【简介】本篇博客为爱冲锋,爬取北京全部高校的全部招生信息,最后持久化存储为表格形式,可以用作筛选高校。
1. 导入依赖
此处导入本次爬虫所需要的全部依赖包分别是以下内容,本篇博客将爬取研招网北京所有高校的招生信息,主要爬取内容为学校,考试方式,所在学院,专业,研究方向,招生人数,备注,考试科目等相关信息
import random
from time import sleep
import pandas as pd
import requests
from lxml import etree # 导包
2. 代码详解
2.1 def __init __ (self)
本次我们将爬虫的代码封装成一个类,当作练习。
此处我们初始化相关内容:agent :该列表种存放UA伪装池,在该伪装池中随机获取一个params :这是一个用来存放GET请求所携带的参数,以便于访问各个页面headers:用来存放UA伪装的字典all:这是一个列表用来暂时存放每次爬取到的页面数据
def __init__(self):
# UA池
agent = [
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
]
# get请求所携带参数
self.params = {}
self.headers = {}
self.params['ssdm'] = 11 # 地区代码
self.params['dwmc'] = "" # 高校名称
self.params['mldm'] = ""
self.params['mlmc'] = ""
self.params['yjxkdm'] = "" # 专业代码
self.params['zymc'] = ""
self.params['xxfs'] = ""
self.params['pageno'] = ""
# UA伪装
self.headers["User-Agent"] = random.choice(agent)
# 用来存放页面所爬取的数据
self.all = []
2.2 def SleepTime(self):
该方法用于随机一个浮点数的时间,用于模拟随机访问,以防止访问过快,服务器拒绝访问。
其中uniform( )函数,random.uniform(x, y) 方法将随机生成一个实数,它在 [x,y] 范围内。
def SleepTime(self):
"""
延迟方法
防止访问过快,服务器拒绝访问
"""
t = random.uniform(1, 3)
print(f'将延迟{t}s')
sleep(t)
2.3 def Getcode(self):
由于我们要爬取北京所有高校的信息,所以我们需要所有的专业代码,作为访问所携带的参数。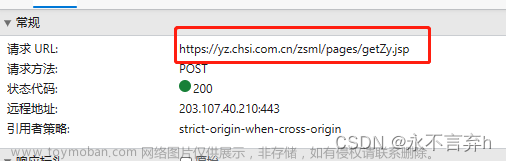
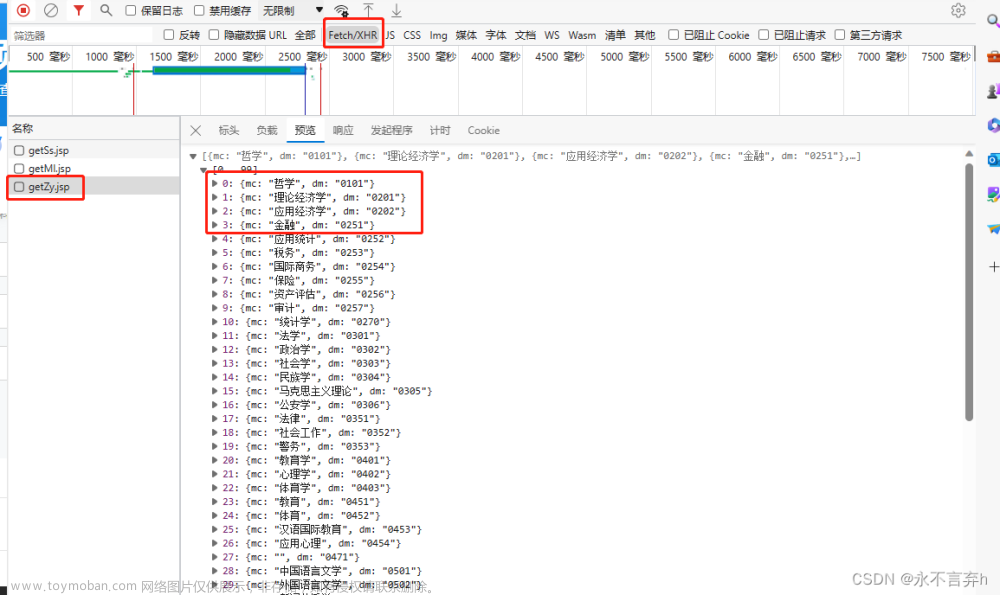
我们通过抓包工具可以发现所有的专业代码在该请求的URL下,所获取的json文件,接下来我们对这个URL发请求,在解析一下数据,即可获得所有的专业代码。
这里我们复习一下如何将列表数据存入TXT文件:
参考博客:[http://t.csdn.cn/badHK]
def Getcode(self):
"""
获取专业代码
获取页面数据中所有专业代码
"""
url = "https://yz.chsi.com.cn/zsml/pages/getZy.jsp"
data_list = requests.get(url, headers=self.headers).json()
for data in data_list:
print(data['dm'])
fp = open(f"E:/PythonCode/yjy_select_school_plus/dm.txt", 'w', newline='', encoding='utf-8')
for i in range(len(data_list)):
tmp = data_list[i]['dm'] + '\n'
fp.write(tmp)
2.4 def ReadTxt(self, file):
这里写一个方法,方便后续读取txt文件。其中file 是文件名作为参数
