1.引言
标准化降水指数(SPI)是一个广泛使用的指数,用于描述一系列时间尺度上的气象干旱的特征。但是经过研究发现,目前的处理方法基本都是单点进行计算,缺少多点(大区域)的批量计算过程。因此本博客从气象数据下载,处理成NC格式文件以及依靠climate indices库完成多点的SPI指数计算,并可以在ARCGIS中利用反距离权重生成指数SPI栅格数据。本文有博主整理的完成Python代码资源以及样例数据。

2.SPI原理概述
SPI计算原理是将某时间尺度(如1、3、6、12个月等)降水量的连续时间序列(最好是长期记录,一般最少30年)看作服从某种概率密度函数分布(如gamma分布),然后推导出相应的累积概率函数,再通过累积概率函数转换为标准正态分布。转换之后,某时间尺度样本的SPI为:该样本降水量的累积概率所对应的标准正态分布的x轴的值。
例如:以3个月为时间尺度,使用1981-2010年30年的降水数据。计算2010年1月的SPI值。因为时间尺度是3个月,所以2010年1月的累积降水量被定义为2009年11月-2010年1月期间的总降水量,记作P;使用的时间序列为往年同期的降水量数据,即各年11月-1月的降水。首先按照原理,将时间序列数据假设为满足gamma分布g(x),然后推导其累积概率函数H(x),再转换为标准正态分布。然后,查找P对应的累积概率H(P),然后查找与H(P)相同累积概率的标准正态分布所对应的x轴的值,即为SPI。示意图如下,左图为累积概率H(x),右图为转换之后的标准正态分布。

图1 从虚线伽马分布到标准正态分布的等概率变换的例子
详细的数学原理请参考博客
3.技术方法
3.1 气象数据下载
首先,我们需要下载30年某一区域的降水数据。因为长时间序列数据一般来说不太好获取,博主使用的是NASA POWER提供的气象数据,是免费的。
网站:NASA POWER | Data Access Viewer
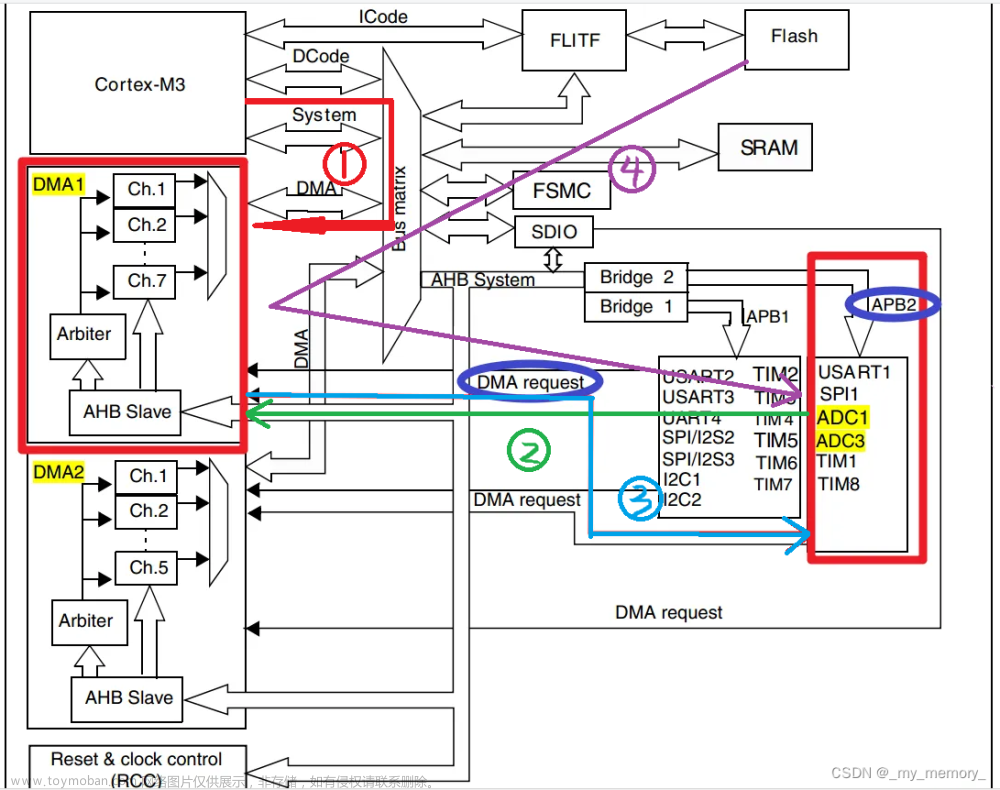
- 入下图所示,我们选择东北的区域的数据,时间范围为:1992-2022。因为选择的是月度数据,网站只更新到1992-2020,后面2021与2022只能下载日度的数据进行累积后处理。(文尾提供Python代码与样例气象数据,1_merge_daily_precipitation.py)

图2 NASA POWER VIEWER 网站页面
- 下图为博主下载的区域气象数据,格式为csv,打开可以看到。数据其实是按照经度纬度各网点排列的,因为NASA提供的是0.5°×0.5°的分辨率数据,所以整个吉林省为20×12个点。列JAN-DEC为每个月的降水数据。

