一 linux 文本操作数据过滤使用实例
示例:查找行内容包含“6883”标识的的行,并且提取68开头的数据,如下图
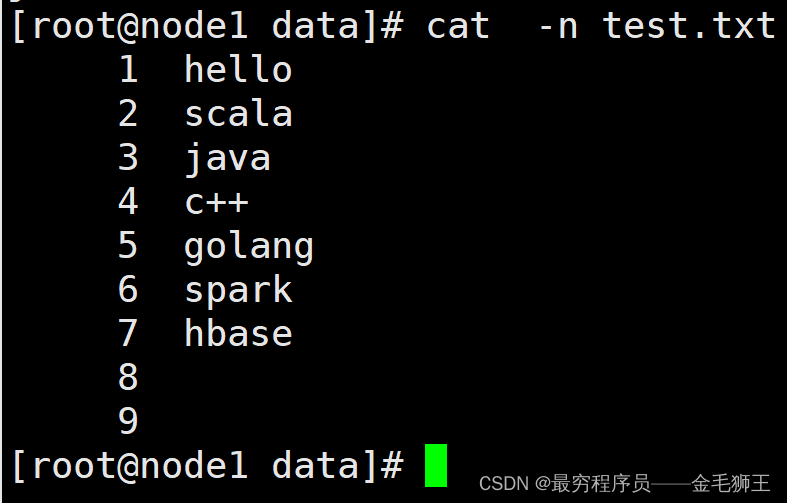
原始数据日记文件,有些有6883,有些没有8383标识,如下:

第一步:使用 grep 过虑数据
使用 grep 过虑数据每行带有 “6883” 标识的数据:
grep 6883 dev_info.2024-01-21.3 > 832.txt 
执行后如下图,新的文本已过虑掉没有6883的数据,每行都有6883

第二步:使用awk提取数据
使用awk 提取每行68开头的数据,先分析一下数据的结构发现以68开头的是最后一列,可以使用以下指令
awk -F',' '{print $NF}' 831.txt > 8311.txt
使用awk去重复的行数据
awk '!seen[$0]++' 8311.txt > 8322_.txt
执行awk '!seen[$0]++' 8311.txt > 8322_.txt 后会去重复的行数据并生成新的文件8322_.txt的文件如下:

到此完成得到标识6883则不重数据的数据。
二 grep详细介绍
grep 是 Linux 系统中的一个强大的文本搜索工具,它可以用于在文件或标准输入流中查找符合指定模式的字符串。grep 的一般格式如下:
grep [选项] 模式 文件...文章来源地址https://www.toymoban.com/news/detail-821949.html
其中,模式 是指定要查找的字符串或正则表达式,文件 是指定要搜索的文件。
grep 支持多种选项,用于控制搜索的行为。以下是一些常用的选项:
- -i:忽略大小写。
- -v:反向查找,只显示不包含模式的所有行。
- -n:显示匹配行的行号。
- -r:递归搜索子目录中的文件。
- -l:只显示匹配的文件名。
- -c:只显示匹配的行数。
以下是一些 grep 的使用示例:
# 查找文件中包含 "hello" 的行
grep "hello" file
# 查找文件中包含 "hello" 或 "world" 的行
grep -e "hello" -e "world" file
# 查找文件中包含 "hello" 的行,并显示行号
grep -n "hello" file
# 查找文件中包含 "hello" 的行,并显示匹配的文件名
grep -l "hello" file
# 查找文件中包含 "hello" 的行,并显示匹配的行数
grep -c "hello" file
grep 还支持正则表达式,这使得它可以用于更复杂的搜索。例如,以下命令将查找文件中包含至少一个数字的行:
grep -e '[0-9]' file
grep 是一个非常强大的工具,它可以用于各种文本搜索任务。通过了解 grep 的使用方法,您可以更有效地管理您的 Linux 系统。
以下是一些 grep 的进阶用法:
- 使用管道:grep 可以与其他命令结合使用,以实现更复杂的功能。例如,以下命令将查找文件中包含 "hello" 的行,并将其保存到另一个文件中:
grep "hello" file | tee new_file
- 使用正则表达式:grep 支持正则表达式,这使得它可以用于更复杂的搜索。例如,以下命令将查找文件中以 "hello" 开头的行:
grep "^hello" file
- 使用边界字符:grep 支持边界字符,这使得它可以用于更精确的搜索。例如,以下命令将查找文件中以 "hello" 开头,以空格结尾的行:
grep "^hello\s" file
- 使用后置处理器:grep 支持后置处理器,这使得它可以用于将搜索结果进行进一步处理。例如,以下命令将查找文件中包含 "hello" 的行,并将其替换为 "world":
grep "hello" file | sed -e "s/hello/world/g"
通过了解 grep 的进阶用法,您可以充分利用 grep 的强大功能。
三 awk详细介绍
awk 是一个强大的文本处理工具,它可以用于在文件中查找、提取和转换数据。awk 的一般格式如下:
awk [选项] 表达式 文件...
其中,表达式 是指定要查找、提取或转换的规则,文件 是指定要处理的文件。
awk 支持多种选项,用于控制处理的行为。以下是一些常用的选项:
- -F:指定域分隔符,默认为空格。
- -f:指定要使用的 awk 脚本文件。
- -v:指定变量。
以下是一些 awk 的使用示例:
# 查找文件中包含 "hello" 的行
awk '{ if ($0 ~ /hello/) print $0 }' file
# 提取文件中每行的第一个域
awk '{ print $1 }' file
# 将文件中每行的第一个域和第二个域合并为一个字符串
awk '{ print $1" "$2 }' file
# 将文件中每行的第一个域替换为 "world"
awk '{ $1 = "world" }' file
awk 还支持正则表达式,这使得它可以用于更复杂的处理。例如,以下命令将查找文件中以 "hello" 开头,以空格结尾的行:
awk '{ if ($0 ~ /^hello\s/) print $0 }' file
awk 是一个非常强大的工具,它可以用于各种文本处理任务。通过了解 awk 的使用方法,您可以更有效地处理文本数据。
以下是一些 awk 的进阶用法:
- 使用管道:awk 可以与其他命令结合使用,以实现更复杂的功能。例如,以下命令将查找文件中包含 "hello" 的行,并将其保存到另一个文件中:
awk '{ if ($0 ~ /hello/) print $0 }' file | tee new_file
- 使用后置处理器:awk 支持后置处理器,这使得它可以用于将处理结果进行进一步处理。例如,以下命令将查找文件中包含 "hello" 的行,并将其替换为 "world":
awk '{ if ($0 ~ /hello/) print $0 | sed -e "s/hello/world/g" }' file
- 使用 awk 脚本:awk 脚本可以用于实现更复杂的处理逻辑。例如,以下 awk 脚本将查找文件中包含 "hello" 的行,并将其替换为 "world":
BEGIN { FS = "\t" }
{
if ($1 == "hello") {
$1 = "world"
}
print $0
}
通过了解 awk 的进阶用法,您可以充分利用 awk 的强大功能。文章来源:https://www.toymoban.com/news/detail-821949.html
到了这里,关于linux 文本操作-数据过滤(grep,awk 使用)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!