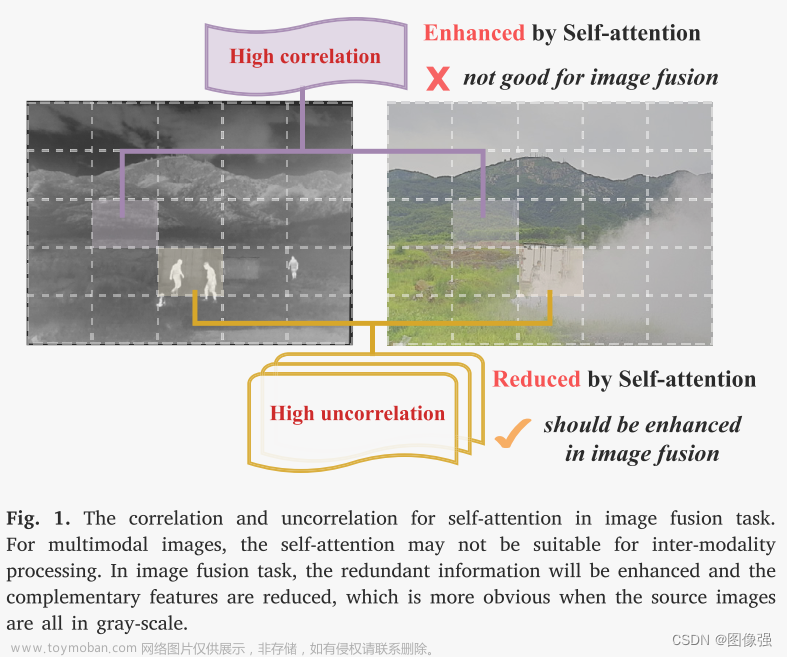
@article{bai2023refusion,
title={ReFusion: Learning Image Fusion from Reconstruction with Learnable Loss via Meta-Learning},
author={Bai, Haowen and Zhao, Zixiang and Zhang, Jiangshe and Wu, Yichen and Deng, Lilun and Cui, Yukun and Xu, Shuang and Jiang, Baisong},
journal={arXiv preprint arXiv:2312.07943},
year={2023}
}
| 论文级别:arXiv |
| 影响因子:- |
📖[论文下载地址]
💽[代码下载地址:暂无]
作者在摘要中写了The code will be released.但是我目前没有找到,有code的同学可以踢我一脚。
📖论文解读
首先我想说,这篇论文的题目好难翻译呀……也不知道翻译的对不对,好多个“学习”
基于深度学习的图像融合的一个主要挑战就是缺乏明确的ground truth和距离测度。因此需要手动设计损失函数以及相应的超参数,从而限制了模型的灵活性和泛化性。
为了解决这个问题,作者提出了ReFusion的统一的基于元学习的图像融合模型,该模型从重建源图像中学习最佳的融合损失。
ReFsuion由融合模块,损失提议模块(loss proposal module)以及重构模块构成。
采用参数化损失函数,该损失函数由损失建议模块根据特定的融合场景和任务动态调整。
使用元学习策略使重建损失不断细化损失建议模块的参数。自适应更新是通过内部更新、外部更新和融合更新之间的交替来实现的,其中三个组件的训练相互促进。
🔑关键词
图像融合,元学习
💭核心思想
基于元学习的思想,设计了一个可学习的自适应融合损失函数
🪅相关背景知识
- 深度学习
- 神经网络
- 图像融合
- 元学习
扩展学习
[什么是图像融合?(一看就通,通俗易懂)]
[一文通俗讲解元学习(Meta-Learning)]
[一文入门元学习(Meta-Learning)(附代码)]
🪢网络结构
作者提出的网络结构如下所示。
I
a
I_a
Ia、
I
b
I_b
Ib和
I
f
I_f
If分别表示源图像以及融合图像
I
^
a
\hat I_a
I^a和
I
^
b
\hat I_b
I^b分别表示重构的源图像
如下图所示,ReFusion由三个模块构成:
F
(
⋅
)
\mathcal F(·)
F(⋅)是融合模块
R
(
⋅
)
\mathcal R(·)
R(⋅)是重构模块
P
(
⋅
)
\mathcal P(·)
P(⋅)是损失提议模块
其参数分别用
θ
F
\theta_\mathcal F
θF、
θ
R
\theta_\mathcal R
θR、
θ
P
\theta_\mathcal P
θP表示
L
f
\mathcal L_f
Lf表示可学习的参数化融合损失
L
r
\mathcal L_r
Lr表示重构损失,该损失不参与融合模块的更新
三个交替的学习阶段分别由下组成:
红色:内部更新采用当前提案融合损失
蓝色:外部更新利用重建损失来衡量内部更新的效果,并优化损失提案模块
绿色:在融合和重建更新阶段,融合模块根据提案的融合损失进行更新,重建模块也相应更新
简单的介绍完了,接下来让我们看看网络结构图。
和上面说的一样,红绿蓝三个模块交替学习
可学习的融合损失函数由损失提议模块
P
\mathcal P
P生成的两个独立输出对构成,每对与源图像维度相同。
这些“对”是根据源图像及其梯度计算的:
{
[
W
a
,
W
b
]
,
[
V
a
,
V
b
]
}
=
P
(
I
a
,
I
b
,
∇
I
a
,
∇
I
b
)
\{[W_a,W_b], [V_a, V_b]\}=\mathcal P(I_a, I_b, ∇I_a, ∇I_b)
{[Wa,Wb],[Va,Vb]}=P(Ia,Ib,∇Ia,∇Ib)
其中,
W
a
i
j
+
W
b
i
j
=
1
W_a^{ij}+W_b^{ij}=1
Waij+Wbij=1,
V
a
i
j
+
V
b
i
j
=
1
V_a^{ij}+V_b^{ij}=1
Vaij+Vbij=1,∇是sobel operator,计算梯度的
扩展学习
sobel operator
可学习的融合损失公式如下:
融合损失=强度损失+参数×梯度损失

W
a
i
j
W_a^{ij}
Waij和
W
b
i
j
W_b^{ij}
Wbij指示了损失函数对于每个源图像强度信息的偏好,即强度权重
V
a
i
j
V_a^{ij}
Vaij 和
V
b
i
j
V_b^{ij}
Vbij 指示了损失函数对于每个源图像梯度信息的偏好,即梯度权重
重构损失的公式如下:
重构损失=强度损失+参数×梯度损失
融合训练数据集
{
I
a
f
t
r
,
I
b
f
t
r
}
\{I_a^{ftr}, I_b^{ftr}\}
{Iaftr,Ibftr}划分为两个子集:
元训练集
{
I
a
m
t
r
,
I
b
m
t
r
}
\{I_a^{mtr}, I_b^{mtr}\}
{Iamtr,Ibmtr}
元测试集
{
I
a
m
t
s
,
I
b
m
t
s
}
\{I_a^{mts}, I_b^{mts}\}