def ReadTxt(self, file):
"""读取txt"""
data = []
fp = open(f'E:/PythonCode/yjy_select_school_plus/{file}.txt', 'r', encoding='utf-8')
line = fp.readline().strip()
data.append(line)
while line:
line = fp.readline().strip()
data.append(line)
fp.close()
return data
2.5 def GetDeData(self, page):
这里就是最重要的爬取页面信息部分,我们会先获取page页码,将作为参数传入。在最外层循环遍历每一个页面,将全部参数加入我们要访问的url中,因为每一个页面最多只有30个数据,如果没有30个或者页面为空都会抛出IndexError的异常,此处我们做了异常的处理。最后使用Xpath解析页面数据,做一个字典存放入all列表中。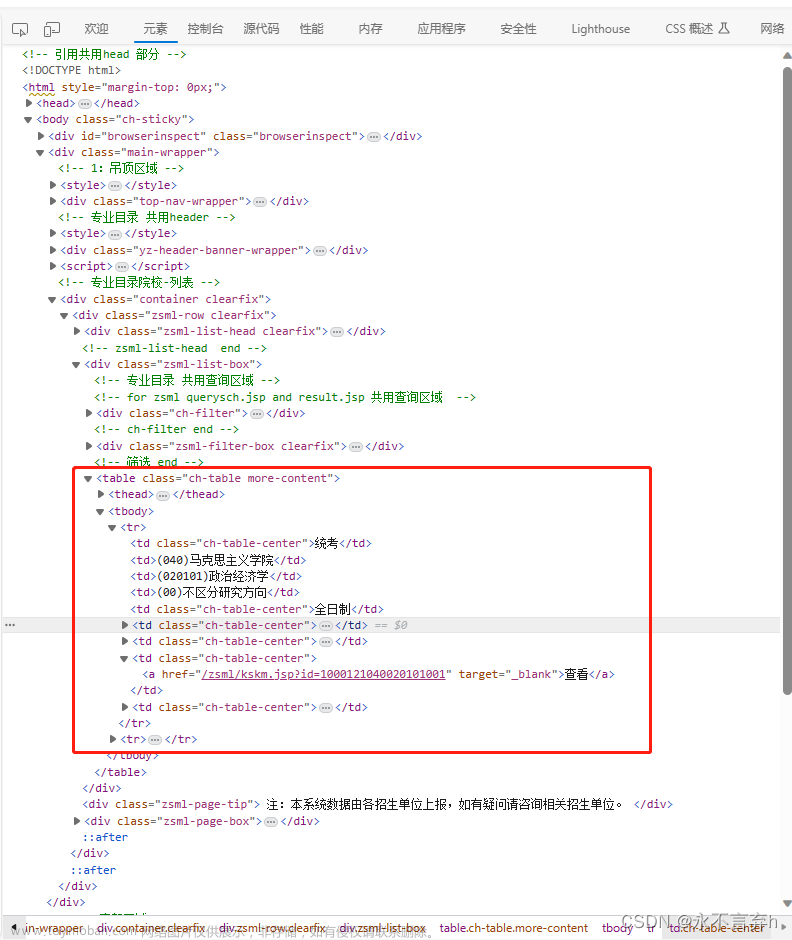
通过查看页面源码可以发现,我们所需要的数据在<tbody>标签下的<tr> 并且,该专业的详情是在<a>标签下的href,通过拼接url:next_url = f"https://yz.chsi.com.cn{next_url}"发出请求方可进入该页面。在使用同样的方法就可以获取到查看下面的信息。
def GetDeData(self, page):
"""获取详情"""
for page in range(1, page + 1):
self.params["pageno"] = f"{page}"
url = f"""https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm={self.params["ssdm"]}&dwmc={self.params["dwmc"]}&mldm={self.params["mldm"]}&mlmc={self.params["mlmc"]}&yjxkdm={self.params["yjxkdm"]}&zymc={self.params["zymc"]}&xxfs={self.params["xxfs"]}&pageno={self.params["pageno"]}"""
print(url)
data_xpath = requests.get(url.format(**self.params), headers=self.headers).content.decode("utf-8")
tree = etree.HTML(data_xpath)
for i in range(1, 31):
try:
next_url = tree.xpath(f"//tr[{i}]/td[8]/a/@href")[0]
next_url = f"https://yz.chsi.com.cn{next_url}"
next_data_xpath = requests.get(next_url, headers=self.headers).content.decode("utf-8")
next_tree = etree.HTML(next_data_xpath)
tmp = {
"学校": self.params["dwmc"],
"考试方式": tree.xpath(f"//tr[{i}]/td[1]/text()")[0],
"所在学院": tree.xpath(f"//tr[{i}]/td[2]/text()")[0],
"专业": tree.xpath(f"//tr[{i}]/td[3]/text()")[0],
"研究方向": tree.xpath(f"//tr[{i}]/td[4]/text()")[0],
"学习方式": tree.xpath(f"//tr[{i}]/td[5]/text()")[0],
"招生人数": tree.xpath(f"//tr[{i}]/td[7]/script/text()")[0].strip().split("'")[1],
