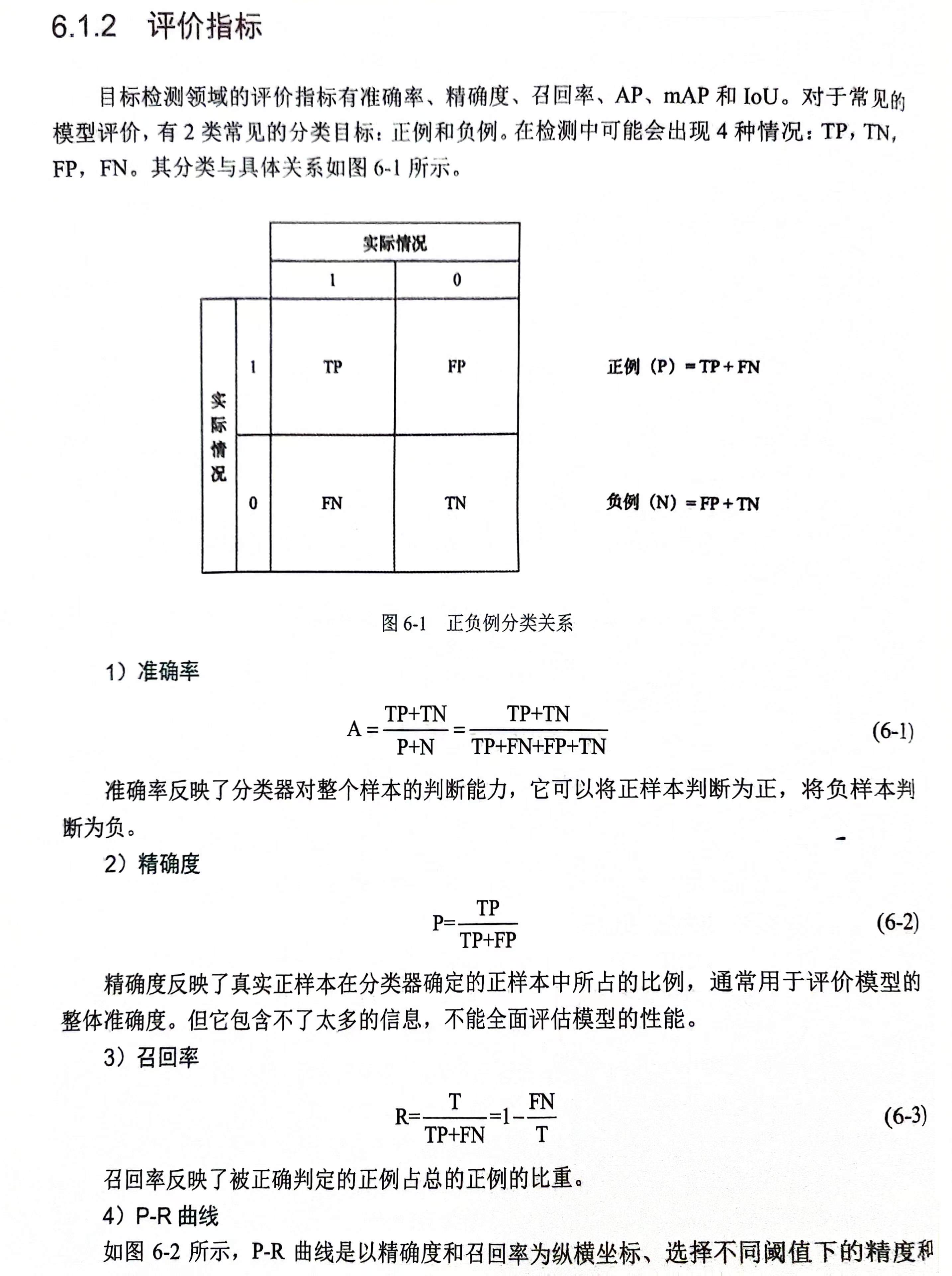
在真实世界的一个物体,可以通过相机矩阵将其投影到像素坐标系上
但是,在像素坐标系上的像素,由于相机的原理,导致它的深度信息已经没有了,所以原理上是没法得到其真实深度的(即3d位置)文章来源:https://www.toymoban.com/news/detail-822337.html
那么现在的深度学习方法又为什么能预测出物体的深度呢?
个人理解:
大概的过程就是:文章来源地址https://www.toymoban.com/news/detail-822337.html
- 通过图像可以预测物体的种类
- 通过物体的种类以及其他一些特征可以预测物体的尺寸
- 根据成像原理,真实物体通过小孔成像原理,投射到像素平面,真实物体的两个点+相机中心+图像上两个点构成两个相似三角形,知道了物体的尺寸,根据相似三角形原理,物体实际尺寸和像素尺寸的比例,是与真实深度和相机焦距的比例一致的,因此物体尺寸有了,就可以预测出深度距离了
如果真实物体的尺寸预测不准的话,大概率深度预测也不会准
到了这里,关于关于视觉3d目标检测学习像素深度的一点理解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!