前言
该论文的标定间比较高端,一旦四轮定位后,可确定标定板与车辆姿态。以下为本人理解,仅供参考。
工厂标定,可理解为车辆相关的标定,不涉及传感器间标定
该标定工具不依赖opencv;产线长度一般2.5米
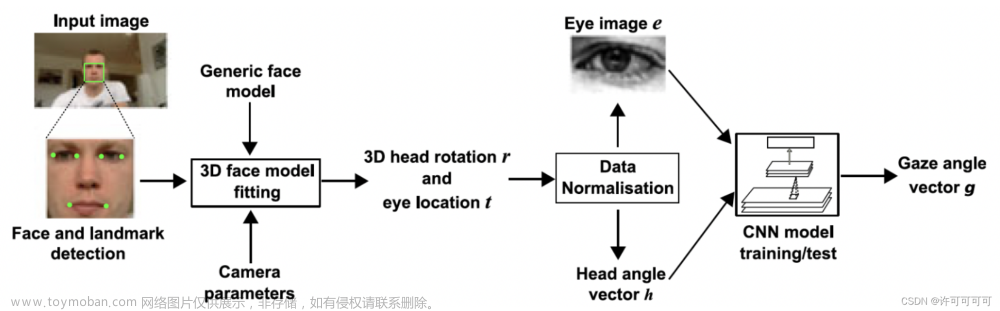
Factory Calibration Tools:四轮定位+多位姿标定板
1、Calibration Board Setup Tools
1)根据传感器安装位姿,生成标定板放置范围
2)检测当前环境标定板姿态是否合适
2、Calibration board detection:
1)标定线可使用5种类型标定板[chessboard, circle board, vertical board, aruco marker board, and round hole board]
2)chessboard
板子边沿设置为白色;选定初始化阈值进行自适应二值化图片检查,拓展到黑格子的四个角点;候选点,通过添加约束条件聚类获取角点;最后输出角点检测结果。
3)circle board
高精度,由于圆边沿的像素都会使用以减低图像噪点,保证了高精度
从二值化图片中提取圆:最大、最小边沿与轮廓中心距离满足一定阈值,则该轮廓判断为像素圆;
水平圆心连线通过Ransac算法与斜率实现[筛选条件:平行、半径接近、重投影重合、线段距离和半径距离限制]
4)vertical board
鲁棒性。灰度图获取角点,找三条通过角点的垂直线。对于每一条直线组合,将左右直线上的角点投影到中间的直线上,通过投影线上角点与图案特征之间的距离进行筛选和分割,得到正确的角点
5)aruco marker board
灰度图像二值化,邻域搜索候轮廓,轮廓受边数量约束;条件筛选获取四边形;过滤过于接近的四边形。然后,通过径向变换从四边形中提取外矩形,用 127 的阈值对图像进行去二值化处理,切割图像以获得二维码区域,并用 6*6 的网格划分二维码。根据二维码库获取码id,进而获取角点在标定板上位置
6) round hole board
轮廓匹配获取圆心,根据已知板子尺寸与孔尺寸信息,二维遍历进而匹配。标定板激光点云圆轮廓获取,提取图片标定板园轮廓,匹配算得外参。
3、相机标定
工厂标定:
需要:智驾产品正常运作前提是标定
一般标定条目:
相机标定包括校准灭点位置、相机到地面的单应矩阵计算,相机与车辆标定
工厂标定前,需要进行四轮定位
1)灭点标定:两条视觉平行线交点就是灭点。所寻找的消失点是与车身坐标平行的平行线的交点,那么灭点的计算方法就是相机通过标定板的一条线,并且这条线与车身保持平行。
2)camera与车辆标定:在出厂标定之前,需要对要标定的汽车进行四轮定位。四轮定位后,标定板板相对于车身中心的坐标被固定,然后使用相机识别标定板并进行标定。可以得到相机相对于车体坐标的姿态,这通常由 PnP 算法求解[个人未进行公式推导]
3)camera与地面标定:
A-VP与B-VP平行,纵坐标距离可根据距离公式获取,横坐标相同。根据ABCD四点的像素坐标与世界坐标系的关系,可算得相机到地面的单应矩阵[个人未进行公式推导]
距离公式计算参考:
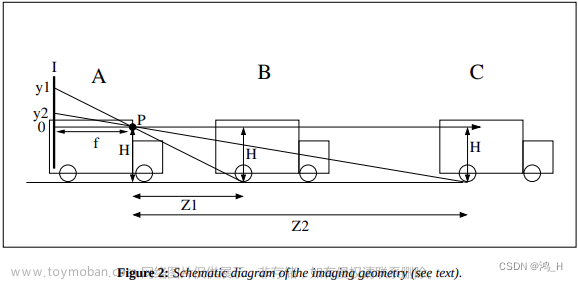
补充:上图基于针孔模型理解
4、lidar到车辆标定
已知标定板在车辆坐标系下的姿态[个人理解,采用百度类似标定房,四轮定位后,每块标定板姿态都是可知的],lidar也能测量出标定板在lidar坐标系下的姿态,那么根据公式:

残差函数:
那么,可以算得lidar到车辆的标定外参
资料来源:
OpenCalib: A Multi-sensor Calibration Toolbox for Autonomous Driving
Vision-based ACC with a Single Camera: Bounds on Range and Range Rate Accuracy文章来源:https://www.toymoban.com/news/detail-822103.html
#################
好记性不如烂笔头
积硅步期千里文章来源地址https://www.toymoban.com/news/detail-822103.html
到了这里,关于论文阅读1---OpenCalib论文阅读之factory calibration模块的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!