在 Redis 中,集合和有序集合的区别是什么?它们适用于什么场景?
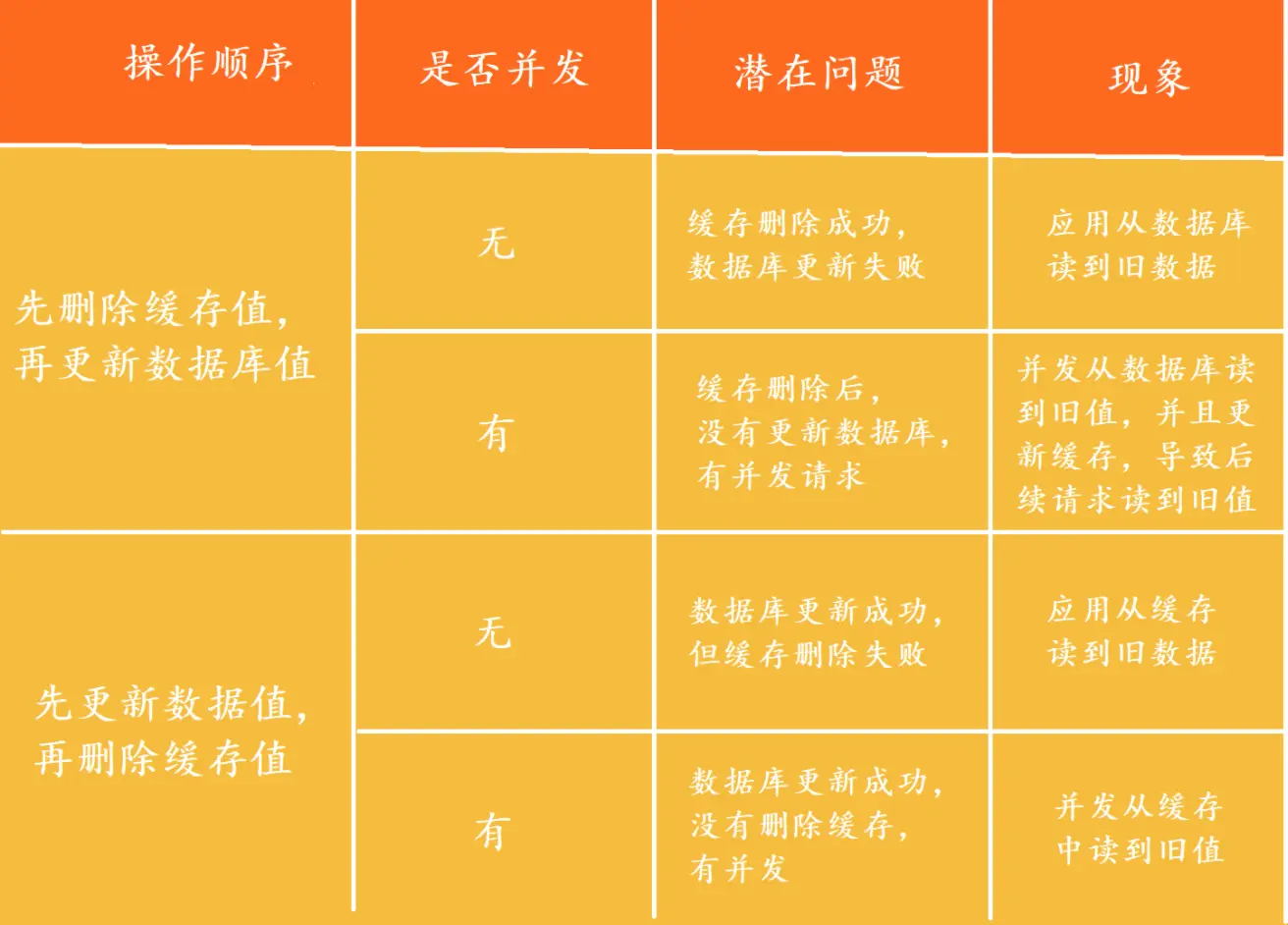
答:Redis 中的集合(Set)和有序集合(Sorted Set)是两种不同的数据结构,它们的区别如下:
集合(Set)是无序的字符串集合,不允许重复的元素。集合类似于数学上的集合,可以进行集合间的交集、并集、差集等操作。集合的操作复杂度为 O(1)。
有序集合(Sorted Set)也是字符串的集合,每个元素关联一个分数(score)。与集合不同的是,有序集合的元素按照分数进行排序,且每个元素在集合中具有唯一性。有序集合的操作复杂度为 O(logN)。
根据其特点,集合和有序集合适用于不同的场景:
集合适合用于存储一组唯一的元素,并进行快速的集合操作,如求交集、并集、差集等。常见的应用场景有唯一标签的存储、用户的好友列表等。
有序集合适合存储元素与分数之间的关联关系,并按照分数进行排序。可以应用于排行榜、优先级队列、范围查询等场景。例如,可以用有序集合存储网站的文章热度,并按热度进行排行。
需要注意的是,集合和有序集合不仅仅可以存储字符串,也可以存储数字等其他数据类型。根据不同的需求,选择合适的数据结构可以提高数据的查询和处理效率。
当然,请继续提问。
Redis 缓存穿透是什么问题?如何解决缓存穿透问题?
