Bytes.toBytes(column));
// 3.3 删除指定列族 标记为deleteFamily
// delete.addFamily(Bytes.toBytes(family));
// 3.4 什么也不加 删除所有列族
// 3.删除数据
table.delete(delete);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception{
Connection conn = getConnection();
deleteColumn(conn,"bigdata", "student2", "1001", "info", "name");
closeConnection(conn);
}
到了这里,关于大数据基础设施搭建 - Hbase的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!