{Iamts,Ibmts}
📉损失函数
上节已介绍
🔢数据集
- MSRS
- RoadScene
图像融合数据集链接
[图像融合常用数据集整理]
🎢训练设置
我们看这个过程,首先需要元训练集,对应模型总图的①,元测试集,对应②,以及融合训练集对应③。最终的输出是融合图像
I
f
I_f
If
🎢①内部更新
在内部更新阶段,希望使用提议损失
P
\mathcal P
P的当前状态定义的融合损失来更新
F
\mathcal F
F
输入元训练集
{
I
a
m
t
r
,
I
b
m
t
r
}
\{I_a^{mtr}, I_b^{mtr}\}
{Iamtr,Ibmtr},融合网络
F
\mathcal F
F通过梯度下降进行单次更新:
W和V是
P
\mathcal P
P的当前输出,使用融合损失作为参数。
η
F
′
\eta_{F^{\prime}}
ηF′代表用于更新融合模块的步长
F
′
{\mathcal F^{\prime}}
F′是
F
\mathcal F
F的临时代替,相当于自增自减的一个临时变量
同理,重建模块
R
\mathcal R
R的更新一样:
🎢②外部更新
外部更新的主要目标是细化损失建议模块
P
\mathcal P
P,通俗点来说,就是为了增强由损失函数
L
f
\mathcal L_f
Lf指导的 融合模块
F
\mathcal F
F 的有效性
在上一步中,内部更新的
F
′
{\mathcal F^{\prime}}
F′和
R
′
{\mathcal R^{\prime}}
R′体现了当前的教学能力(instructional capacity)
在此步骤中,利用元测试集
{
I
a
m
t
s
,
I
b
m
t
s
}
\{I_a^{mts}, I_b^{mts}\}
{Iamts,Ibmts},基于重建损失
L
r
\mathcal L_r
Lr更新参数
θ
P
\theta_\mathcal P
θP,这里重建损失
L
r
\mathcal L_r
Lr是由
F
′
{\mathcal F^{\prime}}
F′和
R
′
{\mathcal R^{\prime}}
R′计算得到的:

更新后的损失建议模块
P
\mathcal P
P被细化,可以提议效果更好的融合损失函数
🎢③融合及重构更新
使用
F
\mathcal F
F的当前状态提升
P
\mathcal P
P,反过来细化后的
P
\mathcal P
P被进一步用来训练
F
\mathcal F
F
此步骤输入融合训练数据集
{
I
a
f
t
r
,
I
b
f
t
r
}
\{I_a^{ftr}, I_b^{ftr}\}
{Iaftr,Ibftr}
通过融合损失
L
f
\mathcal L_f
Lf和重构损失
L
r
\mathcal L_r
Lr来更新
F
\mathcal F
F和
R
\mathcal R
R
具体算法伪代码为:
在一个epoch内,嵌套了两个循环
第一个循环内部是:
- ①内部更新:应用
P
\mathcal P
P
- 从元训练集 { I a m t r , I b m t r } \{I_a^{mtr}, I_b^{mtr}\} {Iamtr,Ibmtr}中采样图像对
- 计算相应的 { I f m t r , I ^ a m t r , I ^ b m t r } \{I_f^{mtr}, \hat I_a^{mtr}, \hat I_b^{mtr}\} {Ifmtr,I^amtr,I^bmtr}
- 根据公式7和8,计算 θ F ′ \theta_{ \mathcal F^{\prime}} θF′以及 θ R ′ \theta_{ \mathcal R^{\prime}} θR′
- ②外部更新:优化
P
\mathcal P
P
- 从元测试集 { I a m t s , I b m t s } \{I_a^{mts}, I_b^{mts}\} {Iamts,Ibmts}中采样图像对
- 计算相应的 { I f m t s , I ^ a m t s , I ^ b m t s } \{I_f^{mts}, \hat I_a^{mts}, \hat I_b^{mts}\} {Ifmts,I^amts,I^bmts}
- 根据公式8更新 θ p \theta_p θp
第二个循环内部是:
- 融合及重构更新:优化
F
\mathcal F
F和
R
\mathcal R
R
- 从融合训练数据集 { I a f t r , I b f t r } \{I_a^{ftr}, I_b^{ftr}\} {Iaftr,Ibftr}采样图像对
- 计算相应的 { I f f t r , I ^ a f t r , I ^ b f t r } \{I_f^{ftr}, \hat I_a^{ftr}, \hat I_b^{ftr}\} {Ifftr,I^aftr,I^bftr}
- 根据公式11和12,更新 θ F \theta_\mathcal F θF和 θ R \theta_\mathcal R θR
然后进行下一个epoch的循环
🔬实验
📏评价指标
- EN
- SD
- SF
- AG
- SCD
- SSIM
扩展学习
[图像融合定量指标分析]
🥅Baseline
- SDNet、TarDAL、Defusion、MetaFusion、CDDFuse、LRRNet、MURF、DDFM、SegMIF
✨✨✨扩展学习✨✨✨