"备注": tree.xpath(f"//tr[{i}]/td[9]/script/text()")[0].strip().split("'")[1],
"科目一": next_tree.xpath(f"""//tbody[@class="zsml-res-items"]/tr/td[1]/text()""")[0].strip(),
"科目二": next_tree.xpath(f"""//tbody[@class="zsml-res-items"]/tr/td[2]/text()""")[0].strip(),
"专业课一": next_tree.xpath(f"""//tbody[@class="zsml-res-items"]/tr/td[3]/text()""")[0].strip(),
"专业课二": next_tree.xpath(f"""//tbody[@class="zsml-res-items"]/tr/td[4]/text()""")[0].strip()
}
self.all.append(tmp)
except IndexError:
"""说明页面无信息"""
break
return self.all # 返回列表 每个元素是一个字典
2.6 def GetPage(self):
此处我们对第一页面数据进行解析从而获得该该页面一共有多少页面
def GetPage(self):
"""获取页码"""
url = f"""https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm={self.params["ssdm"]}&dwmc={self.params["dwmc"]}&mldm={self.params["mldm"]}&mlmc={self.params["mlmc"]}&yjxkdm={self.params["yjxkdm"]}&zymc={self.params["zymc"]}&xxfs={self.params["xxfs"]}&pageno={self.params["pageno"]}"""
html = requests.get(url, headers=self.headers).content.decode("utf-8")
html = etree.HTML(html)
list = html.xpath('//ul[@class="ch-page"]/li')
page = len(list) - 2
return page
2.7 def WriterCsv(self):
该方法是将一个列表,列表的每个元素为一个字典的形式,存入一个表格。文章来源:https://www.toymoban.com/news/detail-821231.html
def WriterCsv(self):
"""存入CSV"""
data = pd.DataFrame(self.all)
data.to_csv(f"E:/PythonCode/yjy_select_school_plus/data.csv", index=False)
3 主程序
首先先获取高校名单列表和专业名单列表和专业代码列表,通过两层的遍历,获取每个高校,每个专业的详情数据。文章来源地址https://www.toymoban.com/news/detail-821231.html
file_school = "school"
file_code = "dm"
# 实例化对象
data = GetData()
# 获取专业代码
code_list = data.ReadTxt(file_code)
# 获取高校名单
school_list = data.ReadTxt(file_school)
for school in school_list:
for code in code_list:
x += 1
data.params['yjxkdm'] = code
data.params['dwmc'] = school
page = data.GetPage()
data.GetDeData(page=page)
data.WriterCsv()
print(f"第{x}次|{school}|{code}:over !!!")