- 需要注意的是,因为2021与2022为日度数据所以需要进行自己累积计算,算完后合并到1992-2020中即可。
j2022=r"raw_data\jilinday2022.csv"
weather_table = pd.read_csv(j2022)
IS_ALL_Month=False
if IS_ALL_Month:
out_dic={"PARAMETER":[],"YEAR":[],"LAT":[],"LON":[],"1":[],"2":[],"3":[],"4":[],"5":[],"6":[],"7":[],
"8":[],"9":[],"10":[],"11":[],"12":[]}
else:
out_dic={"PARAMETER":[],"YEAR":[],"LAT":[],"LON":[],"1":[],"2":[],"3":[],"4":[],"5":[],"6":[],"7":[],
"8":[]}
weather_table=weather_table.set_index(['LAT', 'LON','MO'])
for y in (weather_table.index.get_level_values(0).unique()):#纬度方向
data_y=weather_table[(weather_table.index.get_level_values(0) == y)]
for x in (data_y.index.get_level_values(1).unique()):#经度方向
data_yx=data_y[(data_y.index.get_level_values(1) == x)]
for month in (data_yx.index.get_level_values(2).unique()):
data_month = data_yx[(data_yx.index.get_level_values(2) == month)]
out_dic[str(month)]=out_dic[str(month)]+[np.sum(data_month["PRECTOTCORR"].values)]
#循环日累加
out_dic["PARAMETER"]=out_dic["PARAMETER"]+["PRECTOTCORR_SUM"]
out_dic["YEAR"]=out_dic["YEAR"]+[2022]
out_dic["LAT"]=out_dic["LAT"]+[y]
out_dic["LON"]=out_dic["LON"]+[x]
df_out=pd.DataFrame(out_dic)
df_out.to_csv(r"process_data\jilin2022.csv",index=False)3.2 安装 climate indices库
本博客在计算SPI指数时候需要安装climate indices库。
climate indices 是由James Adams利用Python开发的一个计算各种气象指数,包括SPEI, SPI, PET, PDSI, scPDSI的库,可以使用pip install 来安装该库。
在cmd 中启动python,导入climate_indices库,如果没提示错误,则表示安装成功。

同时,在python\Scripts 文件夹中会生成这个process_climate_indices.exe,后面批处理主要依靠这个exe。

注意:如果按照报错,可以使用文尾资源中的lib\climate_indices-py3.8.whl文件按照,这个已经让地理所老师重新编译,适用于window10-11,python3.8环境。
3.3 转换NC气象格式数据
因为想要使用climate indices,输入数据必须为nc格式的数据,因此我们必须要将处理得到的xlsx降水数据生成nc文件(2_write_ncfile.py)。
#---netcdf foramt---#
f_w = nc.Dataset(outpath,'w',format = 'NETCDF4')
f_w.createDimension('time',times)
f_w.createDimension('lat',y_size)
f_w.createDimension('lon',x_size)
##创建变量。参数依次为:‘变量名称’,‘数据类型’,‘基础维度信息’
time=f_w.createVariable('time',"S19",('time'))
for i in range(times):
#time[i] = data_serise[i].strftime('%Y-%m-%d')
time[i] = data_serise[i].strftime('%Y-%m-%d %H:%M:%S')
time.units = 'times since {0:s}'.format(time[0])
time.standard_name = 'Time'
time.axis = 'T'
f_w.createVariable('lat',np.float32,('lat'))
f_w.createVariable('lon',np.float32,('lon'))
#t=np.linspace(0,times-1,times,dtype=int)
lon=np.linspace(min_x,max_x,x_size,dtype=float)
lat=np.linspace(min_y,max_y,y_size,dtype=float)
#写入变量time的数据。维度必须与定义的一致。
#f_w.variables['time'][:]=data_serise#np.array(list_data)#data_serise
f_w.variables['lon'][:]=lon
f_w.variables['lat'][:]=lat
#xarray_data_r=np.transpose(xarray_data,(3,2,0,1))
#f_w.createVariable( "prcp", np.float32, ('time','lat','lon'),fill_value=fill_value)
f_w.createVariable( "prcp", np.float32, ('lat','lon',"time"),fill_value=fill_value)
#f_w.variables["prcp"][:]=xarray_data_r[0]
f_w.variables["prcp"][:]=xarray_data[:,:,:,0]
f_w.variables["prcp"].units="millimeter"
f_w.close3.4 运行批处理文件
看到这一步,我先恭喜大家,数据获取与处理确实不易。下一步就可以运行我们的批处理文件了(3_cal_SPIindex.py)。下面对其中的一些参数进行解释:
| 变量名称 | 含义 |
| index |
想要运行的指数名称,选择“spi” |
| periodicity |
周期,选择月度“monthly“ |
| netcdf_precip |
输入气象数据,nc格式 |
| var_name_precip |
字段名称,选择”prcp“ |
| output_file_base |
输出的spi的nc结果数据名称 |
| scales |
尺度,应该是跟gamma函数有关,选择3 |
| calibration_start_year |
开始年份 |
| calibration_end_year |
结束年份 |
| multiprocessing |
多进程处理,选择all |
3.5 转成ArcGIS可以导入的格式
运行完3.4后,可以生成后缀为nc_spi_gamma_03.nc与nc_spi_pearson_03.nc格式的结果文件,运行4_SPI2xlsx.py文件,可以转成excel文件,导入arcgis结果如下:

4.结果展示
4.1 SPI 点位结果展示
如下图所示,这是通过我们批处理计算得到的吉林省多点的SPI点状数据:

4.2 生成整个区域面状结果
这里我们需要在4.1的基础上,结合ArcGIS工具中的Spatial Analyst tools /Interpolation/IDW插值得到插值栅格影像。

其中分辨率那一栏,可以根据需求自己设置,需要注意的是这里的分辨率单位是°,不是米。插值结果如下:
 文章来源:https://www.toymoban.com/news/detail-821797.html
文章来源:https://www.toymoban.com/news/detail-821797.html
4.3 写在最后
完整资源和样例数据地址如下https://download.csdn.net/download/u010329292/88291585:需要的小伙伴可以供下载学习:)文章来源地址https://www.toymoban.com/news/detail-821797.html
到了这里,关于基于Python的大区域SPI标准降水指数自动批量化处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!