✨✨✨强烈推荐必看博客[图像融合论文baseline及其网络模型]✨✨✨
🔬实验结果



更多实验结果及分析可以查看原文:
📖[论文下载地址]
🧷总结体会
这篇论文很复杂…我看的也不是太懂,而且也没有找到代码。不过开阔了眼界,transformer+元学习+图像融合的组合很神奇
🚀传送门
📑图像融合相关论文阅读笔记
📑[YDTR: Infrared and Visible Image Fusion via Y-Shape Dynamic Transformer]
📑[CS2Fusion: Contrastive learning for Self-Supervised infrared and visible image fusion by estimating feature compensation map]
📑[CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach]
📑[(DIF-Net)Unsupervised Deep Image Fusion With Structure Tensor Representations]
📑[(MURF: Mutually Reinforcing Multi-Modal Image Registration and Fusion]
📑[(A Deep Learning Framework for Infrared and Visible Image Fusion Without Strict Registration]
📑[(APWNet)Real-time infrared and visible image fusion network using adaptive pixel weighting strategy]
📑[Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models]
📑[Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion]
📑[LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images]
📑[(DeFusion)Fusion from decomposition: A self-supervised decomposition approach for image fusion]
📑[ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion]
📑[RFN-Nest: An end-to-end resid- ual fusion network for infrared and visible images]
📑[SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images]
📑[SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer]
📑[(MFEIF)Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion]
📑[DenseFuse: A fusion approach to infrared and visible images]
📑[DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pair]
📑[GANMcC: A Generative Adversarial Network With Multiclassification Constraints for IVIF]
📑[DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion]
📑[IFCNN: A general image fusion framework based on convolutional neural network]
📑[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
📑[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
📑[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📑综述[Visible and Infrared Image Fusion Using Deep Learning]
📚图像融合论文baseline总结
📚[图像融合论文baseline及其网络模型]
📑其他论文
📑[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]文章来源:https://www.toymoban.com/news/detail-822080.html
🌻【如侵权请私信我删除】
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~文章来源地址https://www.toymoban.com/news/detail-822080.html
到了这里,关于图像融合论文阅读:ReFusion:通过元学习的从可学习损失重建中学习图像融合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!