if x % 7 == 0:
data.SleepTime()
4.完整代码如下
import random
from time import sleep
import pandas as pd
import requests
from lxml import etree # 导包
x = 0
class GetData():
def __init__(self):
# UA池
agent = [
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
]
# get请求所携带参数
self.params = {}
self.headers = {}
self.params['ssdm'] = 11 # 地区代码
self.params['dwmc'] = "" # 高校名称
self.params['mldm'] = ""
self.params['mlmc'] = ""
self.params['yjxkdm'] = "" # 专业代码
self.params['zymc'] = ""
self.params['xxfs'] = ""
self.params['pageno'] = ""
# UA伪装
self.headers["User-Agent"] = random.choice(agent)
# 用来存放页面所爬取的数据
self.all = []
def SleepTime(self):
"""
延迟方法
防止访问过快,服务器拒绝访问
"""
t = random.uniform(5, 10)
print(f'将延迟{t}s')
sleep(t)
def Getcode(self):
"""
获取专业代码
获取页面数据中所有专业代码
"""
url = "https://yz.chsi.com.cn/zsml/pages/getZy.jsp"
data_list = requests.get(url, headers=self.headers).json()
for data in data_list:
print(data['dm'])
fp = open(f"E:/PythonCode/yjy_select_school_plus/dm.txt", 'w', newline='', encoding='utf-8')
for i in range(len(data_list)):
tmp = data_list[i]['dm'] + '\n'
fp.write(tmp)
def ReadTxt(self, file):
"""读取txt"""
data = []
fp = open(f'E:/PythonCode/yjy_select_school_plus/{file}.txt', 'r', encoding='utf-8')
line = fp.readline().strip()
data.append(line)
while line:
line = fp.readline().strip()
data.append(line)
fp.close()
return data
def GetDeData(self, page):
"""获取详情"""
for page in range(1, page + 1):
self.params["pageno"] = f"{page}"
url = f"""https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm={self.params["ssdm"]}&dwmc={self.params["dwmc"]}&mldm={self.params["mldm"]}&mlmc={self.params["mlmc"]}&yjxkdm={self.params["yjxkdm"]}&zymc={self.params["zymc"]}&xxfs={self.params["xxfs"]}&pageno={self.params["pageno"]}"""
print(url)
data_xpath = requests.get(url.format(**self.params), headers=self.headers).content.decode("utf-8")
tree = etree.HTML(data_xpath)
for i in range(1, 31):
try:
next_url = tree.xpath(f"//tr[{i}]/td[8]/a/@href")[0]
next_url = f"https://yz.chsi.com.cn{next_url}"
next_data_xpath = requests.get(next_url, headers=self.headers).content.decode("utf-8")
next_tree = etree.HTML(next_data_xpath)
tmp = {
"学校": self.params["dwmc"],
"考试方式": tree.xpath(f"//tr[{i}]/td[1]/text()")[0],
"所在学院": tree.xpath(f"//tr[{i}]/td[2]/text()")[0],
"专业": tree.xpath(f"//tr[{i}]/td[3]/text()")[0],
"研究方向": tree.xpath(f"//tr[{i}]/td[4]/text()")[0],
"学习方式": tree.xpath(f"//tr[{i}]/td[5]/text()")[0],
"招生人数": tree.xpath(f"//tr[{i}]/td[7]/script/text()")[0].strip().split("'")[1],
"备注": tree.xpath(f"//tr[{i}]/td[9]/script/text()")[0].strip().split("'")[1],
"科目一": next_tree.xpath(f"""//tbody[@class="zsml-res-items"]/tr/td[1]/text()""")[0].strip(),
"科目二": next_tree.xpath(f"""//tbody[@class="zsml-res-items"]/tr/td[2]/text()""")[0].strip(),
"专业课一": next_tree.xpath(f"""//tbody[@class="zsml-res-items"]/tr/td[3]/text()""")[0].strip(),
"专业课二": next_tree.xpath(f"""//tbody[@class="zsml-res-items"]/tr/td[4]/text()""")[0].strip()
}
self.all.append(tmp)
except IndexError:
"""说明页面无信息"""
break
return self.all # 返回列表 每个元素是一个字典
def GetPage(self):
"""获取页码"""
url = f"""https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm={self.params["ssdm"]}&dwmc={self.params["dwmc"]}&mldm={self.params["mldm"]}&mlmc={self.params["mlmc"]}&yjxkdm={self.params["yjxkdm"]}&zymc={self.params["zymc"]}&xxfs={self.params["xxfs"]}&pageno={self.params["pageno"]}"""
html = requests.get(url, headers=self.headers).content.decode("utf-8")
html = etree.HTML(html)
list = html.xpath('//ul[@class="ch-page"]/li')
page = len(list) - 2
return page
def WriterCsv(self):
"""存入CSV"""
data = pd.DataFrame(self.all)
data.to_csv(f"E:/PythonCode/yjy_select_school_plus/data.csv", index=False)
file_school = "school"
file_code = "dm"
# 实例化对象
data = GetData()
# 获取专业代码
code_list = data.ReadTxt(file_code)
# 获取高校名单
school_list = data.ReadTxt(file_school)
for school in school_list:
for code in code_list:
x += 1
data.params['yjxkdm'] = code
data.params['dwmc'] = school
page = data.GetPage()
data.GetDeData(page=page)
data.WriterCsv()
print(f"第{x}次|{school}|{code}:over !!!")
if x % 7 == 0:
data.SleepTime()
到了这里,关于爬虫学习记录之Python 爬虫实战:爬取研招网招生信息详情的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!