答:Redis 缓存穿透是指当一个请求访问一个不存在于缓存中的数据时,导致请求直接访问数据库,而不经过缓存层。缓存穿透问题可能会导致数据库负载过大,降低系统性能。
缓存穿透问题的解决方法如下:
布隆过滤器(Bloom Filter):布隆过滤器是一种数据结构,用于判断一个元素是否存在于集合中。可以把缓存中不存在的数据的查询请求先经过布隆过滤器进行过滤,如果不在布隆过滤器中,就可以直接返回缓存未命中,避免请求直接访问数据库。
缓存空对象(Cache Null Object):当一个数据在数据库中不存在时,可以把该查询结果设置为空对象,并将其缓存起来。这样在下次查询时,即使用户再次请求同样的不存在的数据,也可以从缓存中返回空对象,避免直接访问数据库。
热点数据预加载(Preloading Hot Data):针对一些经常被查询的热点数据,在系统启动时或者低峰期提前加载到缓存中,保证缓存中存在这部分数据,从而避免缓存穿透问题。
限流(Rate Limiting):对请求进行限流,设置适当的并发访问数、访问频率等限制,可以减轻缓存穿透带来的影响。
应用层验证(Application Layer Validation):在接收到请求后,可以在应用层对请求参数进行校验,只有符合规则的请求才会继续访问缓存或者数据库。这样可以过滤掉一些非法请求,减少对缓存和数据库的无效查询。
综合使用以上的方法,可以有效地解决缓存穿透问题,提高系统的性能和稳定性。
缓存雪崩是什么问题?如何预防和解决缓存雪崩问题?
答:缓存雪崩是指大量缓存数据在同一时间失效,导致大量请求直接访问数据库,造成数据库压力过大,甚至引起数据库崩溃的现象。主要原因是缓存数据过期时间设置相同或接近,并且在同一时间突然失效。
预防和解决缓存雪崩问题的方法如下:
设置不同的过期时间(过期时间分散):将缓存的过期时间设置为不同的值,避免同时大量数据过期。可以在数据插入到缓存时,随机生成一个过期时间,使得缓存数据的过期时间分散。
使用热点数据永不过期:对于一些热点数据,可以将其过期时间设置为永不过期。这样即使其他缓存发生失效,热点数据仍然可以继续提供服务。
限流和降级:对请求进行限流,设置适当的并发访问数、访问频率等限制,以减小对缓存和数据库的并发请求压力。同时,对于一些非核心的功能或非重要的数据,可以进行降级处理,例如返回默认值或固定的数据,以保证系统的稳定性。
实时监控和预警:及时监控缓存的状态和使用情况,当发现缓存命中率明显下降或者缓存过期时间集中失效时,预警并及时调整缓存策略,避免出现雪崩效应。
多级缓存架构:采用多级缓存架构,将缓存分为多层,如本地缓存、分布式缓存等,每一层都设置不同的过期时间和容量,以提高系统的可用性和容错性。文章来源:https://www.toymoban.com/news/detail-821953.html
通过以上方法的综合应用,可以有效预防和解决缓存雪崩问题,提高系统的稳定性和可靠性。文章来源地址https://www.toymoban.com/news/detail-821953.html
到了这里,关于Redis面试题27的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!